
基礎知識– category –
-

統計ソフトを困らせないために。「有意差」と「P値」の前に知っておきたいこと
統計を学び始めたばかりの頃、誰もが一度は「この平均値に有意差はありますか?」と問いかけたり、「とりあえず統計にかけてP値を出してほしい」と願ったりするものである。 しかし、統計の専門家やコンサルタントにこの質問を投げると、彼らは少し困った... -
統計学の羅針盤:標準正規分布表を「1分」で読み解く完全攻略ガイド
統計学の学習において、多くの者が最初に突き当たる壁が、無数の数字が並ぶ「標準正規分布表」である。しかし、この表の本質は極めて単純だ。これは、「あるスコアが全体の上位何%に位置するか」を指し示す、データの世界の精密な地図に他ならない。 本稿... -
その考察、間違っていませんか?「有意差なし=効果なし」という誤解の罠
統計学を学び始めたばかりの者が最も陥りやすい罠、それが「有意差なし($p > 0.05$)」を「差がない」と解釈することである。 医学研究において、この誤解は治療の選択を誤らせる致命的なリスクを孕んでいる。本記事では、なぜ「有意差がない」ことが... -
リッカート尺度は「平均」を出してもいい?連続データとして扱う根拠と注意点
アンケート調査で頻繁に使われる「非常に満足」から「非常に不満」までの5件法。これを統計解析の際に「平均値」を出せる連続データとして扱ってよいのか、迷う実務者は多い。 厳密に言えば、リッカート尺度は順序を付けただけの「順序尺度」である。しか... -
統計学の落とし穴?「前提確認の検定」を避けるべき理由と正しい向き合い方
データ分析を行う際、「正規分布しているか?」「分散は等しいか?」と、手法を選ぶための「予備テスト(前提確認)」を行っていないだろうか。実は、この予備テストの結果を見てから本番の検定手法を選択する行為は、統計的な誤りを生む原因となる。本記... -
信頼区間の重なりで「差」を判断してはいけない理由
2つのグループの平均値を比較する際、多くの人がそれぞれの平均値の95%信頼区間が重なっているかどうかを見て、「統計学的に有意な差があるか」を判断しようとする。しかし、これは誤りである。実は、2つの信頼区間が重なっていたとしても、統計学的に有意... -
生物学的同等性試験における90%信頼区間の重要性
新薬開発や後発医薬品(ジェネリック医薬品)の開発において、薬剤の有効性と安全性を科学的に評価することは極めて重要である。その中でも、すでに承認されている医薬品(先発医薬品)と新しい医薬品が、体内で同等に作用するかを評価する生物学的同等性... -
統計的推測のその先へ:効果量の計算と実践
研究論文や統計解析の結果を目にしたとき、「有意差があった」という報告に接する機会は多い。しかし、P値が示す統計的有意性は、あくまで偶然によるものか否かという確率的な指標に過ぎない。では、その研究によって「どれくらいの効果があったのか」「そ... -
効果量とサンプルサイズの関係性:統計的検出力の向上を目指して
統計的仮説検定は、日々直面する様々な疑問に科学的に答えを出すための強力なツールである。特に医療や教育といった分野では、新しい治療法や学習方法の効果を検証する際に不可欠である。この検証の鍵を握るのが「効果量」と「サンプルサイズ」。これら二... -
有意水準、検出力、サンプルサイズ:統計的仮説検定の三位一体
統計的仮説検定は、科学研究やビジネスにおいて意思決定を行う上で不可欠なツールである。しかし、その結果を正しく解釈し、適切な結論を導き出すためには、「有意水準」「検出力」「サンプルサイズ」という三つの重要な概念の相互関係を理解することが不... -
傾向スコアを利用した解析
