
2018年– date –
-

R と MeCab でテキストマイニングを行う方法
Rでテキストマイニングするやり方。 MeCab と RMeCab を使う方法。 例として、ワードクラウドを描く方法を紹介。 テキストマイニングとは? テキストデータを名詞、動詞、形容詞など、濃い意味合いを持つ言葉と、助詞、助動詞、感嘆詞、疑問詞など意味合い... -
R で主成分回帰と部分的最小二乗回帰を実行する方法
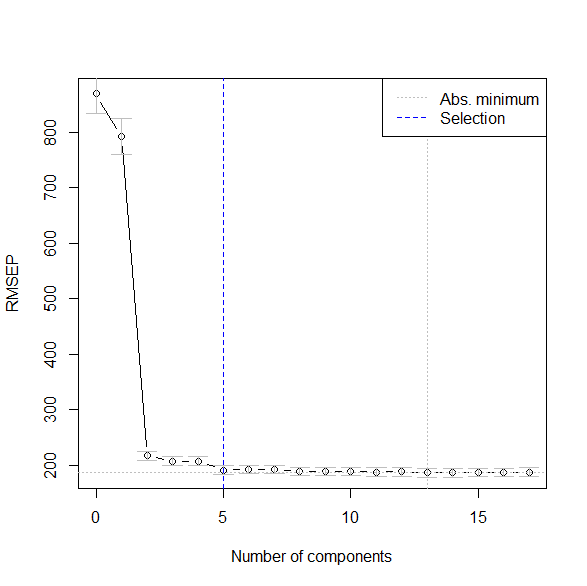
主成分回帰と部分的最小二乗回帰を R で実行する方法の解説 部分的最小二乗回帰とは 部分的最小二乗回帰の前に、主成分回帰を説明する。 主成分回帰(Principal Component Regression, PCR)は、主成分分析と回帰分析の融合。 主成分分析で情報の集約をし... -
R で主成分分析を行う方法
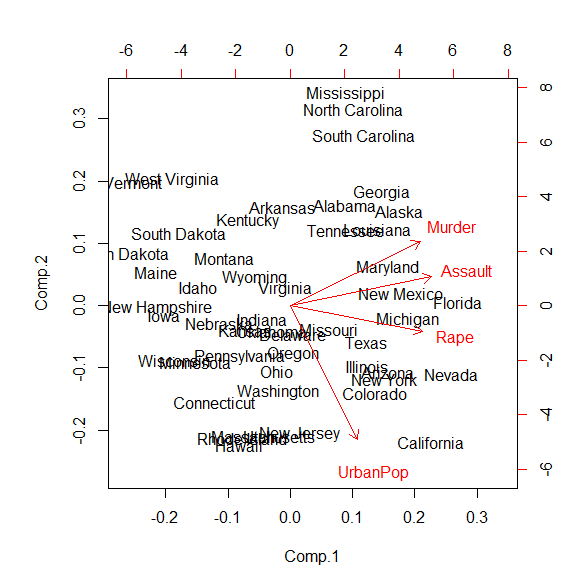
主成分分析は、たくさんの変数を、合成変数に集約する分析。 主役級の主成分から第一主成分、第二主成分、・・・と呼ばれる。 たくさんの変数を、いくつかの主成分でまとめると、情報がまとまって考えやすくなる。 Rで主成分分析を行う方法 princomp()を使... -
R でリッジ回帰・ラッソ回帰・エラスティックネットを実行する方法
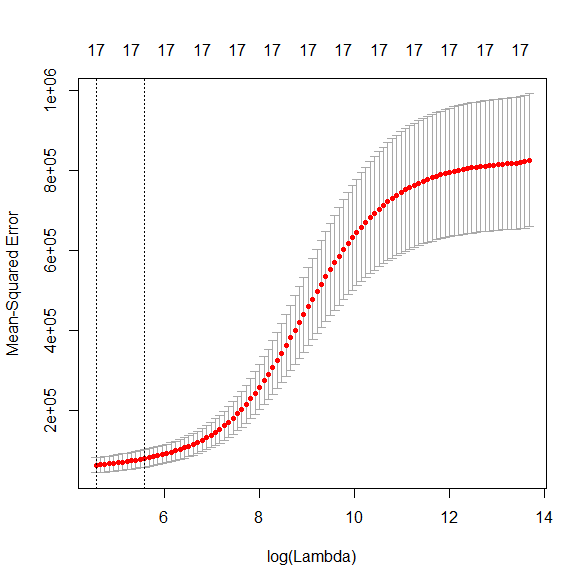
エラスティックネットを簡単に解説 R で実行する方法も解説 リッジ・ラッソ・エラスティックネットとは? 線形回帰モデルは、係数 β(パラメータ)を推定するときに最小二乗法を用いる。 通常の最小二乗法は、従属変数の実測値とモデルから計算された値と... -
R で SVM の C パラメータについて具体例を示す
SVM(サポートベクターマシン)のコストパラメータ C について。 SVM の C とは? SVM(サポートベクターマシン)のコストパラメータ C とは何か? コストパラメータ C は誤分類を許容する指標。 C が小さいと誤分類を許容する。 大きいと誤分類を許容しな... -
サポートベクターマシンとは?ごく簡単に解説
機械学習の分類手法の一つ、サポートベクターマシンとは何か? サポートベクターマシンの前に最大マージン分類器について サポートベクターマシンを説明する前に最大マージン分類器から話を始めねばならない。 最大マージン分類器、サポートベクター分類器... -
R でランダムフォレストを最適化する方法
