R– category –
-

R で相関係数のメタアナリシスを行う方法
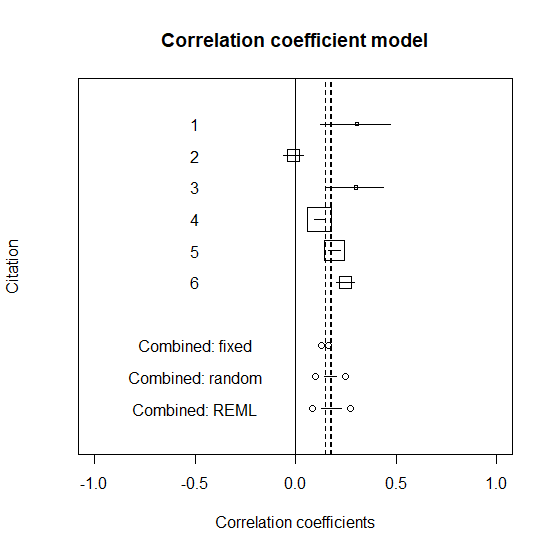
相関係数を統合したい場合はどうやるか? R での方法。 個々の研究の相関係数と95%信頼区間の準備 使うデータは以下の通り。 r が相関係数。 n がサンプルサイズ。 r <- c(0.307,-0.01,0.300,0.119,0.194,0.248) n <- c(107,1524,154,6165,4138,1559... -
R で相関係数検定の実行と信頼区間を計算する方法
R で相関係数の検定と推定は cor.test() でできるが、個々のデータが必要だ。 個々のデータを使わなくても、検定や推定はできないだろうか? 相関係数の検定 母相関係数 ρ(ロー) がゼロかどうかの検定。 スクリプトは以下の通り。 r がサンプルの相関係... -
R で平均値の差のメタ解析を行う方法
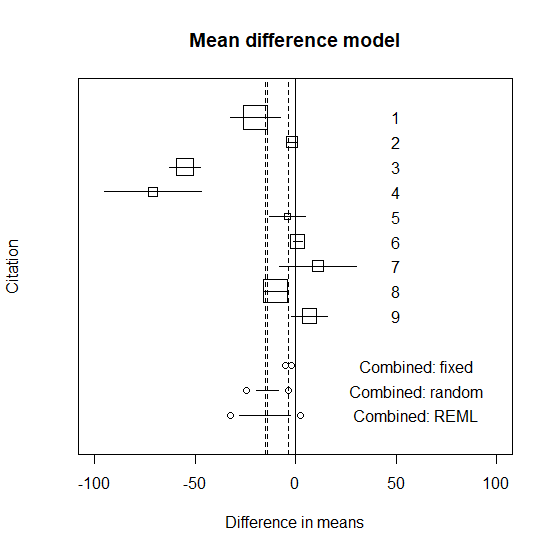
平均値の差のメタ解析のやり方を解説。 メタ解析のやり方解説のためのサンプルデータ メタ解析のやり方を解説するためのデータは以下の通り。 mが平均、sが標準偏差、nがサンプルサイズ。 n1 <- c(155,31,75,18,8,57,34,110,60) m1 <- c(55.0,27.0,6... -
R と MeCab でテキストマイニングを行う方法
Rでテキストマイニングするやり方。 MeCab と RMeCab を使う方法。 例として、ワードクラウドを描く方法を紹介。 テキストマイニングとは? テキストデータを名詞、動詞、形容詞など、濃い意味合いを持つ言葉と、助詞、助動詞、感嘆詞、疑問詞など意味合い... -
R で主成分回帰と部分的最小二乗回帰を実行する方法
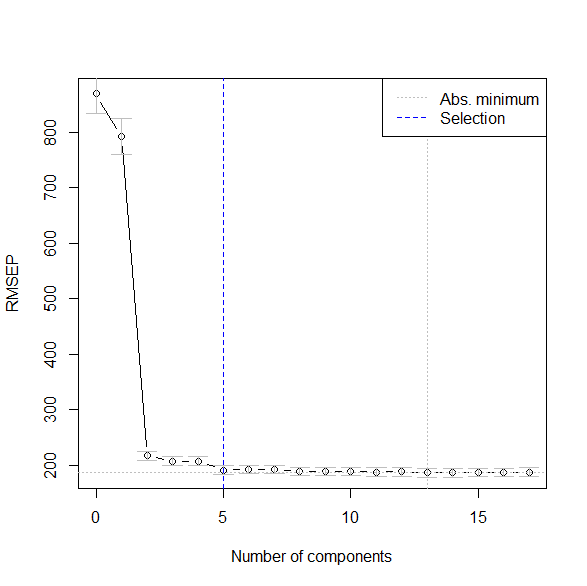
主成分回帰と部分的最小二乗回帰を R で実行する方法の解説 部分的最小二乗回帰とは 部分的最小二乗回帰の前に、主成分回帰を説明する。 主成分回帰(Principal Component Regression, PCR)は、主成分分析と回帰分析の融合。 主成分分析で情報の集約をし... -