傾向スコアは、処方意向の確率を、背景因子で推測するという枠組みで計算される数値である 傾向スコアを用いることで、観察データを使用した、仮説に基づいた比較ができることになる 実際の利用方法を簡単に解説する 傾向スコアを利用した解析の総論 臨床... -
重回帰分析における当てはまりの良さに関するいくつかの指標の違いと使い分け
重回帰分析(以下、線形回帰も同義)には当てはまりの良さの指標としていくつかあるが、それらの違いと使い分けはどうしたらよいのか? 自由度調整済み決定係数の特徴 説明率とも言われる決定係数の説明変数の個数を考慮したバージョン 0 から 1 の間の値... -
決定係数が小さい場合の考え方
重回帰分析の評価指標の一つ、決定係数が小さいときに、どう考えたらよいか どのくらいの数値であったら、大丈夫なのだろうか 決定係数がどのくらいであれば意味があるか? 決定係数は、0.7 以上欲しいとか、0.5 でもよいとか、分野によっては 0.3 でもよ... -
標準化偏回帰係数の簡単な解説
標準化偏回帰係数(ひょうじゅんかへんかいきけいすう)とは何か? 一言で言えば、単位が異なる説明変数の、目的変数に対する影響力を比較したいときに、便利な数値と言える 順を追って、式なしでイメージだけでわかりやすく解説 標準化偏回帰係数の前に回... -
統計解析における各種変数・データの呼び方を整理する
統計解析において、同じ意味合いで、違う呼び名が存在する それらを列挙して、整理したい 目的変数 研究の目的の項目、事項、事象、アウトカム、エンドポイントを測定、観測したデータのこと ほぼ同じ意味合いの言葉従属変数、応答変数、アウトカム、エン... -
エクセルでデータ分析ボタンを表示させる方法
エクセルでデータ分析をしたいが、データ分析というボタンが見つからない エクセルで、データ分析がない場合の対処法 エクセルでデータ分析がない場合はファイルから まず、ファイルをクリック 次に、オプション(一番左下)をクリック アドイン → 分析ツ... -
欠損値の分類 3 つとそれぞれの簡単な解説
欠損値(欠測値も同じ)は、生じる理由や前提から考えて、3 つに分けられるという話 欠損値とは 本来取得したかったデータで、取得できなかったデータのこと もともと取得できない・取得しなかったデータも同じ扱いなので、同じように欠損値と呼んでも問題... -
SPSS でグループごとの分析を行う方法
SPSS でグループごとの分析を行う場合、どのようにしたらよいか? SPSS でグループごとの分析を行う方法 1: ケースの選択 分析するデータを読み込んだ後、以下の手順で設定する データ → ケースの選択 をクリック 例えば性別 gender が 1 のグループだけ... -
クラスカルウォリス検定の各群サンプル数条件とタイデータの影響
クラスカルウォリス検定を、原著に立ち返って、わかりやすく解説。 各群のサンプル数が偏ってはいけないなどの条件があるのかどうか、また、タイデータ(同順位データ)の影響について。 クラスカルウォリス検定とは? クラスカルウォリス検定とは、3群以... -
R と EZR で学ぶ主成分分析の計算方法
主成分分析は、多変量情報の縮約と言われるが、実際にはどんな計算をしているのか? 数学的に少し詳しくわかりたい人向け。 主成分分析の計算上の目標は合成変数の作成と分散の最大化 主成分分析の数学的な計算の目的は、合成変数の作成と、その合成変数の... -
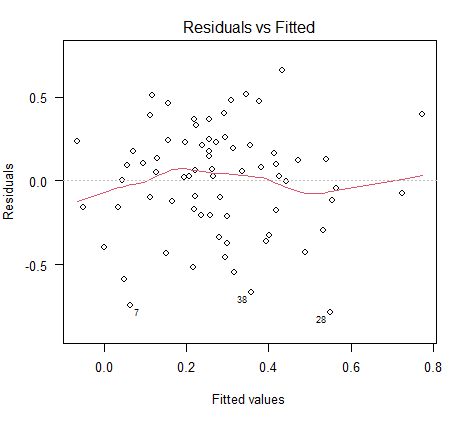
回帰分析における 7 つの仮定
目的変数が正規分布している必要はない。 説明変数も正規分布している必要はない。 前提知識 実際に測定された目的変数を実測値と言う。 回帰式で計算された目的変数を予測値と言う。 実測値と予測値の差を残差と言う。 正式には母集団の誤差項の話になる... -
