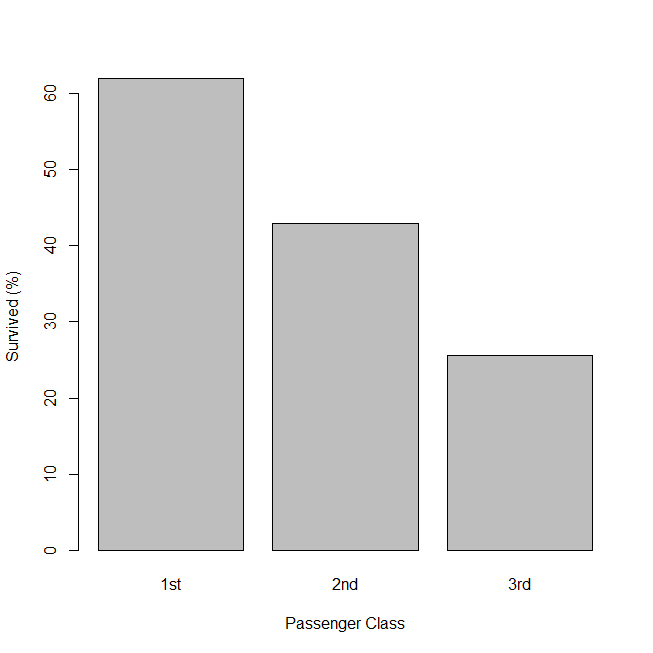R– category –
-

R で分散分析に必要なサンプル数を pwr.anova.test() で計算する方法
分散分析のサンプルサイズ計算を統計ソフトRで行う方法を解説。 分散分析は三群以上の平均値を比較する分析方法。 少なくともどれか一つの群がほかの群とは異なることを証明するための分析方法だ。 分散分析のサンプルサイズ計算を行うために必要なデータ ... -
R と SPSS でウェルチの t 検定を実行する方法
ウェルチの t 検定は、2 群が等分散でも等分散でなくても使える t 検定 R と SPSS での実行方法 ウェルチの t 検定とは? ウェルチ (Welch) の t 検定は、二つのサンプルの母分散が等分散とは仮定できないときにも適切に比較できる平均値の差の検定だ。 等... -
R でサポートベクターマシンを実行する方法
サポートベクターマシンを R で実装する方法について。 サポートベクターマシンとは? サポートベクターマシンについては、過去記事参照。 サポートベクターマシンを R で実装するのに必要なパッケージ e1071パッケージを使う。 まず最初一回インストール... -
R で割合の差の検定に必要なサンプルサイズを計算する方法
割合の差の検定のサンプルサイズ計算を R で行う方法、エクセルで行う方法 割合の差の検定のサンプルサイズ計算 R の関数を使って 統計ソフトRには、power.prop.test()という関数が用意されていて、簡単に計算できる。 第1群が50%(0.5)、第2群が75%(0.75)... -
R で クロッパーピアソンの割合の信頼区間を計算する方法
正規分布近似を用いた信頼区間とClopper-Pearson 信頼区間を計算する方法。 割合の区間推定(正規分布近似を用いた簡易的な方法) 割合の分散は、割合をp、サンプルサイズをnとすると、 $$ \frac{p (1 - p)}{n} $$ で計算できる。 標準誤差はその平方根で... -
R のパッケージを source からインストールする方法
R はパッケージを追加すると新しい機能が追加できる。 その方法もとても簡単だ。 R のパッケージの追加方法として source からインストールする方法があるので、その解説。 R のパッケージを source からインストールする方法 R のパッケージは、Windows用... -
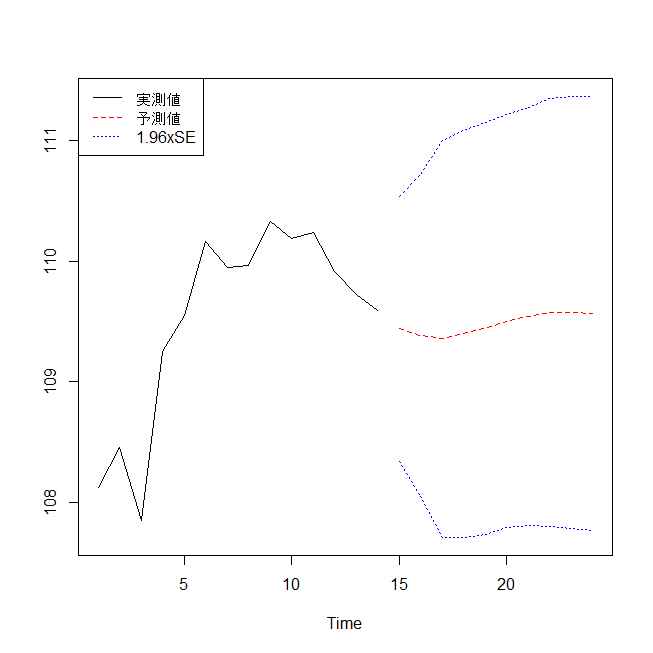
R で時系列データ分析を行う方法
R で時系列データを分析するための基礎的な方法の解説。 時系列データとは何か? 時系列データとは、日時のデータと値のデータのペアのこと。 例としては、 四半期ごとの売上高。 毎月の経費。 週当たりの納入量。 毎日の株価・ドル円レート。 など。 こう... -
R で多重比較に必要となるサンプルサイズを計算する方法
多重比較のサンプルサイズ計算を R で行う方法 ボンフェローニ型 多重比較のサンプルサイズ計算 Bonferroni(ボンフェローニ)型多重比較とは、比較する数で有意水準を割って、割った有意水準より小さい有意確率の場合、統計学的有意と考える方法。 三群あ... -