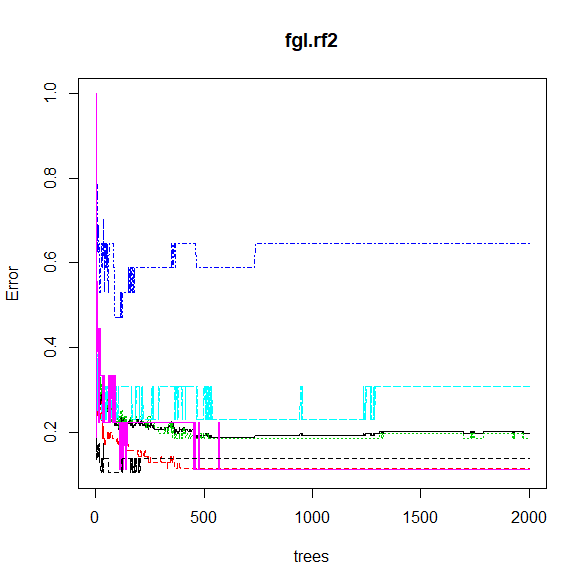
ランダムフォレストはチューニングして最適化する。 チューニングは決定木を最適化する方法。 ランダムフォレストの場合は、決定木の数と特徴量(説明変数)の数を最適化する。 ランダムフォレストのパッケージのインストールと準備 最初に一回だけパッケ... -
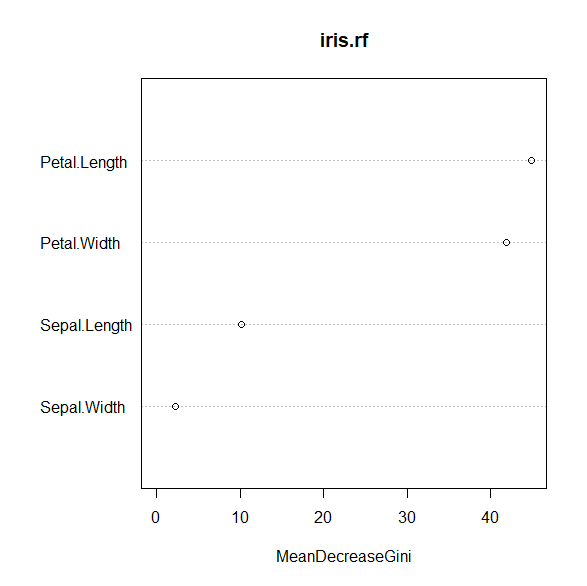
R でランダムフォレストを行う方法 重要度の可視化の方法
R でランダムフォレストを実行する方法。 ランダムフォレストとバギングの違い ランダムフォレストとバギングの違いは、こちらの記事を参照。 R でランダムフォレストを実行するパッケージの準備 パッケージはrandomForestというそのままの名前のパッケー... -
R でアンサンブル学習のバギングを行う方法
バギングというアンサンブル学習を R でやってみる。 ランダムフォレストとバギングの違い ランダムフォレストとバギングの違いは、以下の記事を参照。 バギングのための R パッケージの準備 adabagパッケージをインストールする。 install.packages("adab... -
ランダムフォレストとバギングの違い
ランダムフォレストとバギングは、決定木をより汎用化するために考えられた手法。 違いは何か? 概念的な簡単な説明。 ランダムフォレストとバギングの総称 アンサンブル学習とは何か? ランダムフォレストとバギングはともにアンサンブル学習と呼ばれてい... -
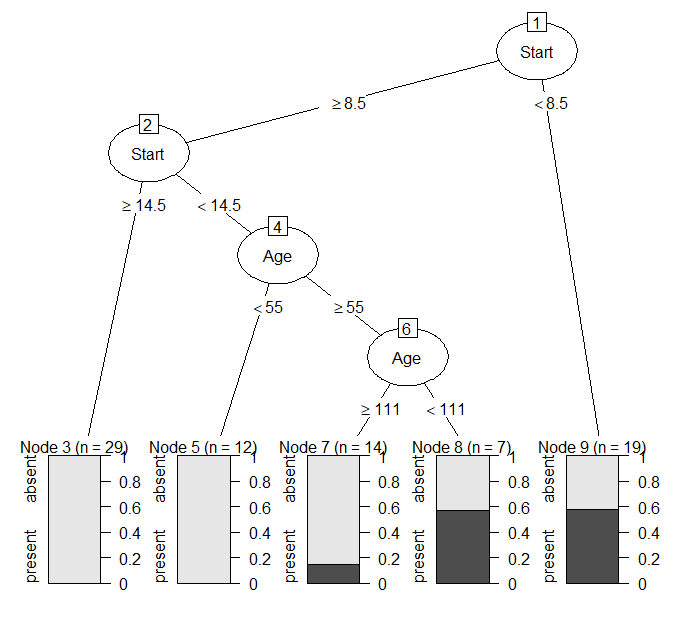
R partykit で決定木分析を実行する方法
決定木分析をRで行う方法を紹介。 難しいプログラムが組めなくてもすぐに使える。 決定木分析のRパッケージの準備 決定木分析のパッケージrpartときれいな決定木の描画パッケージpartykitをインストールする。 インストールは初めの一回だけでOK。 install... -
決定木の過学習を防ぐ剪定(枝刈り)とは?
決定木には剪定(せんてい)という過程がある。 剪定とは何か? 簡単に紹介。 決定木の弱点 過学習 あるデータセットから、決定木を作ったとする。 決定木は、大きく茂らせれば茂らせるほど、きれいに分岐して、分類してくれる。 しかしながら、機械学習... -
機械学習の決定木分析に計算される Gini 不純度とは? わかりやすく解説
