
重回帰分析は偏回帰係数を求めて予測式(回帰式)を作り、標準化偏回帰係数の計算、回帰式の有意性の分散分析、決定係数の算出、偏回帰係数の検定、など行うが、実際どんな計算をしているのか?
実際どんな計算をしているかわかると、偏回帰係数や標準化偏回帰係数の意味合い、検定の意味合いがよりよく理解できると思う。

重回帰分析の第一目標は重回帰式を推定することである
重回帰分析の中心的な目標は、重回帰式を推定することである。
重回帰式は、単に回帰式と呼ばれることもある。
単変量でも多変量でもあまり区別しないということだ。
重が付く場合は、多変量を意識している。
以降は、重回帰式を、単に回帰式と表現する。
回帰式は、切片と呼ばれる定数と、各説明変数に掛け合わせる偏回帰係数と呼ばれる係数から構成される。
切片を $ \beta_0 $、説明変数が2つあるとすると、偏回帰係数は $ \beta_1 $, $ \beta_2 $と表すことが多い。
回帰式で予測される目的変数を $ \hat{Y} $, 説明変数はそれぞれ $ X_1 $, $ X_2 $ と表現すると、回帰式は以下のように書ける。
$$ \hat{Y} = \beta_0 + \beta_1 X_1 + \beta_2 X2 $$
$ Y $ と $ X $ は小文字で書かれることもある。
また $ \beta $ は $ b $ と書かれることもある。
標準化偏回帰係数を $ \beta $、(非標準化)偏回帰係数を $ b $ とか $ B $ と表現する場合や、統計ソフトウェアもある。
SPSSでは、非標準化偏回帰係数を B、標準化偏回帰係数をベータと表示し分けている。
また、厳密には、モデルの記述で、母集団のパラメータを意味しているときはギリシャ文字、推定値はアルファベットのようにかき分けたりもする。
この記事ではそこまで厳密にはかき分けずに進めることにする。
重回帰分析の計算方法 偏回帰係数
回帰式のうち、$ X $ は手元にあるデータである。
目的変数 $ Y $ も取得されている手元にあるデータである。
上記で登場した予測された目的変数(予測値)$ \hat{Y} $ は、回帰式で推定される、計算で求まる値である。
偏回帰係数 $ \beta $ も、計算によって求まる数値である。
回帰式は、実測の目的変数 $ Y $ になるべく近い予測値 $ \hat{Y} $ を算出するものが良い。
この「なるべく近い」というのが、実測値と予測値の差(これを残差と呼ぶ)$ Y – \hat{Y} $ がなるべく小さくすることを目標にするという意味になる。
なるべく小さくするときには、合計して合計値が一番小さいなどとしたいわけだが、残差はプラスもマイナスもあって、「小さい」というのがわかりにくい。
全部がプラス(正)であると大きい小さいがわかりやすい。
そこで、差を2乗して、全部を正にしてしまってから、合計する。
こうすると残差を最小にする条件を見出すことができる。
これが最小2乗法と呼ばれている方法だ。

重回帰分析の計算方法 最小2乗法
まず残差を2乗して合計する。
$$ Q = \sum (Y – \hat{Y})^2 $$
イメージをつかむための式と割り切り、単純化のため、添え字は極力省略している。
予測値 $ \hat{Y} $ には下記の式を代入する。
$$ \hat{Y} = \beta_0 + \beta_1 X_1 + \beta_2 X_2 $$
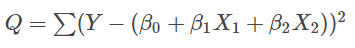
この式を $ \beta_0 $, $ \beta_1 $, $ \beta_2 $ に関して、偏微分して=0とおく。
2次式の1次微分が0となるときが最大値という意味である。