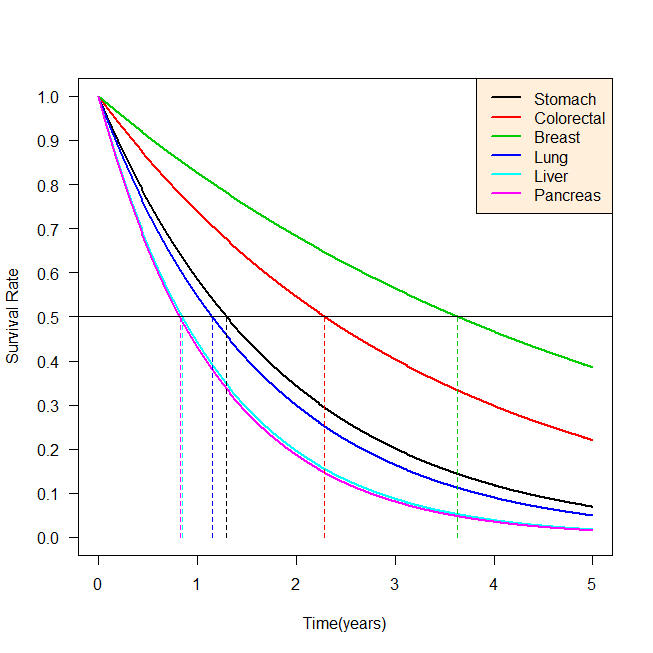
R で 5 年生存率から逆算で生存期間中央値を求める方法
がん患者さんの生存期間中央値を5年生存率から逆算で求めるにはどうしたらよいか? R で計算する方法。 5 年生存率から逆算で生存期間中央値を求める計算式 生存確率は、一般論として指数関数で近似できる。 実際には、がんの治療後すぐになくなったり、数... -
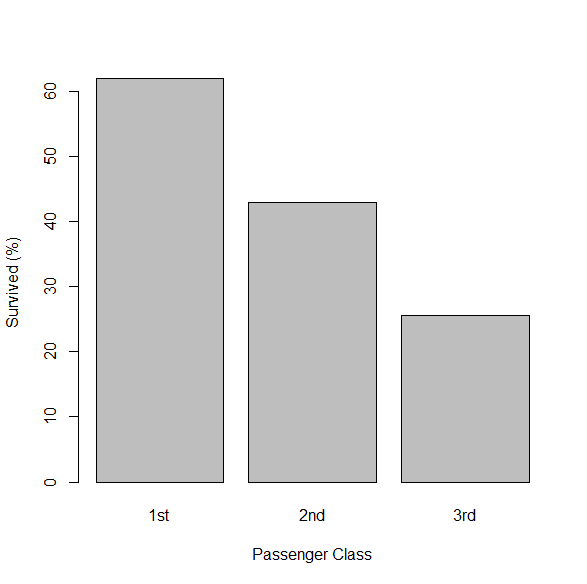
R でロジスティック回帰分析と傾向検定・多重比較を行う方法
R に組み込みのタイタニック号の生存・死亡データで、生存・死亡に関するロジスティック回帰分析と、独立変数の多重比較を実行してみる。 解析するタイタニック号の生存・死亡データの確認 解析するデータは、carData パッケージの TitanicSurvival という... -
R でロジスティック回帰を行う方法
タイタニック号は、1912年4月14日の夜、氷山に激突し、北大西洋の底に1,500名以上の命と一緒に沈んだ。 乗客乗員の生存・死亡のデータを用いて、ロジスティック回帰分析を実行してみる。 タイタニック号の生存・死亡データはどこにあるのか? R はインスト... -
R で相関係数と偏相関係数の違いについて ピアソンとスピアマンの両方について
相関係数は、相関関係の強さを示す指標。 一方が大きいときにもう一方が大きければ、正の相関関係で、相関係数は1に近い。 一方が大きいときにもう一方が小さい場合は、負の相関関係で相関係数は-1に近い。 では、偏相関係数とは何か? 違いは何か? 偏相... -
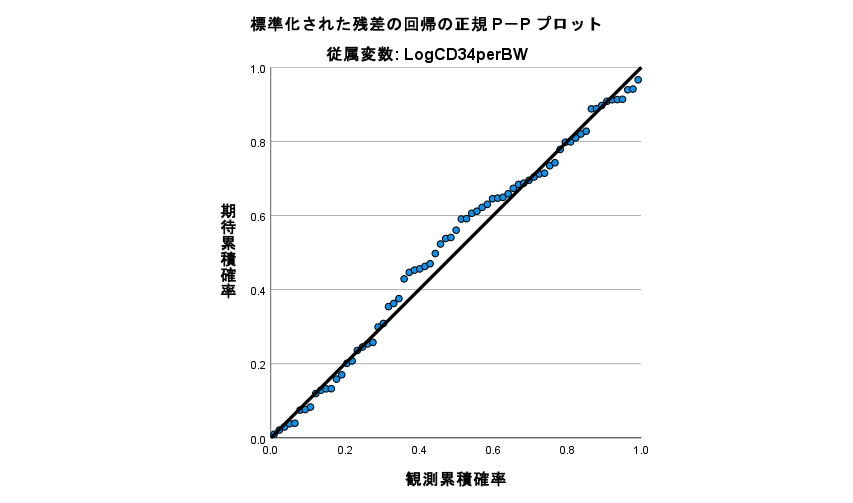
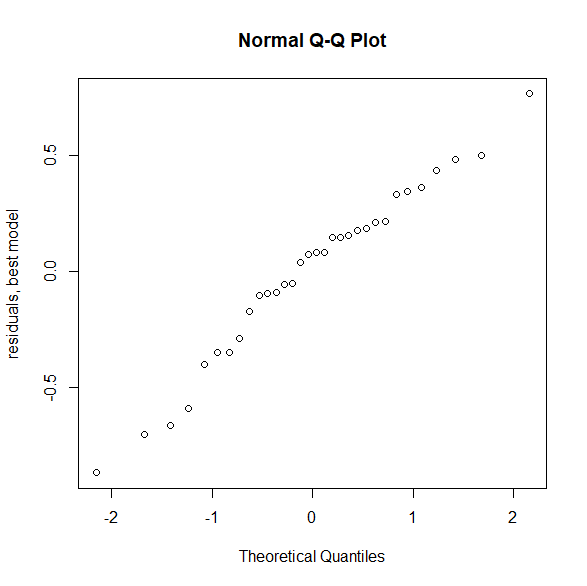
R と SPSS で重回帰分析の残差が正規分布であるのを確認する方法
回帰分析をする際に、説明変数や目的変数が正規分布をしていないことで悩んでいる人は多い。 悩むところはそこじゃない。 重回帰分析では、残差が正規分布している必要がある。 重回帰分析の前提は何か? 重回帰分析の前提は4つある。 独立性(データそれ... -
t 検定と分散分析と回帰分析は同じことをしている
分散分析と回帰分析とt検定は同じものである。 これがわかれば、重回帰分析(共分散分析)が交絡因子調整した群間比較に使われる理由がわかるだろう。 t検定は回帰分析でもできるし、分散分析は二群でもできる ここで、t検定は、いわゆる t 検定のこと... -
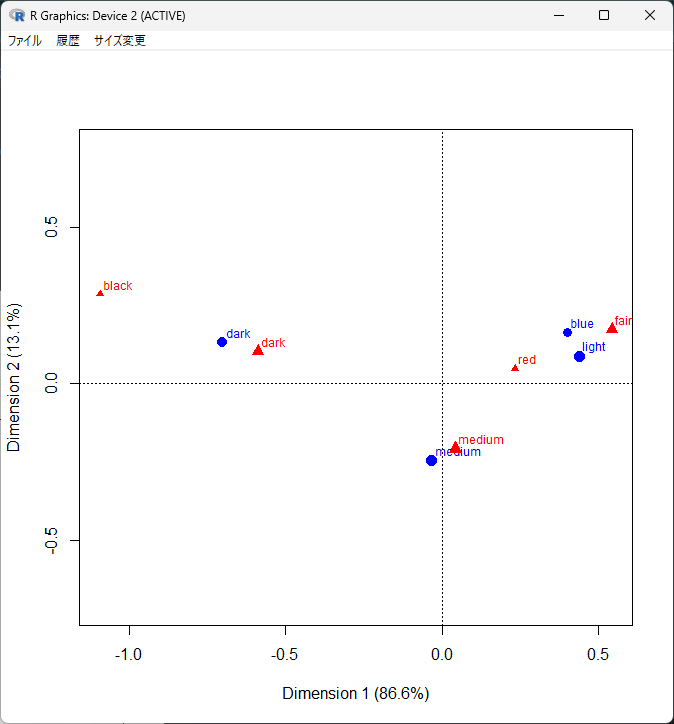
R でコレスポンデンス分析の計算を Step by Step で確認する
コレスポンデンス分析(対応分析とも言う) は、大きな分割表に集計されたデータを見やすくする分析方法。 二次元 つまり X軸とY軸に変換して、散布図にして傾向を見る。 コレスポンデンス分析とは? コレスポンデンス分析とは、対応分析とも呼ばれ、分割... -