決定木の分岐(ノード)を作るときどのような計算をしているのか? Gini不純度を計算しているのだが、Gini不純度とは何か? 機械学習の決定木における Gini 不純度とは? Gini不純度とは、ある特徴でデータを2分割するときに、特徴の要素Aである確率とAで... -
機械学習による決定木分析 ごく簡単な解説
機械学習をする方法はさまざまある。 代表的な方法は決定木分析である。 そもそも決定木とは何か? 基本的なことをごく簡単に解説。 決定木とは何か? 決定木とは意思決定に使う、いくつもの枝分かれをする図のこと。 膨大なデータを使って、決定木のモデ... -
統計に必要なサンプル数が計算できるエクセルファイルのリンク集
標本の大きさの求め方。エクセルを使う方法。 サンプルサイズ計算をエクセルで行う方法。 なかなか探しても見つからないサンプルサイズ計算がここでは見つかる!! アンケート調査 アンケートは何人に取れば最適なのか? エクセルファイルで簡単に計算でき... -
R で分類課題を機械学習モデルで実行する方法
機械学習で、よりよく推測できるモデルを選ぶ。 統計ソフトRのISLRパッケージのWeeklyデータで基礎的な機械学習を行ってみた。 Rで機械学習を行うためデータの準備 ISLRパッケージのWeeklyデータは、S&P500指数の週当たりのリターンのデータ。 9つの変... -
R で重回帰分析を行う具体例 ― ISLR パッケージ Auto データセットを使った重回帰分析
R の ISLR パッケージの Auto データセットを使った分析例。 データの準備 最初の一回だけ、ISLRパッケージをインストール。 install.packages("ISLR") ISLRパッケージを呼び出して、解析開始。 library(ISLR) ISLRパッケージのAutoデータセットを用いて解... -
R で NNH Number Needed to Harm を計算する方法
有害必要数(Number Needed to Harm, NNH)は、1人の有害事象が起こる人が出現するのに、何かの影響を受けた人が何人必要かという数。 NNHを計算するにはどうやるか? 使えるシチュエーションは、 曝露Aを受ける人受けない人 処置Bを受ける人受けない人 介... -
R で罹患率比を求める方法
罹患率比の計算は、どうやるのか? R での計算の方法。 罹患・罹患率・罹患率比とは? 罹患(りかん)とは? 罹患とは病気にかかること。 病気にかかったことは、診断によってわかる場合と、発症によってわかる場合がある。 診断とは、外来の診察で下され... -
相関と回帰の違いは何か?