EZR の集計結果・解析結果をエクセルに簡単きれいに貼り付ける方法
EZRの出力をExcelにきれいに貼り付ける方法。 標準の機能を使う方法と、テキストファイルウィザードを使う方法を紹介する。 ベースラインの患者背景の表 「グラフと表」メニュー中の「サンプルの背景データのサマリー表の出力」を使うと、ベースラインの患... -
決定係数とモデルの有意性の分散分析 ― 重回帰モデルの評価としての意義
重回帰モデルの評価指標の決定係数とモデルの有意性の分散分析の検定はどのように使い分ければよいのか? 決定係数とは? 決定係数とは、推定された重回帰モデルが実際のデータにどの程度当てはまっているかを表す指標である。 0から1の範囲の数値をとり... -
交互作用は文脈によって意味が異なるので意味合いを確認したほうが良い
どうやら「交互作用」と言ったときに、何を指すかは、人それぞれのようだ。 交互作用という言葉の帰納的解釈 ウェブサイトを漁ってみて、以下の暫定的な結論にたどり着いた。 大きくわければ、交互作用は2つの意味で使われている。 効果修飾の意味で使っ... -
構造方程式モデリングを ざっくり わかりやすく 解説
構造方程式モデリング(SEM)とは? ざっくり、わかりやすく解説 構造方程式モデリング SEMとは? 構造方程式モデリングは、英語の略語で SEMと呼ばれ、Structural Equation Modeling の略である。 これは複数の変数を用いて、理屈で考えた、変数間の相関... -
変化量の標準偏差を推定する場合に分散の加法性が成り立たないことについて
連続量の前後比較の際に、先行研究のデータ等から、変化量の標準偏差を知りたいと思うことがある。 しかし、たいていは変化量の標準偏差は掲載されていない。 前と後、別々の標準偏差から、変化量の標準偏差が分散の加法性を使って推定できないか? 変化量... -
ANOVA Type I Type II Type III の違い
ANOVAには3つの種類がある。 Type I, II, IIIの3つ。 どんな時にどれを使えばよいか? RにおけるANOVAの種類:Type I ANOVA Rのデフォルトで使えるANOVAは、anova()とaov()である。 これらはともにType I と呼ばれるANOVAである。 Type I は、複数の因子... -
傾向スコアマッチングのキャリパーはどのくらいが適切か
傾向スコアマッチングのキャリパーはどのくらいが正解か? ネット上にある情報をまとめてみた。 マッチングのキャリパーとは マッチングのキャリパーとは、マッチする症例同士がどのくらいまで離れているのを許容するかという幅である。 例えば年齢をマッ... -
線形回帰モデルの種類と簡単な解説
線形回帰の種類をわかりやすく解説。 線形回帰とは? 線形回帰の線形の由来は、線形結合からきている。 線形結合とは、以下のような式で表されることを意味している。 $$ \beta_1 X_1 + \beta_2 X_2 + \dots + \beta_n X_n $$ ここで β は (偏) 回帰係数の... -
AICとBICの違いは何か?統計解析での特徴比較
統計モデルの当てはまりの指標である、AICとBIC。 違いは何か? AICやBICとは何か? AICは、Akaike's Information Criterion 赤池情報量規準の頭文字語、BICは、Bayesian Information Criterion ベイズ情報量規準の頭文字語である。 AICもBICも予測性能に... -
決定係数の目安 ― 決定係数 R 2 乗値はいくつならよいか?
