
クロスオーバー試験は、一人の症例が複数の介入を受けることで、並行群間試験よりも効率よく行える試験
EZR でクロスオーバー試験データを解析する方法を紹介する

クロスオーバー試験とは
クロスオーバー試験とは、介入 A と介入 B の両方を同じ被験者で行う方法である
その際に、A を先に行い、次に B を行うグループと、B を先に行い、次の A を行うグループを設定する
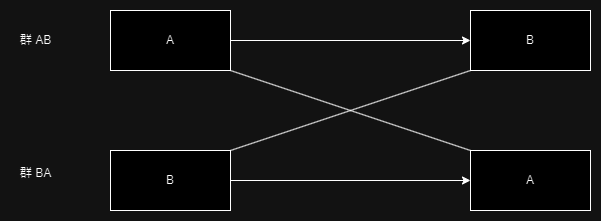
A が施されているグループ・時点と、B が施されているグループ・時点が、図のように交差しているように見えるため、クロスオーバーと呼ばれる
クロスオーバーの原義は、「境界線を越えて交わる」ことなので、実際にクロスしているというよりも、A の介入の後 B になる、もしくは、B の介入後 A になるというふうに、二つの介入が同じ人に施されて交わる、それも全員が同じ順番ではなく、順番が逆の人も設定されていて交わるというふうに理解するとよいだろう
クロスオーバー試験のサンプルサイズ計算は、以下を参照

クロスオーバー試験のサンプルデータ
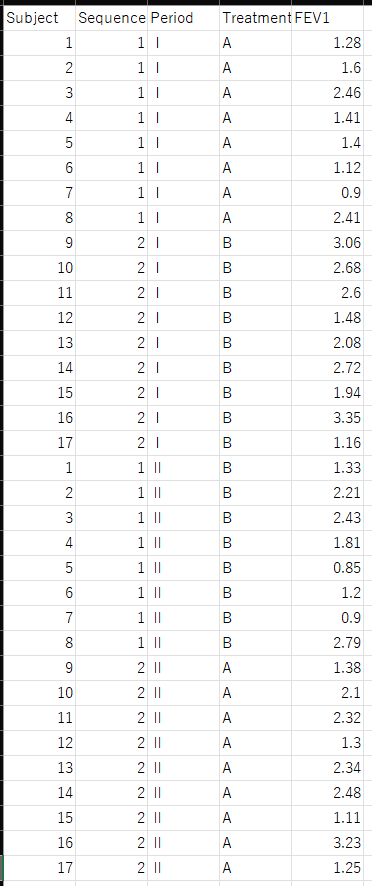
ここでは、公開されている 折笠 2016 論文 のデータを基に、計算を再現してみる
データ一覧は、以下のとおりである