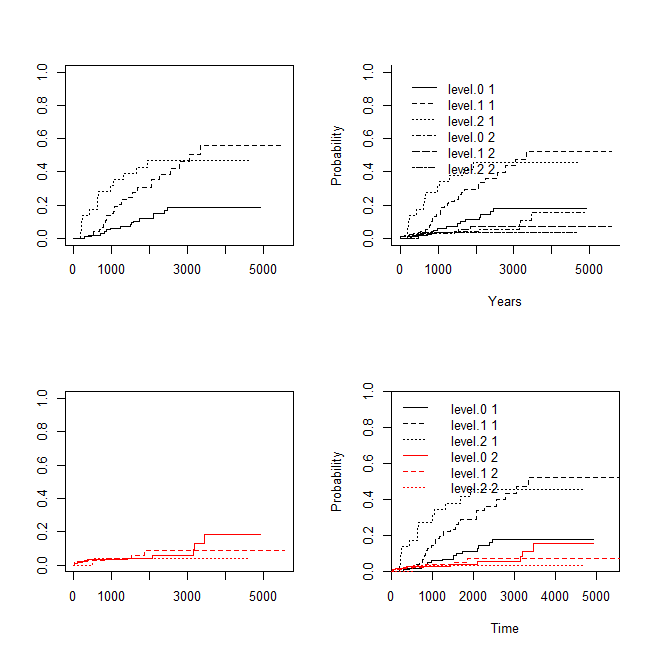
R で競合リスク回帰を実行する方法
競合リスク回帰とは、共変量調整をした競合リスク分析の方法。 競合リスク回帰の前に競合リスクとは? 競合リスクについては、以下を参照。 競合リスク回帰の種類 競合リスク回帰モデルには四つ考えられる。 絶対リスク回帰 Absolute Risk Regression ロジ... -
R で競合リスク分析 Gray 検定を行う方法
競合リスクとは何か? Gray 検定の実行方法 競合リスクとは? 再発がエンドポイントであったが、再発する前に死亡してしまったので、観察できなかった。 脳梗塞の発現がエンドポイントだったが、先に肺炎でお亡くなりになり、観察できなかった。 このよう... -
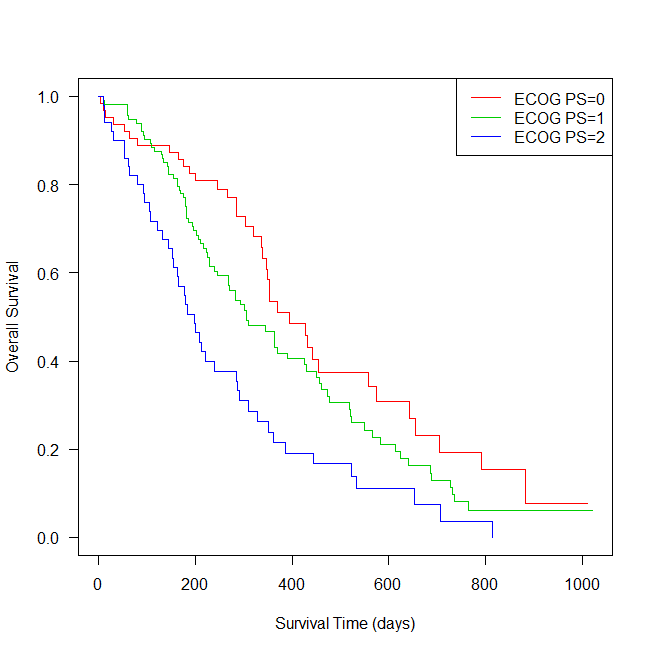
R で生存時間データを分析する方法
Coxの比例ハザードモデル(コックスの比例ハザードモデル、Cox回帰、コックス回帰など表示・呼び名はたくさんあるが皆同じものを指している)は、生存時間とイベントデータを多変量解析できる統計モデルだ。 注目したい要因が、他の要因と相関があり、また... -
R でログランク検定を行う方法
ログランク検定とは、生存時間解析で、二群以上のグループがある場合に、グループ間で統計学的に差があるかを検討する方法。 R での方法を解説。 R でログランク検定をする場合の関数は? R でログランク検定をする場合、survival パッケージのsurvdiff()... -
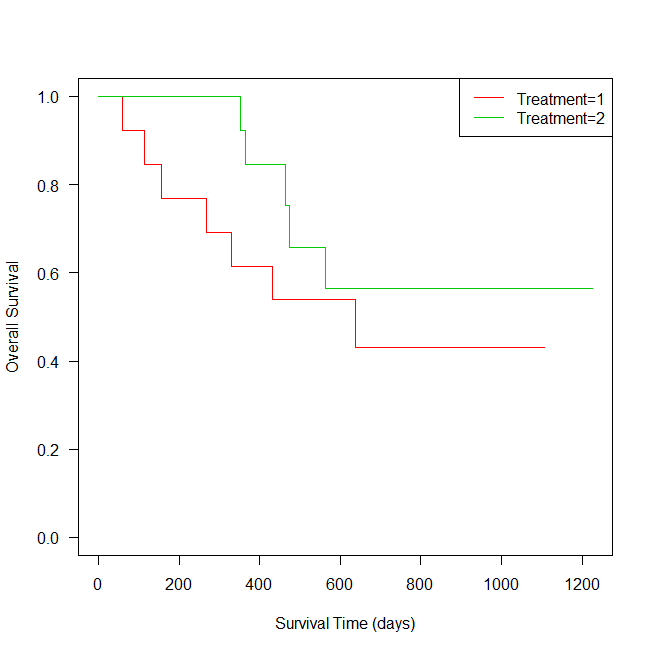
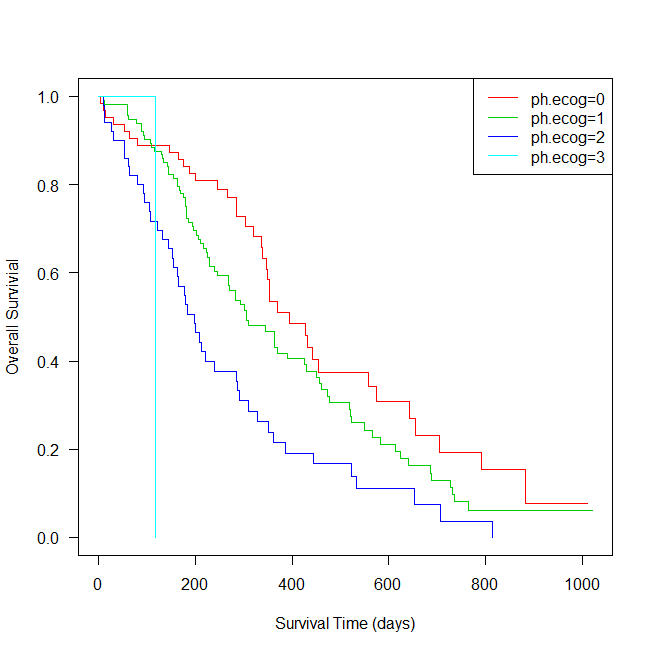
R でカプランマイヤー曲線をグループごとに書く方法
Rでカプランマイヤー曲線を書く方法の紹介。 survfit を使ったグループごとの曲線の書き方。 Rでカプランマイヤー曲線を書くためのサンプルデータ カプランマイヤー曲線を書くためのサンプルデータは、survival パッケージの lung を使う。 これは、North ... -
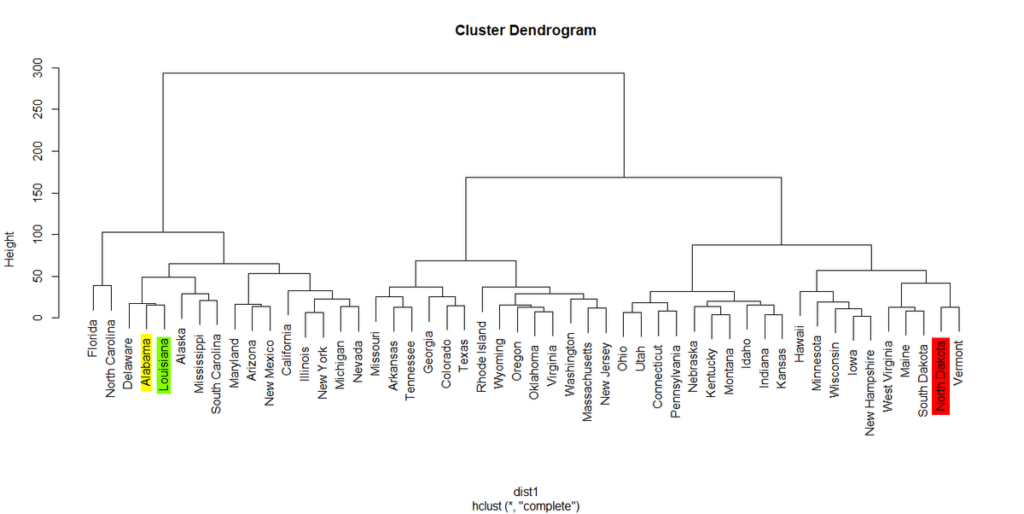
R で階層的クラスタリングを行う方法
R で階層的クラスタリングを行う方法。 階層的クラスタリングとは さまざまな特徴を持った集団、たとえば米国50州を、特徴が似ている似ていないで近い・遠いを表現して部分集団(クラスター)に分けることを言う。 以下も参照のこと。 階層的クラスタリン... -
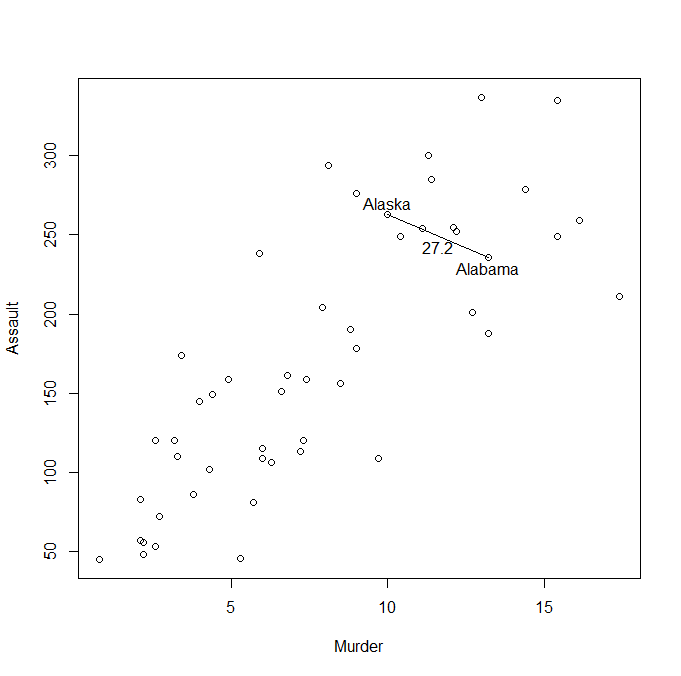
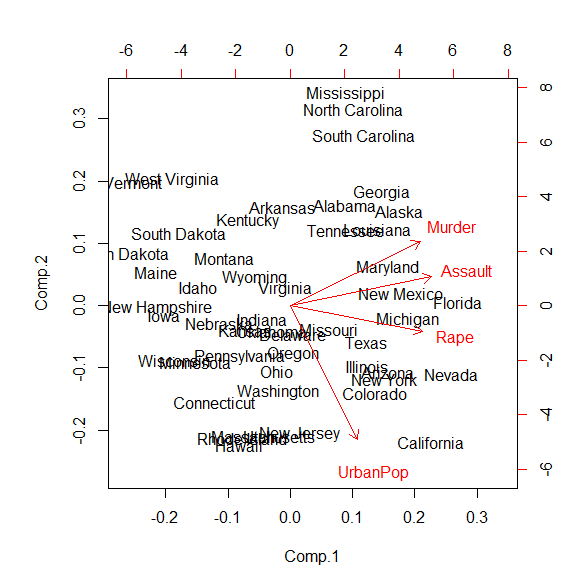
R でユークリッド距離を二次元で表示してみた
二次元でユークリッド距離を図示してみた。 二次元のユークリッド距離を示すサンプルデータ 二次元でユークリッド距離を例示してみるためのサンプルデータは、R に組み込まれているUSArrestsというデータを使う。 USArrestsの1列目 Murderと2列目 Assault... -