重回帰分析の当てはまりの良さを示す決定係数。 決定係数はR2乗値ともいう。 決定係数の目安はあるのだろうか? ゼロから1の範囲をとるわけだが、いくつなら良いのか? 決定係数の目安は? 決定係数は、重回帰分析の当てはまりの良さ、適合度の良さとして... -
クラスカルウォリス検定とマンホイットニーの U 検定は何を検定しているか
ノンパラメトリック検定の場合、平均値の差を使っているわけではないが、では何の検定なのか? クラスカルウォリス検定は何の差を見ているのか? クラスカルウォリス検定は、3群以上の連続量を比較するノンパラメトリック検定である。 クラスカルウォリス... -
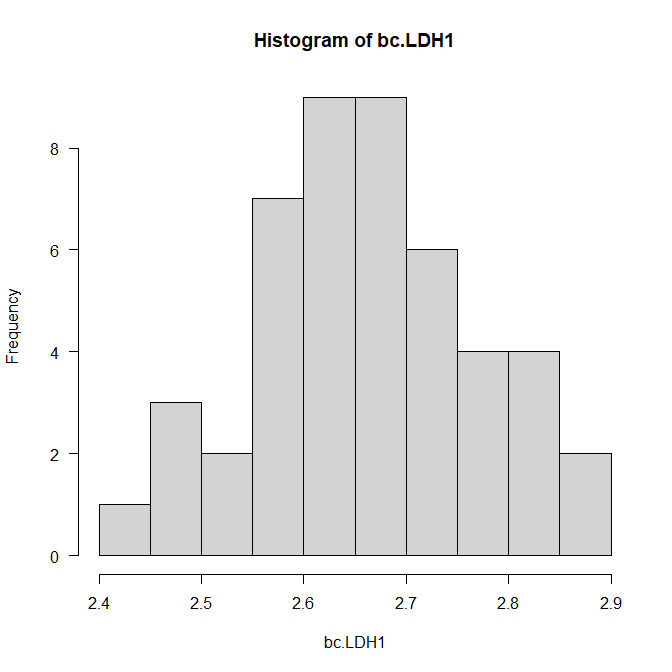
R で Box-Cox 変換を行う方法
連続量を何らかの方法で正規分布に近づける方法はいくつかある。 ここではBox-Cox変換の方法をまとめてみた。 R で Box-Cox変換を行う実例 まず、car パッケージを呼び出す。 library(car) car パッケージの中の、powerTransform()とbcpower()を使って変換... -
EZR でフォント・フォントサイズの変更と EZR 自動起動の設定方法
EZR のフォントやフォントサイズを変更するにはどうやったらいいか。 EZRの起動時フォントなどはオプションから設定する EZRの起動時フォントなどはメニューバーの「ツール」→「オプション」から変更する。 EZRのオプション画面のフォントタブでフォントと... -
尤度とは?わかりやすく解説
読み方も意味しているところも分かりにくい尤度(ゆうど)。 わかりやすく解説。 尤度と似ている確率とは何か? まず尤度は確率に似ているものだが、確率とは違う。 まず確率とは何かを、尤度との対比になるような説明を紹介したい。 統計学で考える場合、... -
R のパッケージを source からインストールする方法
R はパッケージを追加すると新しい機能が追加できる。 その方法もとても簡単だ。 R のパッケージの追加方法として source からインストールする方法があるので、その解説。 R のパッケージを source からインストールする方法 R のパッケージは、Windows用... -
多変量解析の変数選択は統計的にどうやるのか
多変量モデルの変数選択について、悩まない人はいない。 どの変数を採用してどの変数を採用しないのか。 明確な基準はあるのか? 想定している多変量モデルは? 多変量モデルは、多変量解析のモデル(もしくは型)を指している。 独立変数に多数の変数を使... -
サポートベクターマシンとは?ごく簡単に解説
機械学習の分類手法の一つ、サポートベクターマシンとは何か? サポートベクターマシンの前に最大マージン分類器について サポートベクターマシンを説明する前に最大マージン分類器から話を始めねばならない。 最大マージン分類器、サポートベクター分類器... -
ランダムフォレストとバギングの違い
ランダムフォレストとバギングは、決定木をより汎用化するために考えられた手法。 違いは何か? 概念的な簡単な説明。 ランダムフォレストとバギングの総称 アンサンブル学習とは何か? ランダムフォレストとバギングはともにアンサンブル学習と呼ばれてい... -
決定木の過学習を防ぐ剪定(枝刈り)とは?