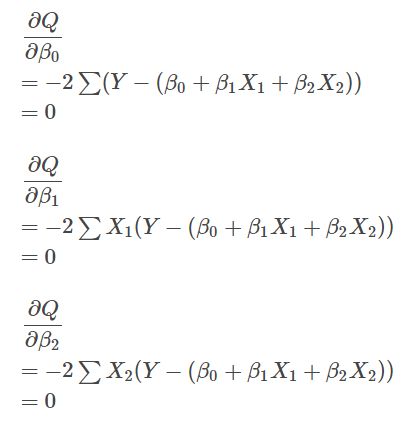
変数 $ Y $, $ X_1 $, $ X_2 $ の平均値を、$ \bar{Y} $, $ \bar{X_1} $, $ \bar{X_2} $ としたときの $ \beta_0 $ と、$ X_1 $, $ X_2 $ 間の変動・共変動 $ S_{11} $, $ S_{12} $, $ S_{21} $, $ S_{22} $、$ X_1 $, $ X_2 $ と $ Y $ の共変動 $ S_{1y} $, $ S_{2y} $ を以下のように表現すると、最終的に上記の偏微分の式が整理できる。
$$
\begin{array} {rcl}
\beta_0 &=& \bar{Y} – \beta_1 \bar{X_1} – \beta_2 \bar{X_2} \\
S_{11} &=& \sum (X_1 – \bar{X_1})^2 \\
S_{12} &=& \sum (X_1 – \bar{X_1}) (X_2 – \bar{X_2}) \\
S_{21} &=& \sum (X_2 – \bar{X_2}) (X_1 – \bar{X_1}) \\
S_{22} &=& \sum (X_2 – \bar{X_2})^2 \\
S_{1y} &=& \sum (X_1 – \bar{X_1}) (Y – \bar{Y}) \\
S_{2y} &=& \sum (X_2 – \bar{X_2}) (Y – \bar{Y})
\end{array}
$$
それぞれ、式変形しておく。
$ S_{11} $ は、以下のように変形できる。
$$
\begin{array}{rcl}
\sum (X_1 – \bar{X_1})^2
&=& \sum (X_1^2 – 2 X_1 \bar{X_1} + \bar{X_1}^2) \\
&=& \sum X_1^2 – 2 n \bar{X_1}^2 + n \bar{X_1}^2 \\
&=& \sum X_1^2 – n \bar{X_1}^2
\end{array}
$$
ある変数、例えば $ X_1 $、の全データ数 $n$ 個の合計も、その変数の平均値 $ \bar{X_1} $ の $n$ 倍もどちらも同じ合計値になる。
なぜなら、それが平均値の特徴だからである。
この平均値の特徴を利用した式変形である。
同様に $ S_{22} $ は、以下のように書ける。
$$ \sum X_2^2 – n \bar{X_2}^2 $$
$ S_{12} $ は、以下のように変形できる。
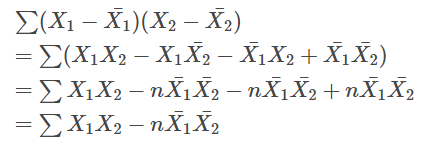
$ S_{21} $ は、1と2を逆にすればよいので、以下のようになる。
$$ \sum X_2 X_1 – n \bar{X_2} \bar{X_1} $$
$ S_{1y} $ はどうなるかというと、
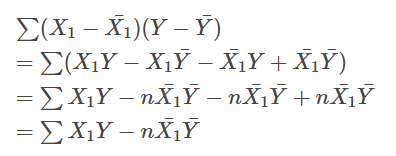
というふうに変形できる。
$ S_{2y} $ は、同様に
$$ \sum X_2 Y – n \bar{X_2} \bar{Y} $$
と書ける。
ここまで準備してから、上記で偏微分した3つの式を整理していく。
$ \beta_0 $ について偏微分した式に $ \beta_0 = \bar{Y} – \beta_1 \bar{X_1} – \beta_2 \bar{X_2} $ を投入すると以下のようになる。
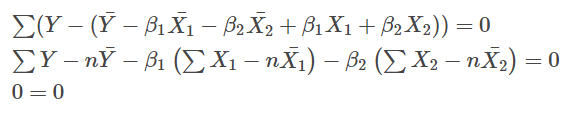
なので、$ \beta_0 $ の式は、当然ということになる。
$ \beta_1 $, $\beta_2 $ で微分した式はどうなるか?