R でユークリッド距離を求める方法
ユークリッドは紀元前325年に生まれたギリシャの数学者。 著した著書は数学のなかでも特に幾何学の教科書として有名であった。 ユークリッドが考え出した「距離」とは? ユークリッド距離とは? ユークリッド距離は、幾何学で扱う事項である。 幾何学とは... -
R で 3 人以上の評価者のカッパ係数 フライスのカッパ係数を計算する方法
フライス(Fleiss)のカッパ係数(kappa)は、3人以上の評価者の評価が一致している度合いを測定する係数。 カッパ係数には 2 人の場合と 3 人以上の場合の 2 種類がある Cohen's kappa が二人の評価者の一致度を判断するのに対して、Fleiss' kappa は三人... -
R でカッパ係数を計算する方法
二人の評価者のカテゴリ評価の一致度を見るのがいわゆるカッパ係数だ。 カッパはギリシャ文字のkのカッパ(κ)のこと。 Jacob Cohen先生が発明したので、Cohen's Kappaと呼ばれる。 これを R で計算してみようと思う。 irr パッケージを使う方法 簡単な方... -
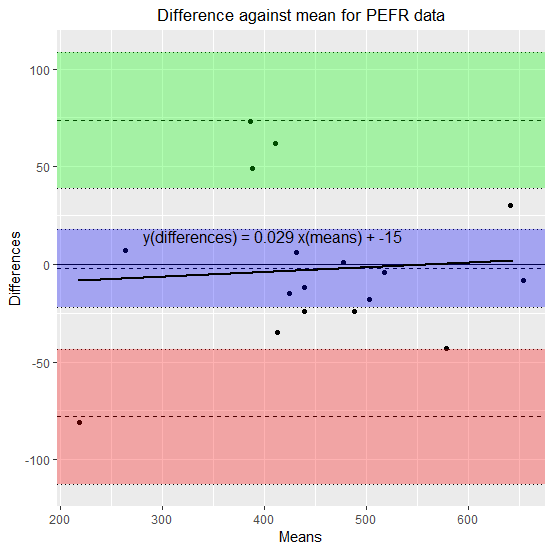
R でブランド アルトマン 分析を行う方法
ブランド アルトマン 分析は、二つの測定系の結果が一致しているかどうかを確認する方法。 ブランド アルトマン プロットに、回帰直線を合わせると不一致に傾向がないかどうか確認できる。 ブランドアルトマン分析の準備 ブランドアルトマンプロットは、2... -
R でウィルソンのスコア法よる信頼区間を計算する方法
点推定値が100%に近いとき、より適切に割合の信頼区間を計算する方法 Wilson's score method(ウィルソンのスコア法)の解説。 割合の信頼区間は近似を使っている 割合の信頼区間は以下の式で計算できる。 これは正規分布を近似的に使っている。 $$ \hat{p... -
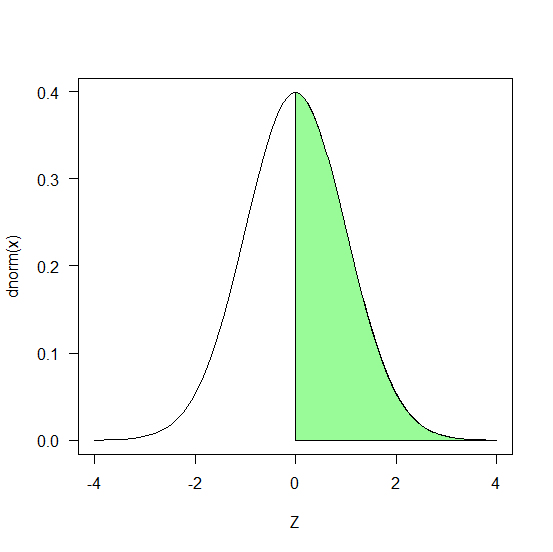
R でグラフを描いてグラフの一部を塗りつぶす方法
グラフを描いた後、一部を塗りつぶしたいときがある。 そんなときにどうしたらいいか? 標準正規分布の場合 確率分布の一部を塗りつぶしたい場合、以下のようにすれば可能。 # 前半 curve(dnorm(x), -4, 4, las=1, xlab="Z") arrows(0,0,0,dnorm(0),length... -
R で一元配置分散分析を行う方法
Rで、一元配置分散分析を step by step で計算してみた。 lm() と Anova() を使えばあっという間だが、具体的な一つ一つの計算を自分で組み立ててみるとどうか? 教科書の例題に沿って確認した。 R で一元配置分散分析を実行するための例題データ サンプル... -
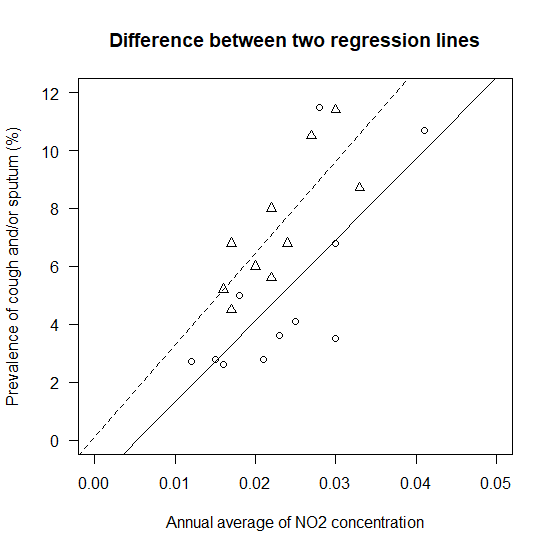
R で回帰直線の差の検定を行う方法