相関と回帰はどう違うか? 両方とも2つのデータの関係性を見ているわけで、とても似ている。相関と回帰の違いについて、まとめてみる。 相関と回帰の根本的な違いは? 相関は、相関係数が中心で、 データXとデータYの お互いの関係性を見る。 相関分析には... -
R でロジスティック回帰分析の変数選択の参考になる計算上ベストな変数セットを提案してくれる方法
Rを使って、 多重ロジスティック回帰分析でBICを使って、 簡単に変数選択ができる。 変数選択の関数の前に BIC とは BICは、 Bayesian Information Criterionの頭文字語。 統計モデルへのあてはまりを検討するときに、 変数が多すぎると評価が下がる規準に... -
R で重回帰分析の変数選択に参考となる計算上ベストな変数セットを提案してくれる方法
R で重回帰分析を行った際の変数選択の方法の解説。 bestglmの準備とサンプルデータ R の bestglm() 関数は、AIC, BIC(デフォルト), BICqなどの Information Criterion 情報規準を使って ベストの変数の組み合わせを見つけてくれる。 bestglmパッケージのz... -
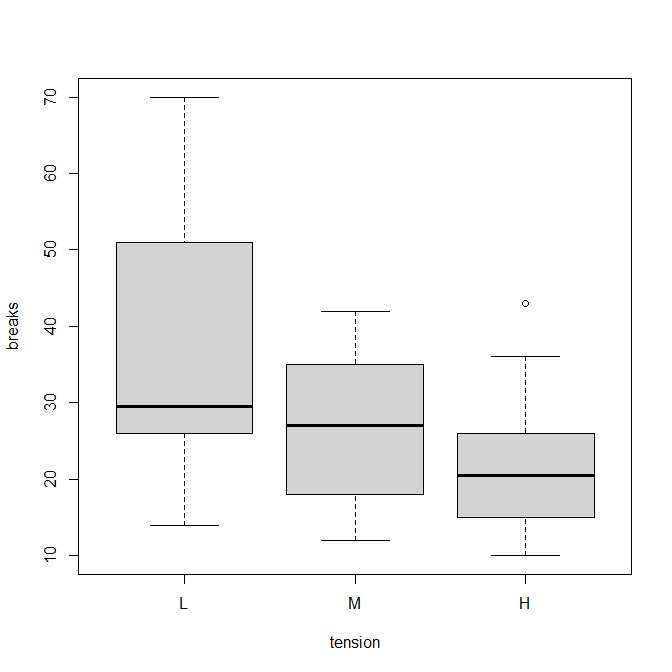
R で箱ひげ図を書く方法
R で箱ひげ図を描くにはどうしたらいいか? R で箱ひげ図を書く関数 R で箱ひげ図を書く関数は、boxplot() 第 1 四分位から第 3 四分位までの箱を描き、その中にある中央値に線を引く。 第 1 四分位と第 3 四分位の差(四分位範囲)の 1.5 倍の線(ひげ)... -
R でログランク検定に必要なサンプルサイズを計算する方法
ログランク検定のサンプルサイズ計算を R で行う方法 ログランク検定はどうやるか? ログランク検定は、時間経過とともにイベントが起きていくデータの群間比較をする方法。 患者さんの死亡をイベントとしたデータ、病気が再発することをイベントとしたデ... -
R で級内相関係数 ICC(2,1) を計算する方法と必要なサンプルサイズを計算する方法
級内相関係数 ICC Case2 の計算とサンプルサイズ計算を R でやってみた 級内相関係数 ICC(2,1) の計算例 級内相関係数 Intra-class Correlation Coefficient Case2 ICC Case2 は検者間信頼性の指標。 患者さんを数名の検査者(または評価者)で検査(また... -
R で級内相関係数 ICC(1,1) に必要なサンプルサイズを計算する方法
ICC(1,1) の計算とサンプルサイズ計算を R で行う方法 級内相関係数 ICC(1,1) の計算 級内相関係数(ICC)は、信頼性指標に使える。 ICC Case1は、一人の検査をする人(検者、けんじゃ)の一貫性を確認する指標だ。 ICC(1,1)は、一人の検者がk回測定を行っ... -