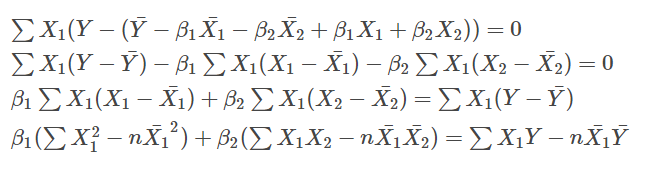
上記で計算した、変動・共変動を使って整理すると、
$$ \beta_1 S_{11} + \beta_2 S_{12} = S_{1y} $$
となる。
同様に、
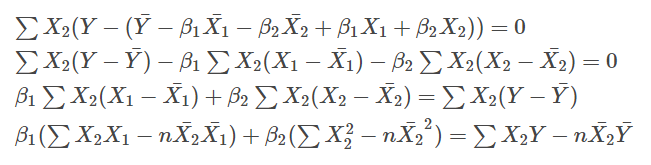
となったあと、上記で計算しておいた変動・共変動を代入して整理すると、
$$ \beta_1 S_{21} + \beta_2 S_{22} = S_{2y} $$
となる。
これらの2つの式を連立方程式として解くことにより、偏回帰係数 $ \beta_1 $, $ \beta_2 $ が求まる。
$$
\begin{array}{rcl}
\beta_1 S_{11} + \beta_2 S_{12} &=& S_{1y} \\
\beta_1 S_{21} + \beta_2 S_{22} &=& S_{2y}
\end{array}
$$
より一般的な表記としては、行列で表現すると簡単になる。
$$
\begin{pmatrix}
S_{11} & S_{12} \\
S_{21} & S_{22}
\end{pmatrix}
\begin{pmatrix}
\beta_1 \\
\beta_2
\end{pmatrix}
=
\begin{pmatrix}
S_{1y} \\
S_{2y}
\end{pmatrix}
$$
行列を文字であらわすように変更する。
$$ \boldsymbol{S} = \begin{pmatrix} S_{11} & S_{12} \\ S_{21} & S_{22} \end{pmatrix} $$
$$ \boldsymbol \beta =
\begin{pmatrix} \beta_1 \\
\beta_2
\end{pmatrix} $$
$$ \boldsymbol C =
\begin{pmatrix} S_{1y} \\
S_{2y}
\end{pmatrix} $$
というふうに定義すると、以下のように書ける。
$$ \boldsymbol S \boldsymbol \beta = \boldsymbol C $$
$ \boldsymbol S $ の逆行列を $ \boldsymbol S^{-1} $ とすると、偏回帰係数 $ \boldsymbol \beta $ は以下の式で求められる。
$$ \boldsymbol \beta = \boldsymbol S^{-1} \boldsymbol C $$
定数項 $ \beta_0 $ は、$ \beta_0 = \bar{Y} – \beta_1 \bar{X_1} – \beta_2 \bar{X_2} $ から求められる。
ここまでで、回帰式 $ \hat{Y} = \beta_0 + \beta_1 X_1 + \beta_2 X_2 $ の $ \beta_0 $, $ \beta_1 $, $ \beta_2 $ の 3つが求まり、回帰式が完成した。
重回帰分析の計算方法 標準化偏回帰係数
次に出てくる疑問として、$ \beta_1 $ と$ \beta_2 $ はどちらのほうが大きな影響力を持つのかであろう。
だが、偏回帰係数は、それぞれの連続データ $ X_1 $, $ X_2 $ の単位(cm か mm かなど)やばらつきに左右されて決まっていて、偏回帰係数自体の数値で比べることはできない。
そこで、平均0分散1に標準化して、どの変数も平均とばらつきを同じにして揃えたら、比較できるだろうと考えるわけである。
これが標準化偏回帰係数である。
標準化偏回帰係数は、最初に説明変数及び目的変数を標準化して、計算することもできる。
一方で、偏回帰係数から計算で標準化偏回帰係数を求めることもできる。
$$
\begin{array} {rcl}
\beta_1′ &=& \beta_1 \sqrt{\frac{S_{11}}{S_{yy}}} \\
\beta_2′ &=& \beta_2 \sqrt{\frac{S_{22}}{S_{yy}}}
\end{array}
$$
ここで $ S_{yy} $ は $ Y $ の変動である。
以下のスクショは、偏回帰係数を計算したのちに標準化偏回帰係数を求めた age, WBC.entry と、標準化した(Z.age, Z.WBC.entry)後に重回帰分析を行って偏回帰係数を求めた結果が一致していることを示している。
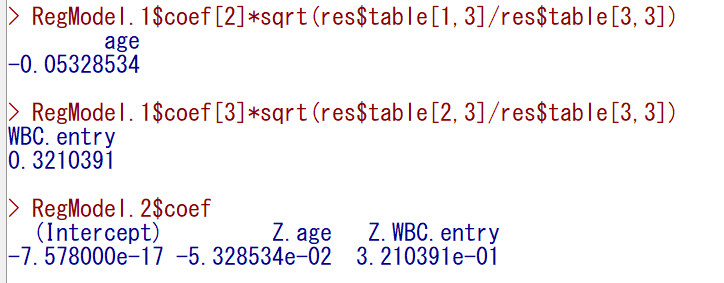