二つのデータセットがあって、二つの回帰直線が描けたとき、そのあとどうすればいいか? そのあとは、傾きが同じと言えるか?さらには切片が同じと言えるか?と進んでいく。 二つの回帰直線の差を検定してみる。 回帰直線の差の検定のためのサンプルデータ... -
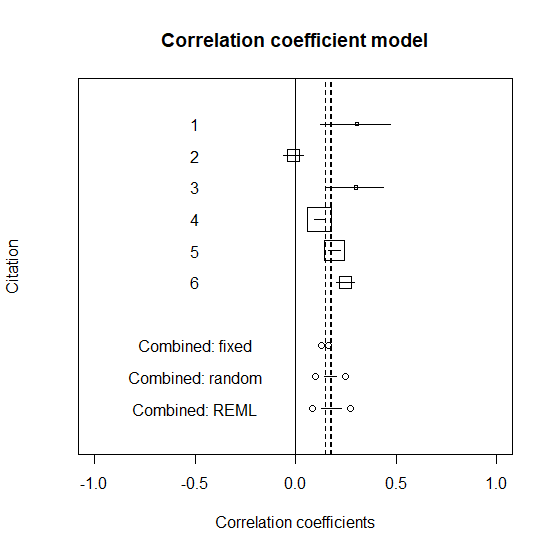
R で相関係数のメタアナリシスを行う方法
相関係数を統合したい場合はどうやるか? R での方法。 個々の研究の相関係数と95%信頼区間の準備 使うデータは以下の通り。 r が相関係数。 n がサンプルサイズ。 r <- c(0.307,-0.01,0.300,0.119,0.194,0.248) n <- c(107,1524,154,6165,4138,1559... -
R で相関係数検定の実行と信頼区間を計算する方法
R で相関係数の検定と推定は cor.test() でできるが、個々のデータが必要だ。 個々のデータを使わなくても、検定や推定はできないだろうか? 相関係数の検定 母相関係数 ρ(ロー) がゼロかどうかの検定。 スクリプトは以下の通り。 r がサンプルの相関係... -
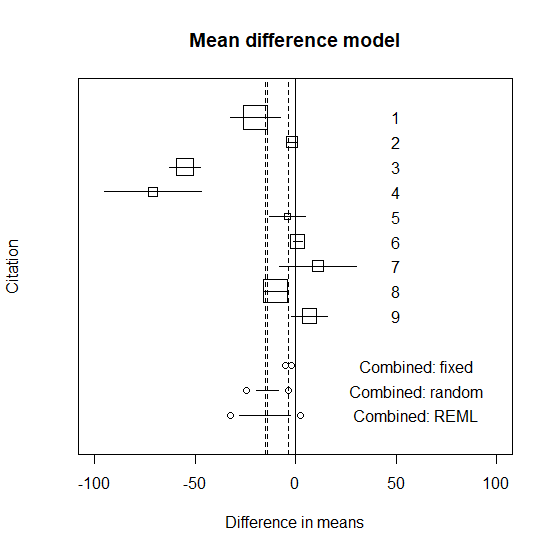
R で平均値の差のメタ解析を行う方法
平均値の差のメタ解析のやり方を解説。 メタ解析のやり方解説のためのサンプルデータ メタ解析のやり方を解説するためのデータは以下の通り。 mが平均、sが標準偏差、nがサンプルサイズ。 n1 <- c(155,31,75,18,8,57,34,110,60) m1 <- c(55.0,27.0,6... -
R と MeCab でテキストマイニングを行う方法
Rでテキストマイニングするやり方。 MeCab と RMeCab を使う方法。 例として、ワードクラウドを描く方法を紹介。 テキストマイニングとは? テキストデータを名詞、動詞、形容詞など、濃い意味合いを持つ言葉と、助詞、助動詞、感嘆詞、疑問詞など意味合い... -
R で主成分回帰と部分的最小二乗回帰を実行する方法
主成分回帰と部分的最小二乗回帰を R で実行する方法の解説 部分的最小二乗回帰とは 部分的最小二乗回帰の前に、主成分回帰を説明する。 主成分回帰(Principal Component Regression, PCR)は、主成分分析と回帰分析の融合。 主成分分析で情報の集約をし... -
R で主成分分析を行う方法
主成分分析は、たくさんの変数を、合成変数に集約する分析。 主役級の主成分から第一主成分、第二主成分、・・・と呼ばれる。 たくさんの変数を、いくつかの主成分でまとめると、情報がまとまって考えやすくなる。 Rで主成分分析を行う方法 princomp()を使... -
R でリッジ回帰・ラッソ回帰・エラスティックネットを実行する方法
エラスティックネットを簡単に解説 R で実行する方法も解説 リッジ・ラッソ・エラスティックネットとは? 線形回帰モデルは、係数 β(パラメータ)を推定するときに最小二乗法を用いる。 通常の最小二乗法は、従属変数の実測値とモデルから計算された値と... -