R でトレンド検定に必要なサンプルサイズを計算する方法
トレンド検定のサンプルサイズ計算。 トレンド検定とは トレンドとは、順序カテゴリの小さいほうから大きいほうに移るにつれて、カテゴリの平均値や割合が大きくなるとか小さくなるとか、傾向や相関があることを指す。 トレンドがなく同じというのが帰無仮... -
R でダネット検定に必要なサンプル数を計算する方法
ダネット検定のサンプルサイズ計算を R で行う方法 ダネット検定サンプルサイズ計算スクリプトの前提 ダネット検定とは、コントロール群、統制群、非処理群などと呼ばれる比較対照グループと、複数用量の治療群、処理群を比較する検定である。 サンプルサ... -
R で 共分散分析において 3 群以上のカテゴリの多重比較をする方法
三群以上の平均値を多重比較したい。 でも各群の背景因子がそろっていない。 背景因子を調整しながら三群以上の平均値を多重比較するにはどうすればいいか? R でのやり方を解説する。 共変量を調整して多重比較する方法 群ごとの背景因子は、群分け変数と... -
R でノンパラメトリック検定の多重比較を実行する方法
ノンパラメトリックの多重比較をRで実施する方法。 ノンパラメトリックとは何か? ノンパラメトリックとはパラメトリックではないという意味。 パラメトリックとは、パラメーターを使うという意味だ。 パラメーターとは、日本語では母数(ぼすう)と言われ... -
R でフィッシャーの正確確率検定・カイ二乗検定 で 3 群以上の比較を実行する方法
フィッシャーの正確確率検定、カイ二乗検定の3群以上の比較をRで実施する方法の解説。 カイ二乗検定の3群以上の比較 三群以上の割合の比較はどうやればいいのか? Bonferroni型のp値調整を使う方法がある。 Rで行う場合、pairwise.prop.test()という関数を... -
R でボンフェローニを実行する方法
検証試験において、三群以上の平均値を比較したいときに、単純に二群比較を繰り返すと有意水準が甘くなる。 有意水準の調整によって簡単に処理する方法がボンフェローニ (Bonferroni)の方法とその進化版だ。 Rでボンフェローニ型のP値調整で多重比較を行... -
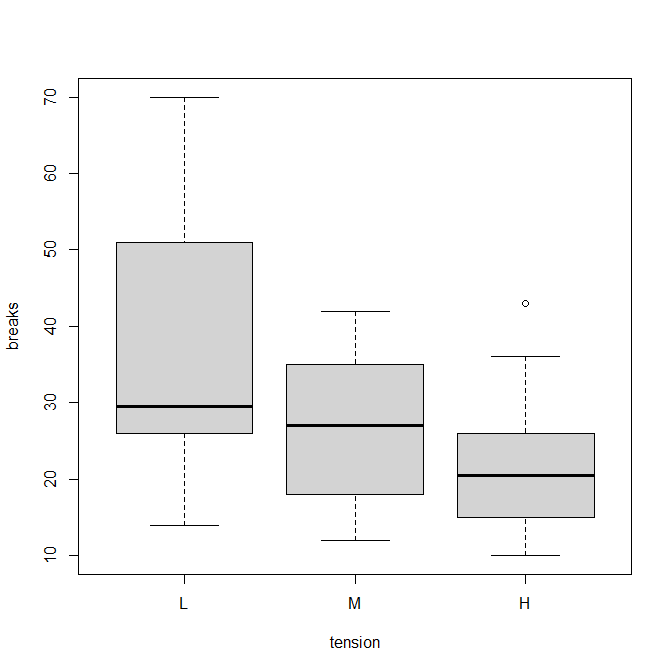
R でチューキー検定を行う方法
Tukey HSD検定をRで行う方法の解説。 Tukey HSD検定をRで行う方法 aov()とTukeyHSD()という二つの関数を使う。 ダネット検定のときと同じように、例としてwarpbreaksというデータを使う。 ダネット検定は以下を参照。 機織りにおいて、tension(緊張、張り... -
R でダネット検定を行う方法