決定木には剪定(せんてい)という過程がある。 剪定とは何か? 簡単に紹介。 決定木の弱点 過学習 あるデータセットから、決定木を作ったとする。 決定木は、大きく茂らせれば茂らせるほど、きれいに分岐して、分類してくれる。 しかしながら、機械学習... -
機械学習の決定木分析に計算される Gini 不純度とは? わかりやすく解説
決定木の分岐(ノード)を作るときどのような計算をしているのか? Gini不純度を計算しているのだが、Gini不純度とは何か? 機械学習の決定木における Gini 不純度とは? Gini不純度とは、ある特徴でデータを2分割するときに、特徴の要素Aである確率とAで... -
機械学習による決定木分析 ごく簡単な解説
機械学習をする方法はさまざまある。 代表的な方法は決定木分析である。 そもそも決定木とは何か? 基本的なことをごく簡単に解説。 決定木とは何か? 決定木とは意思決定に使う、いくつもの枝分かれをする図のこと。 膨大なデータを使って、決定木のモデ... -
R で割合を計算する方法
R でカテゴリデータを集計して、割合を計算する方法。 R で割合を計算する方法 カテゴリデータの集計の方法 もっとも使うのがtable()。 表(table)形式で集計する関数だ。 例としてMASSパッケージのbirthwtデータフレームを使う。 lowは低体重出生(1)か、そ... -
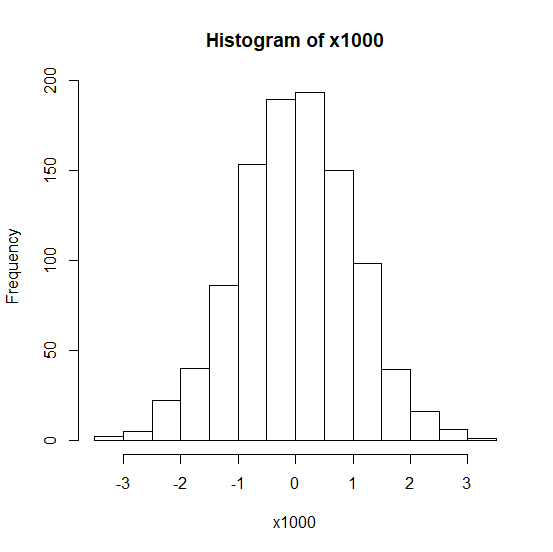
R で skewness や kurtosis を計算する方法
R で skewness や kurtosis を計算する方法。 平均と標準偏差 統計ソフトRで、平均値は、mean()で算出する。 標準偏差は、sd()で計算する。 sdはstandard deviationの略。 平均値と標準偏差の値の関係で、データの分布を大まかに推測できる。 平均値が標準... -
R の attach の使い方
R の attach とはどんな関数か? データフレームとは? R の中で、データフレームとは、データの一つの塊を言っている。 それも、変数名がついて、何列かのデータのことだ。 エクセルで言えば、A、B、Cと列が並んでいるところに、 Aには、年齢 Bには、性別... -
R のライブラリとは
R でlibrary() ライブラリ はよく使う関数だ。 ライブラリとは? ライブラリの定義 ライブラリは、辞書の定義だと、 〔コンピュータ〕ライブラリー: プログラムやデータなどをひとまとまりに登録したファイル. 出典:Progressive English-Japanese Diction... -