重回帰分析の計算方法 回帰モデルの有意性検定
偏回帰係数の有意性が気になるところであるが、その前に、回帰モデル自体の統計学的有意性の検定を説明する。
最終的に F 分布に従う F 値を計算する点、そこに至る過程で、変動平方和、平均平方和を計算する点で、一元配置分散分析と同様の計算を行う。
そのために、回帰の分散分析と呼ばれる。
いままでは、あえて回帰式に誤差 $ \varepsilon $(イプシロン)を書かなかったが、検定になると誤差が必要になる。
ちなみに、誤差の推定値 $\hat{\varepsilon} $ が残差(目的変数の実測値と予測値の差)$ Y – \hat{Y} $ である。
つまり重回帰モデル(説明変数2つ版)は以下のように書ける。
$$ Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \varepsilon $$
予測値 $ \hat{Y} $ を計算するための重回帰式は、$ \varepsilon $ はつかない。
$$ \hat{Y} = \beta_0 + \beta_1 X_1 + \beta_2 X_2 $$
つまり、$ Y $ と $ \hat{Y} $ の差が、$ \hat{\varepsilon} $(残差)ということだ。
$$ \hat{\varepsilon} = Y – \hat{Y} $$
分散分析では、まず、この残差の平方和 $ S_e $ を計算する。
$$ S_e = \sum (Y – \hat{Y})^2 $$
次に、全体の変動要因として、平方和 $ S_t $ を計算する。
これは、実測値 $ Y $ と実測値の平均 $ \bar{Y} $ の差の平方和である。
$$ S_t = \sum (Y – \bar{Y})^2 $$
この全体の変動要因から、回帰で説明できた変動要因 $ S_r $ を引くと、残りが残差変動要因なので、以下の関係がある。
$$ S_e = S_t – S_r $$
$ S_e $ を求めるには、上記の $ \hat{Y} $ を使った式でも求められるが、手計算で計算する場合やソフトウェアを使うにしても手順を追って計算してみる場合は、$ S_r $ を以下の式を用いて計算して、$ S_t $ から引くという方法で計算するとよい。
例えば説明変数が2つの場合は以下のような計算になる。
$$
\begin{array}{rcl}
S_r &=& \sum \beta_i S_{iy} \\
&=& \beta_1 S_{1y} + \beta_2 S_{2y}
\end{array}
$$
回帰の平方和 $ S_r $ も、残差の平方和 $ S_e $ も、それぞれの自由度 $ p $, $ n-p-1 $ で割ると平均平方 $ MS_r $, $ MS_e $ となる。
ここで $ p $ は偏回帰係数の数、$ n $ は全体のサンプルサイズである。
そして最終的に $ MS_r $ と $ MS_e $ の比を計算すると、分子の自由度が $ p $、分母の自由度が $ n-p-1 $ の F 分布に従う F 値が計算される。
有意確率が計算されて、有意水準以下であれば、統計学的有意に回帰モデルが意味があると言える。
表にまとめると以下のようになる。
| 変動要因 | 平方和 | 自由度 | 平均平方 | F 値 |
|---|---|---|---|---|
| 回帰 | $ S_r $ | $ p $ | $ MS_r = \frac{S_r}{p} $ | $ \frac{MS_r}{MS_e} $ |
| 残差 | $ S_e $ | $ n-p-1 $ | $ MS_e = \frac{S_e}{n-p-1} $ | |
| 全体 | $ S_t $ | $ n-1 $ |
重回帰分析の計算方法 決定係数
回帰モデルの有意性を見たついでに、回帰モデルによる目的変数の説明の程度を表していて、当てはまりの指標でもある、決定係数の計算方法を見ておく。
決定係数は0から1の値を取り、1に近いほど回帰モデルが目的変数の変動を説明できていると理解して、モデルがデータに当てはまっていると評価する。
慣例として0.5以上が望ましいとされるが、研究分野によってはもっと低くてもよいとされることもある。
決定係数の目安については、こちらも参照。

決定係数 $ R^2 $ は以下のように計算される。
$$ R^2 = \frac{S_r}{S_t} = \frac{S_t – S_e}{S_t} = 1 – \frac{S_e}{S_t} $$
回帰の分散分析で計算した平方和を用いて計算されている。