ダネット検定は、比較対照群といくつかの実験群を多重比較する方法。 Rでダネット検定をするにはどうしたらよいか? Rでダネット検定をするには? まずmultcompパッケージをインストール。 インストールは一回だけでOK。 install.packages("multcomp") 次... -
R でクロスオーバー試験に必要なサンプルサイズを計算する方法
クロスオーバー試験のサンプルサイズ計算を R で行う方法 クロスオーバー試験とは クロスオーバー試験とは、二群どちらにも二つの介入を受けてもらう試験。 従来の薬と新薬とか、方法Aと方法Bとか、二つの方法を順番を変えて受けてもらう。 利点は、小さい... -
R で非劣性の生存時間解析に必要なサンプルサイズを計算する方法
非劣性試験のサンプルサイズ計算 生存時間データの場合 非劣性試験のサンプルサイズ計算 生存時間データの場合 例 1 各記号の意味は以下のとおり。 t:観察期間。 S1とS0:それぞれ治療群とコントロール群の生存率。 dF:Freedmanの方法による各群必要な死... -
R と EZR で平均値の非劣性検定に必要なサンプルサイズを計算する方法
非劣性試験のエンドポイントが連続量で、各群の平均値を求める場合、サンプルサイズはどのように計算するか? RとEZRで行う方法。 非劣性試験における非劣性検定とは? 劣っていないことを積極的に証明する検定。 臨床的に意味のある差を設定して、それよ... -
R と EZR で割合の非劣性検定に必要なサンプルサイズを計算する方法
非劣性検定は劣っていないことを証明する検定。 割合の非劣性検定のサンプルサイズ計算はどうやるか? 割合の非劣性検定のサンプルサイズ計算 各変数の意味は、以下のとおりとする。 pA:試験薬の有効率とする。 pB:標準薬の有効率とする。 pB.bar:帰無... -
R と EZR で生存時間解析のサンプルサイズ計算を行う方法
生存時間解析のサンプルサイズ計算の方法 Cox の比例ハザードモデルを使う前提の計算 生存時間解析のサンプルサイズ計算 その 1 R でスクリプトを書いてみた。 S0がコントロール、S1が治療群、それぞれの生存率。 dが、両群合わせて合計の死亡者数。 sampl... -
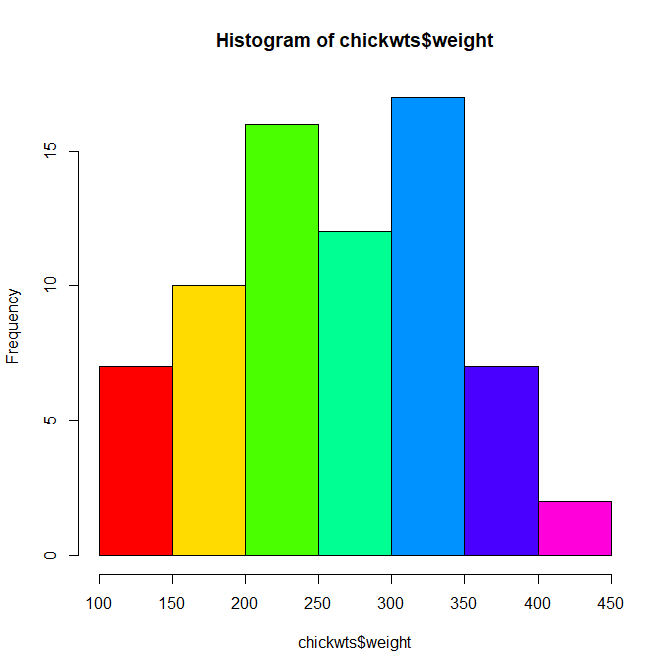
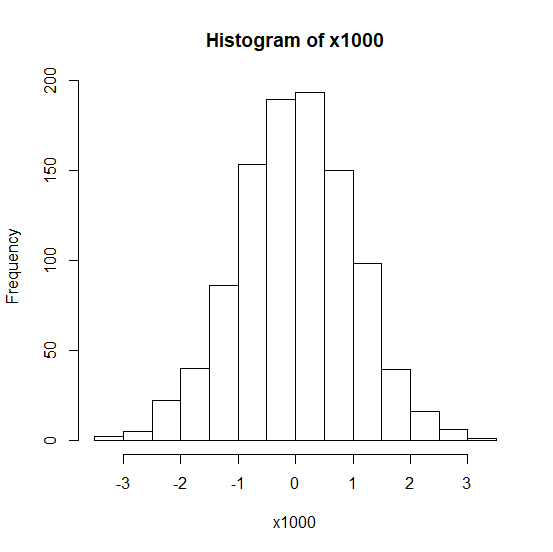
R でヒストグラムを書く方法
R でヒストグラムを書く方法 超簡単なので、実行必須 連続データは必ずヒストグラムを見てみるべき R のヒストグラムの作り方 R でヒストグラムを描くには、hist() を使う ヒストグラムというのは、いくつかのカテゴリに区切って、データの分布をグラフで... -
R で複数のグラフを並べて書く方法
R でグラフを複数並べる方法の解説 R でグラフを複数並べる方法 layout() グラフを並べて描きたいと思うことは多い R の場合、layout() という関数を使う R でグラフを複数並べる方法 グラフを縦に2つ並べる layout(1:2) グラフを縦に 2 つ並べる場合は、l... -