R で SVM の C パラメータについて具体例を示す
SVM(サポートベクターマシン)のコストパラメータ C について。 SVM の C とは? SVM(サポートベクターマシン)のコストパラメータ C とは何か? コストパラメータ C は誤分類を許容する指標。 C が小さいと誤分類を許容する。 大きいと誤分類を許容しな... -
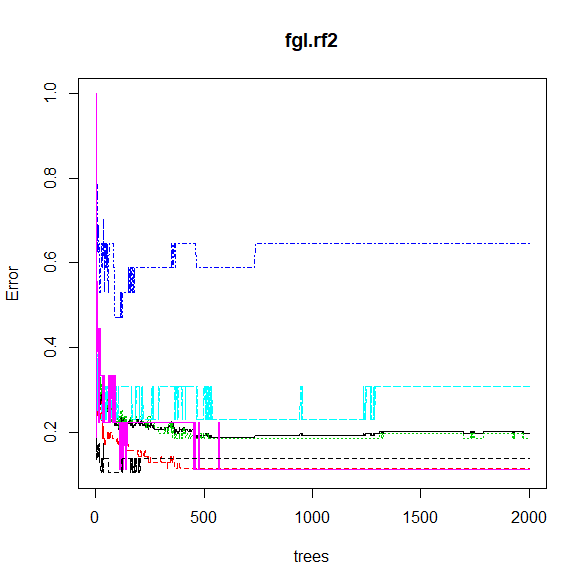
R でランダムフォレストを最適化する方法
ランダムフォレストはチューニングして最適化する。 チューニングは決定木を最適化する方法。 ランダムフォレストの場合は、決定木の数と特徴量(説明変数)の数を最適化する。 ランダムフォレストのパッケージのインストールと準備 最初に一回だけパッケ... -
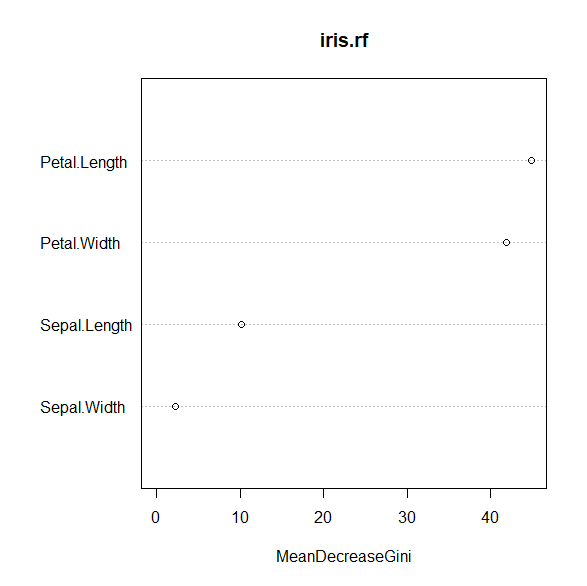
R でランダムフォレストを行う方法 重要度の可視化の方法
R でランダムフォレストを実行する方法。 ランダムフォレストとバギングの違い ランダムフォレストとバギングの違いは、こちらの記事を参照。 R でランダムフォレストを実行するパッケージの準備 パッケージはrandomForestというそのままの名前のパッケー... -
R でアンサンブル学習のバギングを行う方法
バギングというアンサンブル学習を R でやってみる。 ランダムフォレストとバギングの違い ランダムフォレストとバギングの違いは、以下の記事を参照。 バギングのための R パッケージの準備 adabagパッケージをインストールする。 install.packages("adab... -
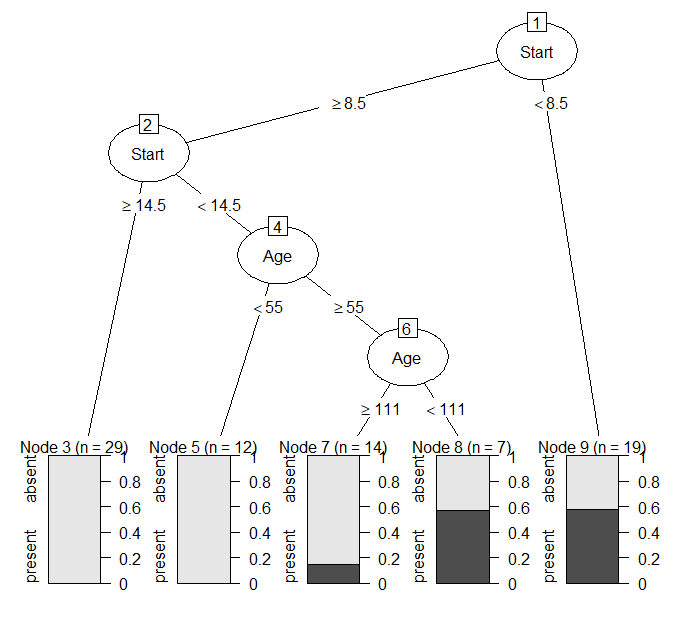
R partykit で決定木分析を実行する方法
決定木分析をRで行う方法を紹介。 難しいプログラムが組めなくてもすぐに使える。 決定木分析のRパッケージの準備 決定木分析のパッケージrpartときれいな決定木の描画パッケージpartykitをインストールする。 インストールは初めの一回だけでOK。 install... -
R で分類課題を機械学習モデルで実行する方法
機械学習で、よりよく推測できるモデルを選ぶ。 統計ソフトRのISLRパッケージのWeeklyデータで基礎的な機械学習を行ってみた。 Rで機械学習を行うためデータの準備 ISLRパッケージのWeeklyデータは、S&P500指数の週当たりのリターンのデータ。 9つの変... -
R で重回帰分析を行う具体例 ― ISLR パッケージ Auto データセットを使った重回帰分析
R の ISLR パッケージの Auto データセットを使った分析例。 データの準備 最初の一回だけ、ISLRパッケージをインストール。 install.packages("ISLR") ISLRパッケージを呼び出して、解析開始。 library(ISLR) ISLRパッケージのAutoデータセットを用いて解... -
R で NNH Number Needed to Harm を計算する方法