R にパッケージをインストールする方法
Rは、最初からかなりいろいろなことができる無料統計ソフト。 もっとすごいのは、あとからパッケージをインストールして、さらにいろいろな解析ができるようになること。 R は追加パッケージをインストールする前からすごい! まず、新しいパッケージをイ... -
R の引用情報を参考文献リストに載せたいときの書き方
R の引用情報を参考文献リストに載せたい。 どのように記載すればよいか? R の引用情報の取得方法 コンソールで citation() と書いてエンター。 引用の際の情報が出てくる。 例: To cite R in publications use: R Core Team (2018). R: A language and ... -
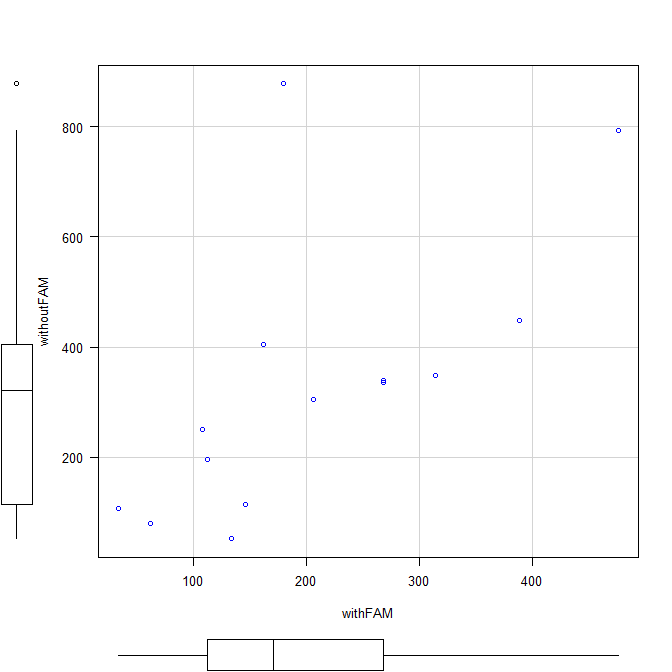
サンプル数が大きく異なる群間比較の妥当性
臨床研究では、比較的まれな疾患の患者さんのデータと、その疾患を持たない対照群のデータを比較しようとすると、両グループの人数が大きく異なることがよくある。これは、まれな疾患ではそもそもデータが集まりにくいという現実があるためだ。 このように... -
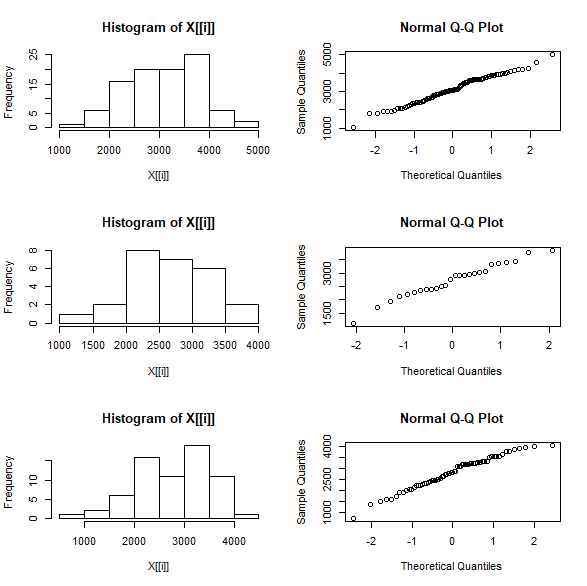
R で QQ プロットを書く方法
正規確率プロット QQプロット は、正規分布をしているかどうか、目視で確認するための方法。 図で正規分布のチェック qqnorm()を使う。 正規確率プロットを描く。 x軸が正規分布の論理的な分位数、y軸が実測値の分位数。 対角線上にまっすぐに、プロットが... -
R で連続データの 2 群比較を行う方法
実験群とコントロール群、リスク因子あり群となし群、介入群と非介入群、など二群比較 を R で実行する方法。 群ごとに平均値・標準偏差・中央値を求める 平均値を計算するなら tapply(var1, grp, mean) を使用する。 grpのグループごとに、var1の平均値を... -
R で正規分布のパーセンタイルを計算する方法
平均70点、標準偏差15点のテストの場合、90点以上の学生は上位何パーセントに当たるか? という問題に使うパーセンタイル percentile とクォンタイル quantile。 それぞれ百分位数と分位数ともいわれる。 パーセンタイルを求めるには? pnorm()を使う。 母...

1