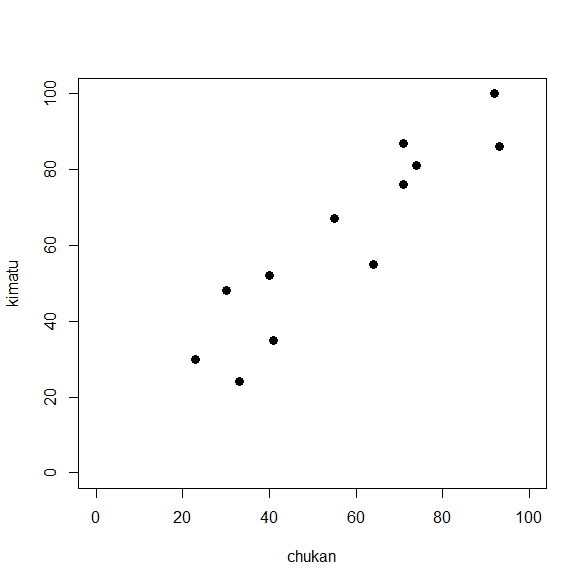
R で相関係数を計算する方法
例えば、身長が高いと体重が重いとか、年齢が高いと血圧も高いとか、関係している二つの事柄は多い。 これを相関関係という。 R で、散布図、相関係数計算、相関係数検定をやってみた。 相関係数を求める前に散布図を書く方法 散布図は、相関関係があるか... -
R で割合を計算する方法
R でカテゴリデータを集計して、割合を計算する方法。 R で割合を計算する方法 カテゴリデータの集計の方法 もっとも使うのがtable()。 表(table)形式で集計する関数だ。 例としてMASSパッケージのbirthwtデータフレームを使う。 lowは低体重出生(1)か、そ... -
R で skewness や kurtosis を計算する方法
R で skewness や kurtosis を計算する方法。 平均と標準偏差 統計ソフトRで、平均値は、mean()で算出する。 標準偏差は、sd()で計算する。 sdはstandard deviationの略。 平均値と標準偏差の値の関係で、データの分布を大まかに推測できる。 平均値が標準... -
R の attach の使い方
R の attach とはどんな関数か? データフレームとは? R の中で、データフレームとは、データの一つの塊を言っている。 それも、変数名がついて、何列かのデータのことだ。 エクセルで言えば、A、B、Cと列が並んでいるところに、 Aには、年齢 Bには、性別... -
R のライブラリとは
R でlibrary() ライブラリ はよく使う関数だ。 ライブラリとは? ライブラリの定義 ライブラリは、辞書の定義だと、 〔コンピュータ〕ライブラリー: プログラムやデータなどをひとまとまりに登録したファイル. 出典:Progressive English-Japanese Diction... -
R にパッケージをインストールする方法
Rは、最初からかなりいろいろなことができる無料統計ソフト。 もっとすごいのは、あとからパッケージをインストールして、さらにいろいろな解析ができるようになること。 R は追加パッケージをインストールする前からすごい! まず、新しいパッケージをイ... -
R の引用情報を参考文献リストに載せたいときの書き方
R の引用情報を参考文献リストに載せたい。 どのように記載すればよいか? R の引用情報の取得方法 コンソールで citation() と書いてエンター。 引用の際の情報が出てくる。 例: To cite R in publications use: R Core Team (2018). R: A language and ... -
多変量モデルの変数選択はどうすればいいのか?
