
SVM(サポートベクターマシン)のコストパラメータ C について。

SVM の C とは?
SVM(サポートベクターマシン)のコストパラメータ C とは何か?
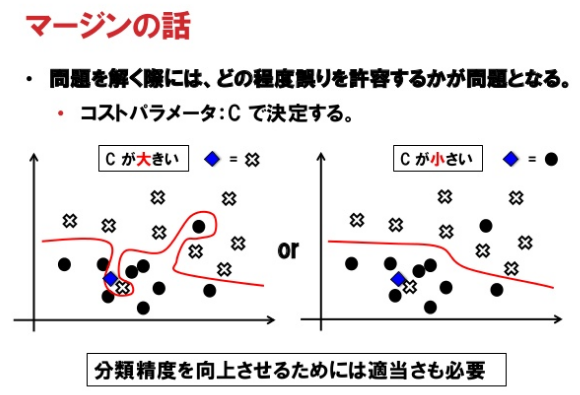
コストパラメータ C は誤分類を許容する指標。
C が小さいと誤分類を許容する。
大きいと誤分類を許容しない。
C が大きい場合は、複雑に分類している。
複雑に分類すると、学習しているデータでは誤分類せずきれいに分類できる。
しかし、汎用性は下がる。
テストデータでは分類性能が下がる。
C を小さくして、誤りをある程度許容すると汎化性能が上がる。
出典:Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
SVM の C 例示のためのサンプルデータ準備
ISLRパッケージのOJデータを使う。
OJデータはシトラスヒル(CH)とミニッツメイド(MM)どちらのオレンジジュースを買ったかのデータ。
どちらのオレンジジュース買うかを予測する分類器を作成するというお題。
最初一回だけインストールする。
install.packages("ISLR")
呼び出すのがlibrary()だ。
library(ISLR)
学習セットのために1070件のデータの3分の2をサンプリングする。
同じ結果が得られるためにseedを決めておく。
set.seed(20180916)
sub <- c(sample(1:1070, round(1070*2/3)))

SVM の C コストパラメータを変えて結果を確認してみる
コストのデフォルトは 1 で、指定しないと 1 で計算される。
model1 <- svm(Purchase ~ ., data = OJ[sub,], cross=10)
(svm.confusion.tr1 <- table(fitted(model1),OJ[sub,]$Purchase))
sum(diag(svm.confusion.tr1))/sum(svm.confusion.tr1)
pred1 <- predict(model1, newdata=OJ[-sub,])
(svm.confusion1 <- table(OJ[-sub,]$Purchase, pred1))
sum(diag(svm.confusion1))/sum(svm.confusion1)
学習セットの正答率は86.0%で、テストセットでは81.5%だ。
> (svm.confusion.tr1 <- table(fitted(model1),OJ[sub,]$Purchase))
CH MM
CH 393 65
MM 35 220
> sum(diag(svm.confusion.tr1))/sum(svm.confusion.tr1)
[1] 0.8597475
> (svm.confusion1 <- table(OJ[-sub,]$Purchase, pred1))
pred1
CH MM
CH 200 25
MM 41 91
> sum(diag(svm.confusion1))/sum(svm.confusion1)
[1] 0.8151261
コストを10倍の10にしてみる。
model2 <- svm(Purchase ~ ., data = OJ[sub,], cross=10, cost=10)
(svm.confusion.tr2 <- table(fitted(model2),OJ[sub,]$Purchase))
sum(diag(svm.confusion.tr2))/sum(svm.confusion.tr2)
pred2 <- predict(model2, newdata=OJ[-sub,])
(svm.confusion2 <- table(OJ[-sub,]$Purchase, pred2))
sum(diag(svm.confusion2))/sum(svm.confusion2)
学習セットの正答率は87.0%まで上がるが、テストセットでは78.4%に下がった。
コストを高くすると汎化性能は下がることがわかる。
> (svm.confusion.tr2 <- table(fitted(model2),OJ[sub,]$Purchase))
CH MM
CH 394 59
MM 34 226
> sum(diag(svm.confusion.tr2))/sum(svm.confusion.tr2)
[1] 0.8695652
> (svm.confusion2 <- table(OJ[-sub,]$Purchase, pred2))
pred2
CH MM
CH 193 32
MM 45 87
> sum(diag(svm.confusion2))/sum(svm.confusion2)
[1] 0.7843137
コストを0.1にしてみるとどうか?
model3 <- svm(Purchase ~ ., data = OJ[sub,], cross=10, cost=0.1)
(svm.confusion.tr3 <- table(fitted(model3),OJ[sub,]$Purchase))
sum(diag(svm.confusion.tr3))/sum(svm.confusion.tr3)
pred3 <- predict(model3, newdata=OJ[-sub,])
(svm.confusion3 <- table(OJ[-sub,]$Purchase, pred3))
sum(diag(svm.confusion3))/sum(svm.confusion3)
コスト1に比べると、学習セットでもテストセットでも正答率は下がる。
コストを下げ過ぎると性能が悪くなることがわかる。
> (svm.confusion.tr3 <- table(fitted(model3),OJ[sub,]$Purchase))
CH MM
CH 383 80
MM 45 205
> sum(diag(svm.confusion.tr3))/sum(svm.confusion.tr3)
[1] 0.8246844
> (svm.confusion3 <- table(OJ[-sub,]$Purchase, pred3))
pred3
CH MM
CH 201 24
MM 46 86
> sum(diag(svm.confusion3))/sum(svm.confusion3)
[1] 0.8039216
まとめ
以上、サポートベクターマシンのコストパラメータ C を変えてみて、分類器の性能を確認してみた。
コストパラメータは上げ過ぎても下げ過ぎてもよくないことがわかった。






コメント