有害必要数(Number Needed to Harm, NNH)は、1人の有害事象が起こる人が出現するのに、何かの影響を受けた人が何人必要かという数。 NNHを計算するにはどうやるか? 使えるシチュエーションは、 曝露Aを受ける人受けない人 処置Bを受ける人受けない人 介... -
R で罹患率比を求める方法
罹患率比の計算は、どうやるのか? R での計算の方法。 罹患・罹患率・罹患率比とは? 罹患(りかん)とは? 罹患とは病気にかかること。 病気にかかったことは、診断によってわかる場合と、発症によってわかる場合がある。 診断とは、外来の診察で下され... -
R でロジスティック回帰分析の変数選択の参考になる計算上ベストな変数セットを提案してくれる方法
Rを使って、 多重ロジスティック回帰分析でBICを使って、 簡単に変数選択ができる。 変数選択の関数の前に BIC とは BICは、 Bayesian Information Criterionの頭文字語。 統計モデルへのあてはまりを検討するときに、 変数が多すぎると評価が下がる規準に... -
R で重回帰分析の変数選択に参考となる計算上ベストな変数セットを提案してくれる方法
R で重回帰分析を行った際の変数選択の方法の解説。 bestglmの準備とサンプルデータ R の bestglm() 関数は、AIC, BIC(デフォルト), BICqなどの Information Criterion 情報規準を使って ベストの変数の組み合わせを見つけてくれる。 bestglmパッケージのz... -
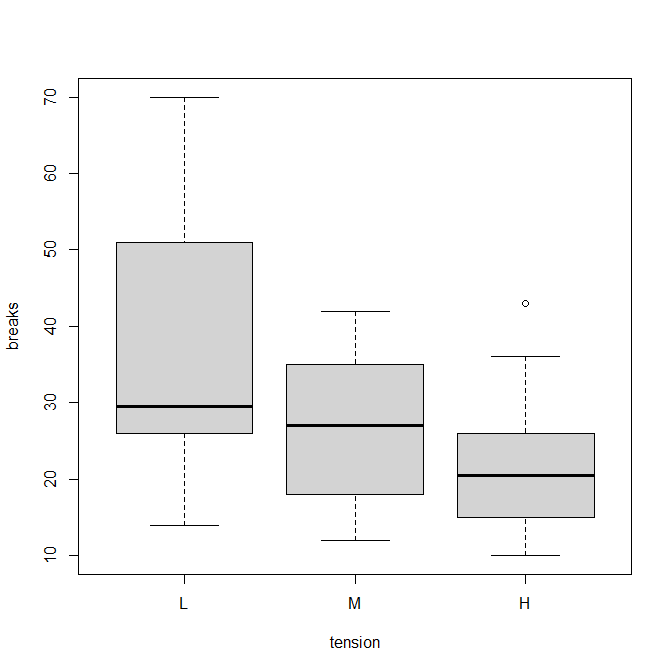
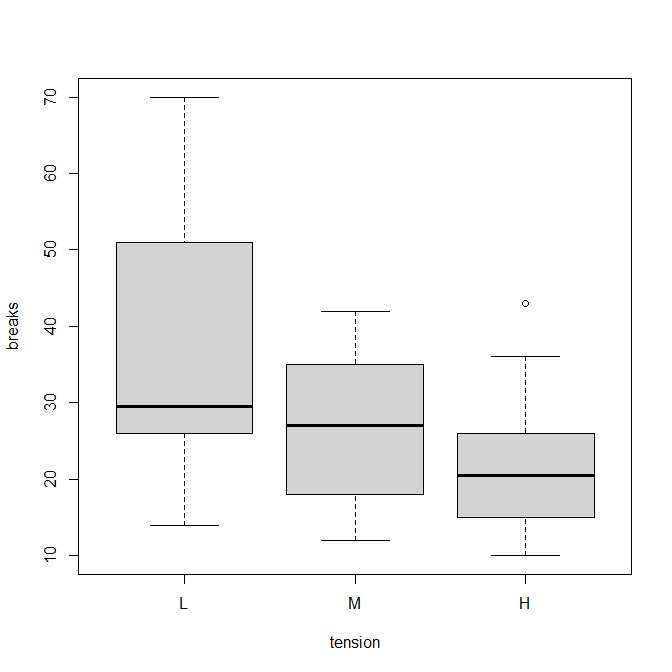
R で箱ひげ図を書く方法
R で箱ひげ図を描くにはどうしたらいいか? R で箱ひげ図を書く関数 R で箱ひげ図を書く関数は、boxplot() 第 1 四分位から第 3 四分位までの箱を描き、その中にある中央値に線を引く。 第 1 四分位と第 3 四分位の差(四分位範囲)の 1.5 倍の線(ひげ)... -
R でログランク検定に必要なサンプルサイズを計算する方法
ログランク検定のサンプルサイズ計算を R で行う方法 ログランク検定はどうやるか? ログランク検定は、時間経過とともにイベントが起きていくデータの群間比較をする方法。 患者さんの死亡をイベントとしたデータ、病気が再発することをイベントとしたデ... -
R で級内相関係数 ICC(2,1) を計算する方法と必要なサンプルサイズを計算する方法
級内相関係数 ICC Case2 の計算とサンプルサイズ計算を R でやってみた 級内相関係数 ICC(2,1) の計算例 級内相関係数 Intra-class Correlation Coefficient Case2 ICC Case2 は検者間信頼性の指標。 患者さんを数名の検査者(または評価者)で検査(また... -
R で級内相関係数 ICC(1,1) に必要なサンプルサイズを計算する方法