多変量調整モデルの調整変数をどのように選ぶべきかは悩ましい。 統計ソフトにあるステップワイズ法は使っていいのか? 統計ソフトによっては、ステップワイズ法が準備されている。 ステップワイズ法とは、ステップを踏んで最良のモデルを見極める方法。 ... -
R で説明変数が連続データの場合にロジスティック回帰分析で必要なサンプルサイズを計算する方法
独立変数が連続量のロジスティック回帰のサンプルサイズ計算の方法 ロジスティック回帰のサンプルサイズ計算スクリプト 連続データの場合 p0を平均値レベルでの発生確率とする。 p1を平均値+1SD(標準偏差)レベルでの発生確率とする。 サンプルサイズ計... -
R でマッチドケースコントロール研究に必要なサンプルサイズを計算する方法
マッチドケースコントロール研究のサンプルサイズ計算の方法 マッチドケースコントロール研究とは? 年齢、性別、など、病気に深くかかわっている因子だけど、研究対象にしたいわけでないとき、影響をなくしてしまいたい。 ケースとコントロールの重要な因... -
R でケースコントロール研究に必要なサンプルサイズを計算する方法
ケースコントロール研究のオッズ比を求めるためのサンプルサイズ計算はどうやるのか? ケースコントロール研究のサンプルサイズ計算の前提 一般人の危険因子にさらされている割合をfとする。 想定されるオッズ比をRとする。 前提はこの二つだけだ。 この二... -
サンプル数が大きく異なる群間比較の妥当性
臨床研究では、比較的まれな疾患の患者さんのデータと、その疾患を持たない対照群のデータを比較しようとすると、両グループの人数が大きく異なることがよくある。これは、まれな疾患ではそもそもデータが集まりにくいという現実があるためだ。 このように... -
R で分散分析に必要なサンプル数を計算する方法
分散分析のサンプルサイズ、サンプル数、n 数の計算を R でやってみた。 分散分析のサンプルサイズ計算(誤差分散がわかっている場合) 群の数をk、群間で最大の差(母平均の差の最大値)をd、誤差の母分散の平方根を sigma0 とする。 この場合の母分散は... -
相関係数の目安と R で必要サンプル数を計算する方法
相関係数を求めたいサンプル数が少ないけど、大丈夫なのか? 相関係数が大きい場合、サンプル数は少なくても大丈夫。 目安となるサンプル数はどのくらいか? 相関係数の目安・意味 相関係数には、以下のような目安がある。 相関係数の絶対値関連の程度0.0... -
アンケート調査に必要なサンプル数を R で計算する方法
アンケート調査は何人にとったらいいか? アンケート調査に必要なサンプル数の前にアンケート調査の目的 アンケート調査に必要なサンプルサイズを考える前に、アンケート調査では、何をどうしたいのか? 「アンケート調査に必要なサンプル数」といった場合... -
アンケート調査には何人以上必要か R で計算する方法
アンケート調査には何人以上必要か アンケート調査には何人以上必要か 無限母集団の場合 よくある質問。 「アンケート調査は何人にとったらよいでしょうか。」 「世論調査のサンプル数は本当に意味があるのでしょうか。」 「視聴率調査のサンプル数はどう... -
R で割合の推定・検定に必要なサンプル数を計算する方法
割合に関するサンプルサイズ計算の方法 推定精度と検定の 2 種類あり 推定精度に基づく方法 相対精度deltaで,割合を推定する際のサンプルサイズ計算は、以下のような R スクリプトで計算できる。 myPsize <- function(p,delta){ n <- 4*(1-p)/(p*de... -
R で対応のある t 検定に必要なサンプル数を計算する方法
対応のある t 検定は、前後比較をするデザインの時に用いる。 対応のある t 検定のサンプルサイズ、サンプル数はどのくらいであればよいか? 対応のある t 検定のサンプルサイズ計算に必要な数値 サンプルサイズ計算に必要なのは、 検出力 標準化された前... -
R で t 検定に必要なサンプル数を計算する方法
t 検定のサンプル数計算の方法 t 検定のサンプル数計算(1:1の場合) R の power.t.test()を用いる。 必要な情報は、検出力をどうするかと、二群の平均値の差。 標準偏差で割った標準化された差が必要だ。 検出力は慣例で80%=0.8が多い。 90%=0.9もよく...


12