EZR でのクロスオーバー試験データの解析方法
メニューは、統計解析 → 連続変数の解析 → 線形混合効果モデル を用いる
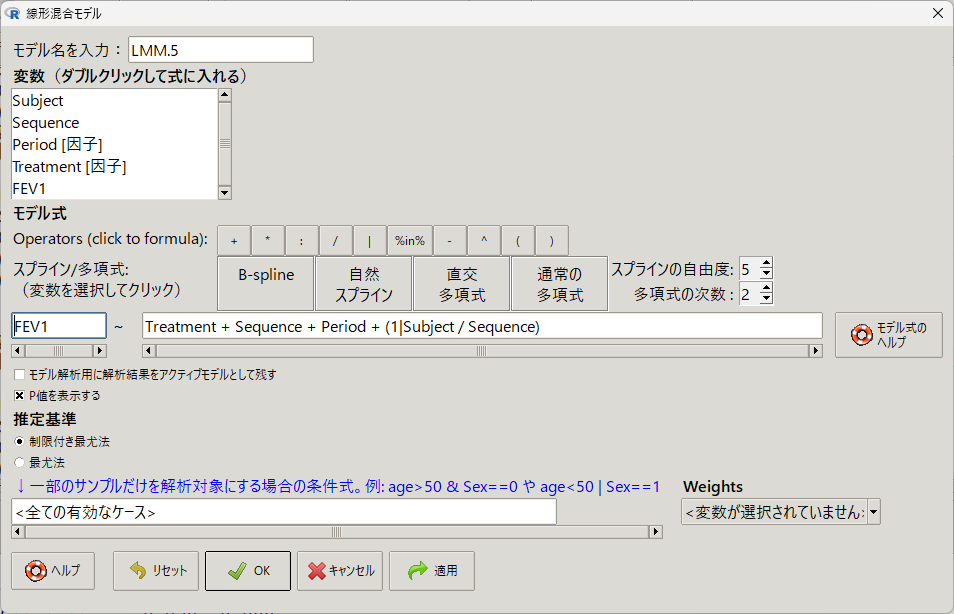
モデル式の入力例
個人別切片を変量効果に入れる、通常の混合モデルと違って、個人識別(Subject)と順番(Sequence)を変量効果として用いる
Subject と Sequence が「入れ子(Subject 一人一人に Sequence 1, 2 もしくは 2,1 が含まれるという意味)」になっている部分の入力方法に注目
この入れ子(Nested とも言う)は、 (1| Subject / Sequence) と表現する(Subject と Sequence の間はスラッシュ記号)
OK をクリックして、実行した後に、R スクリプトの一部を抜き出すと、以下のように書いていることがわかる
res <- lmer(FEV1 ~ Treatment + Sequence + Period + (1|Subject / Sequence), data=Dataset, REML=TRUE)
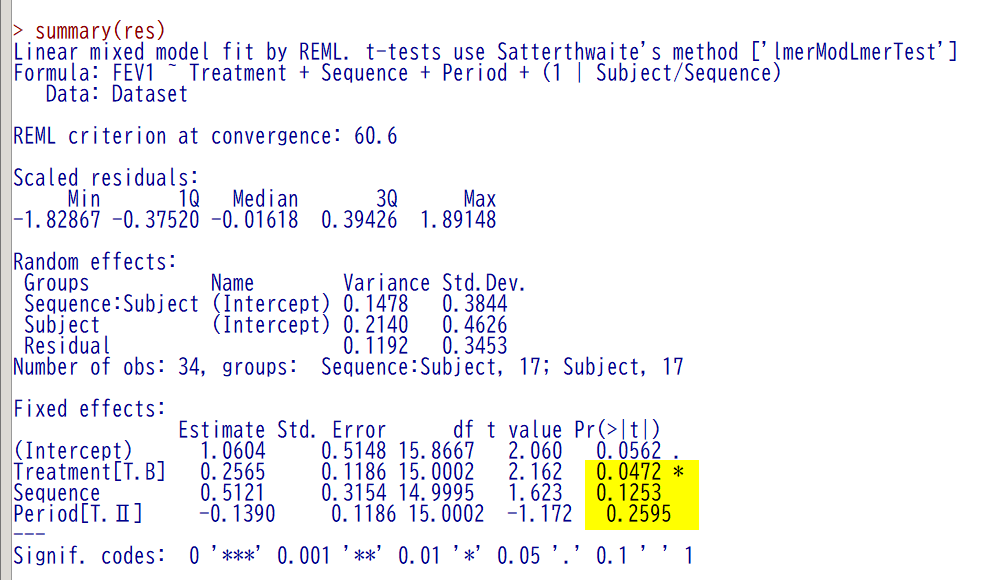
結果の確認
P 値が論文と同じことが確認できる(黄色ハイライト)
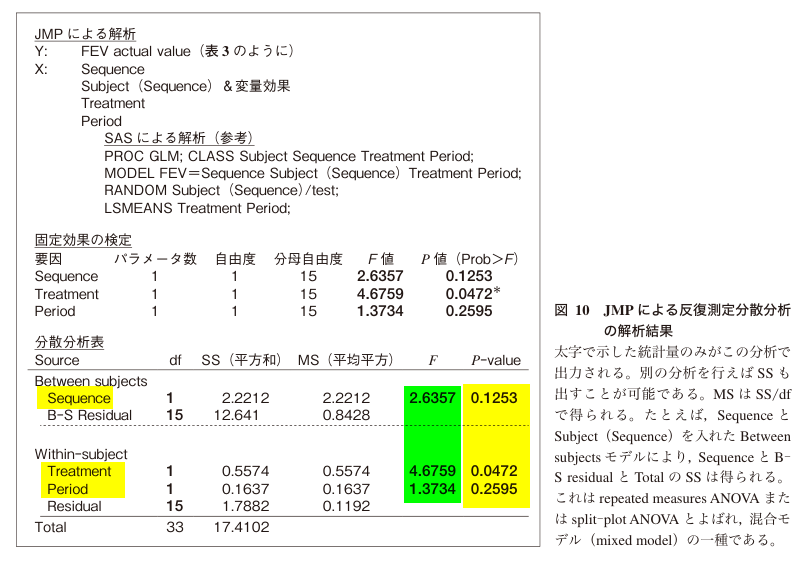
論文の記載は以下のとおり(黄色ハイライト)
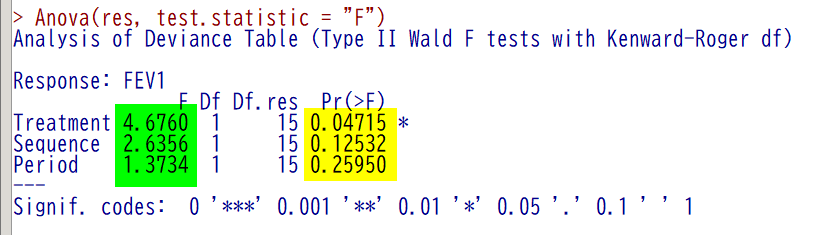
論文と同じように分散分析で表示する場合は、Anova(res, test.statistic = “F”) と書いて実行すると表示される(緑ハイライト)
まとめ
EZR でクロスオーバー試験データを解析する方法を解説した
被験者と介入順をスラッシュでつないで変量効果として投入する
参考になれば



コメント