R で主成分分析を行う方法
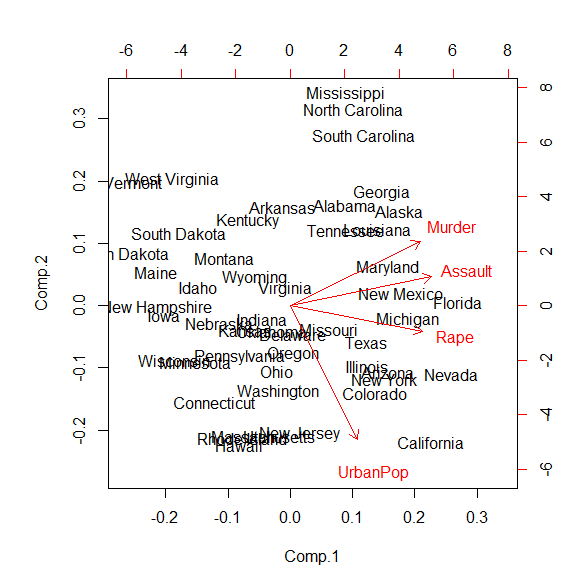
主成分分析は、たくさんの変数を、合成変数に集約する分析。 主役級の主成分から第一主成分、第二主成分、・・・と呼ばれる。 たくさんの変数を、いくつかの主成分でまとめると、情報がまとまって考えやすくなる。 Rで主成分分析を行う方法 princomp()を使... -
R でリッジ回帰・ラッソ回帰・エラスティックネットを実行する方法
エラスティックネットを簡単に解説 R で実行する方法も解説 リッジ・ラッソ・エラスティックネットとは? 線形回帰モデルは、係数 β(パラメータ)を推定するときに最小二乗法を用いる。 通常の最小二乗法は、従属変数の実測値とモデルから計算された値と... -
R で SVM の C パラメータについて具体例を示す
SVM(サポートベクターマシン)のコストパラメータ C について。 SVM の C とは? SVM(サポートベクターマシン)のコストパラメータ C とは何か? コストパラメータ C は誤分類を許容する指標。 C が小さいと誤分類を許容する。 大きいと誤分類を許容しな... -
R でランダムフォレストを最適化する方法
ランダムフォレストはチューニングして最適化する。 チューニングは決定木を最適化する方法。 ランダムフォレストの場合は、決定木の数と特徴量(説明変数)の数を最適化する。 ランダムフォレストのパッケージのインストールと準備 最初に一回だけパッケ... -
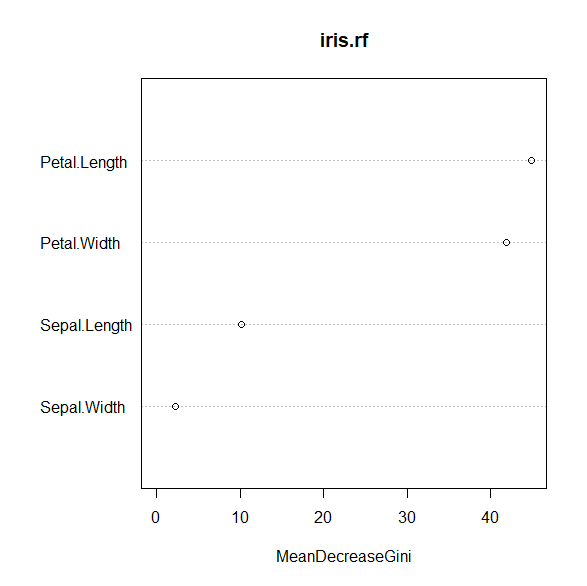
R でランダムフォレストを行う方法 重要度の可視化の方法
R でランダムフォレストを実行する方法。 ランダムフォレストとバギングの違い ランダムフォレストとバギングの違いは、こちらの記事を参照。 R でランダムフォレストを実行するパッケージの準備 パッケージはrandomForestというそのままの名前のパッケー...