ICC(1,1) の計算とサンプルサイズ計算を R で行う方法 級内相関係数 ICC(1,1) の計算 級内相関係数(ICC)は、信頼性指標に使える。 ICC Case1は、一人の検査をする人(検者、けんじゃ)の一貫性を確認する指標だ。 ICC(1,1)は、一人の検者がk回測定を行っ... -
R でトレンド検定に必要なサンプルサイズを計算する方法
トレンド検定のサンプルサイズ計算。 トレンド検定とは トレンドとは、順序カテゴリの小さいほうから大きいほうに移るにつれて、カテゴリの平均値や割合が大きくなるとか小さくなるとか、傾向や相関があることを指す。 トレンドがなく同じというのが帰無仮... -
R でダネット検定に必要なサンプル数を計算する方法
ダネット検定のサンプルサイズ計算を R で行う方法 ダネット検定サンプルサイズ計算スクリプトの前提 ダネット検定とは、コントロール群、統制群、非処理群などと呼ばれる比較対照グループと、複数用量の治療群、処理群を比較する検定である。 サンプルサ... -
R で 共分散分析において 3 群以上のカテゴリの多重比較をする方法
三群以上の平均値を多重比較したい。 でも各群の背景因子がそろっていない。 背景因子を調整しながら三群以上の平均値を多重比較するにはどうすればいいか? R でのやり方を解説する。 共変量を調整して多重比較する方法 群ごとの背景因子は、群分け変数と... -
R でノンパラメトリック検定の多重比較を実行する方法
ノンパラメトリックの多重比較をRで実施する方法。 ノンパラメトリックとは何か? ノンパラメトリックとはパラメトリックではないという意味。 パラメトリックとは、パラメーターを使うという意味だ。 パラメーターとは、日本語では母数(ぼすう)と言われ... -
R でフィッシャーの正確確率検定・カイ二乗検定 で 3 群以上の比較を実行する方法
フィッシャーの正確確率検定、カイ二乗検定の3群以上の比較をRで実施する方法の解説。 カイ二乗検定の3群以上の比較 三群以上の割合の比較はどうやればいいのか? Bonferroni型のp値調整を使う方法がある。 Rで行う場合、pairwise.prop.test()という関数を... -
R でボンフェローニを実行する方法
検証試験において、三群以上の平均値を比較したいときに、単純に二群比較を繰り返すと有意水準が甘くなる。 有意水準の調整によって簡単に処理する方法がボンフェローニ (Bonferroni)の方法とその進化版だ。 Rでボンフェローニ型のP値調整で多重比較を行... -
R でチューキー検定を行う方法
Tukey HSD検定をRで行う方法の解説。 Tukey HSD検定をRで行う方法 aov()とTukeyHSD()という二つの関数を使う。 ダネット検定のときと同じように、例としてwarpbreaksというデータを使う。 ダネット検定は以下を参照。 機織りにおいて、tension(緊張、張り... -
R でダネット検定を行う方法
ダネット検定は、比較対照群といくつかの実験群を多重比較する方法。 Rでダネット検定をするにはどうしたらよいか? Rでダネット検定をするには? まずmultcompパッケージをインストール。 インストールは一回だけでOK。 install.packages("multcomp") 次...