説明変数の数を増やしていくと、決定係数はだんだんと1に近づく性質がある。
これだと追加した説明変数のために説明できる部分が増えたのか、単に説明変数が増えたから上昇したのかがわからない。
説明変数の数を増やしたときに、説明変数の数が増えたからだけではなく実質的に決定係数が上昇したことを示すのが、自由度調整済み決定係数 $ R^{2*} $ である。
平方和を自由度で割り、平均平方にして計算する。
$$ R^{2*} = 1 – \frac{\frac{S_e}{n-p-1}}{\frac{S_t}{n-1}} = 1 – \frac{MS_e}{MS_t} $$
モデルの当てはまりや有用性を判断するには自由度調整済み決定係数を用いるほうが良い。
なお、決定係数は、寄与率と呼ばれることもある。
重回帰分析の計算方法 偏回帰係数の検定
さて、やはり一番気になるのは、偏回帰係数は統計学的に意味があるのだろうか?である。
偏回帰係数が母集団でゼロでないことが言えれば、意味があるだろう。
偏回帰係数が母集団でゼロかどうかの検定が、偏回帰係数の検定である。
もしゼロでないことが言えなければ、その偏回帰係数及びそれがかかっている変数は、あってもなくても意味がない。
母集団の偏回帰係数がゼロである帰無仮説が棄却されれば、偏回帰係数は統計学的に有意(ゼロではなく意味がある)と判断できる。
偏回帰係数の検定のためには偏回帰係数の標準誤差が必要である。
$ i $ 番目の偏回帰係数 $ \beta_i $ の標準誤差 $ SE_{\beta_i} $ は、以下の式で計算できる。
$$ SE_{\beta_i} = \sqrt{s^{ii} MS_e} $$
ここで、$ s^{ii} $ は、ずっと上の方で計算した変動・共変動行列 $ \boldsymbol S $ の逆行列 $ \boldsymbol S^{-1} $ の 左上から $ i $ 番目の対角成分である。
例えば1番目の偏回帰係数であれば、逆行列 $ \boldsymbol S^{-1} $ の (1,1) の対角成分 $ s^{11} $ となる。
つまり、説明変数が2つの場合は、以下のように計算される。
$$
\begin{array}{rcl}
SE_{\beta_1} &=& \sqrt{s^{11} MS_e} \\
SE_{\beta_2} &=& \sqrt{s^{22} MS_e}
\end{array}
$$
そして、偏回帰係数と標準誤差の比の値が、自由度 $ n-p-1 $(残差の自由度)のt分布に従う性質を利用して、有意確率を求める。
$$
\begin{array}{rcl}
t_{\beta_1} &=& \frac{|\beta_1|}{SE_{\beta_1}} \\
t_{\beta_2} &=& \frac{|\beta_2|}{SE_{\beta_2}}
\end{array}
$$
回帰モデルの前提は誤差が正規分布していること
最後に、回帰モデルの前提について説明しておく。
ほかの記事でも、まとめたものがあるので、参考まで。
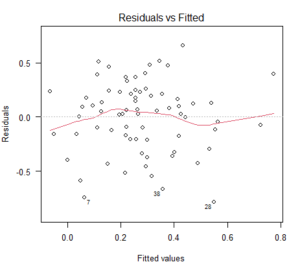
回帰モデルの前提で一番気になる点は、誤差項 $ \varepsilon $ が平均 0、分散 $ \sigma_e^2 $(何でもよいが何か適切な値)の正規分布に従うというものだ。
説明変数が2つ版の回帰式、
$$ Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \varepsilon $$
の最後の $ \varepsilon $ が 平均 0 で、分散は何らかの大きさの正規分布に従うことが条件になっている。
これは、上記の回帰の分散分析や、偏回帰係数の検定の際、検定統計量の分母に誤差(残差)の平均平方が来ていることからも理にかなっている。
F分布やt分布を使った検定は、母集団が正規分布であることを仮定しているという大前提がある。
F値の分子である回帰部分の平均平方やt値の分子である偏回帰係数は、回帰モデルから計算されている値で、これ自体はどんな分布をするかは不明であるが、少なくとも分母の残差の平均平方は正規分布していることが検定の条件であることは理解しやすい。
以上のことから、回帰モデルの誤差項(の推定値の残差)が正規分布していることは、回帰分析に関する検定が適切に実施される必要条件と言える。
まとめ
重回帰分析の計算方法について、順を追って確認してみた。
また、重回帰分析の前提は、誤差(残差)が正規分布していることであることについて付け加えた。
何らか参考になれば。

コメント