
統計解析を実施して、結果を見て初めて、検出力やサンプルサイズの問題が意識されることは多い
手元にすでにあるデータから効果量を計算し、事後検出力、事後サンプルサイズ計算に進む流れを紹介する

事後に検出力やサンプルサイズ計算が必要になることはよくある
サンプルサイズ計算は、試験開始前やデータ収集の前に行わなければいけないが、実際は必ずしも行われていない
事前に検討せず、データを集めて、検定結果を見て初めて、検出力や必要サンプルサイズが問われることはよくある
そのような場合に、手元にあるデータから効果量を計算し、事後検出力、必要サンプルサイズを計算する方法があるので、紹介する
参考にした書籍は、こちら
心理学データ解析基礎: RとJASPで学ぶ楽しい心理統計の世界
ちなみに、単変量解析を扱うが、最終的に多変量解析(例:群間比較を交絡因子調整した重回帰分析、共分散分析)がゴールであっても、単変量の検定のサンプルサイズ計算で事足りることは多いので、まずここで説明する単変量解析の効果量、事後検出力、事後サンプルサイズ計算をおさえてほしい
効果量とは
効果量とは、サンプルサイズ計算や検出力計算の際に必要な数値である
検定によって異なるが、平均値の差の検定(t 検定)であれば、平均値の差を標準偏差で割った値である
平均値の場合は、標準偏差で割ることを標準化と呼ぶ
一般的には、標準化された差を効果量と呼ぶ
EZR では、効果量を計算することはできないが、effsize というパッケージをインストールすることで、計算することができる(後述)

サンプルデータの説明
サンプルデータは、2 群の連続データで、group が群を表し、outcome が検定する連続データである
介入前後の変化量をイメージしている
こちらからダウンロードできる
ファイル → データのインポート → ファイルまたはクリップボード、URL から テキストデータを読み込む を選択し、CSV ファイルを読み込んで使用する
データセット名は、Dataset とする
2 群の箱ひげ図を書くと以下のようになる
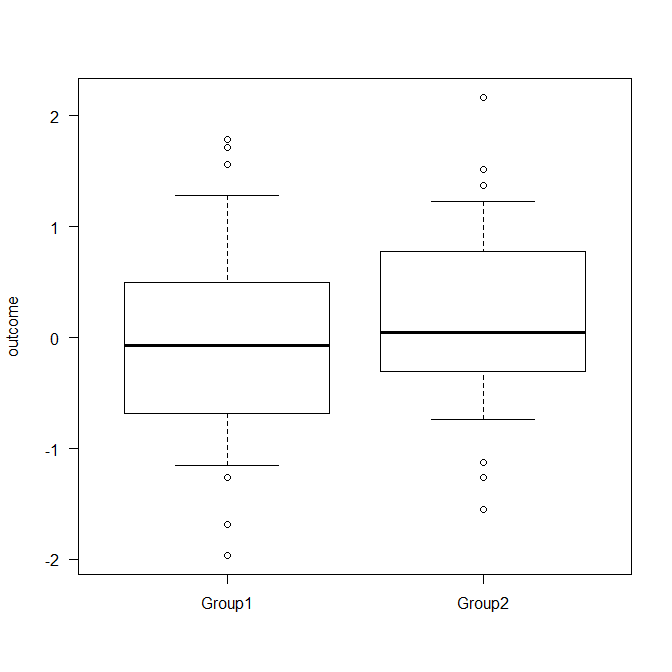
平均値の差の検定(Welch の検定)を行うと、以下のように、2 群の平均値の差は、統計学的有意ではなかった(P = 0.342)

効果量の計算
効果量を計算するには、まず、effsize パッケージをインストールする
インストールは、以下のスクリプトを R スクリプト枠に、手入力またはコピペして、実行ボタンをクリックし、出てきた窓内の Japan をクリックして OK すれば、インストール完了だ
install.packages("effsize")
次に、effsize パッケージを呼び出し、cohen.d 関数で計算する
一行ずつ書いて、実行ボタンをクリックしていく
library(effsize)
cohen.d(outcome ~ group, data=Dataset)
outcome が比較したい連続データ、group は群を表すカテゴリカルデータ、Dataset がデータセット名だ
結果は以下のように、-0.2474653 となった
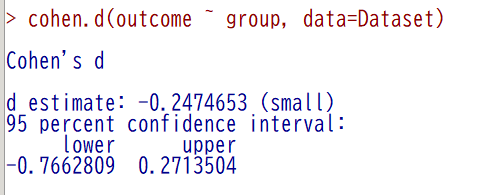
group1 - group2 の計算で、マイナスの結果になっているが、group2 - group1 でも同じことなので、以後は、プラスで考える
事後検出力の計算は、プラスの値のほうが適切になる
事後検出力を計算する
EZR で検出力を計算するには、統計解析 → 必要サンプルサイズの計算 → 2 群の平均値の比較のための検出力の計算 を選択する
現れた窓の各枠に以下を入力する
- 2 群間の平均値の差:0.2474653(効果量を書き入れる)
- 2 群共通の標準偏差:1(平均値の差に効果量を入れているということは、標準偏差で割って標準化されているという意味なので、ここには 1 と入力する
- グループ 1 のサンプルサイズ:30(手元データの実際の症例数を入れる)
- グループ 2 のサンプルサイズ:30(手元データの実際の症例数を入れる)
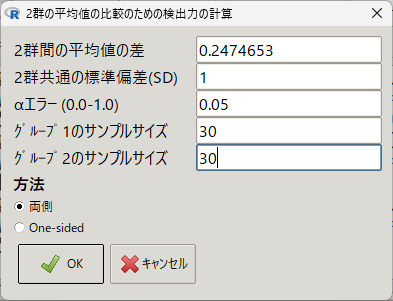
OK をクリックすると計算される

検出力は、0.158 = 15.8 % と計算された
この低さでは、統計学的有意とはならない
事後サンプルサイズ計算
それでは、サンプルサイズはどのくらいの大きさだったらよかったのか
EZR でサンプルサイズ計算をするには、統計解析 → 必要サンプルサイズの計算 → 2 群の平均値の比較のためのサンプルサイズ計算 を選択する
- 2 群間の平均値の差:0.2474653
- 2 群共通の標準偏差:1
検出力計算のときと同じように、上記二つを入力する
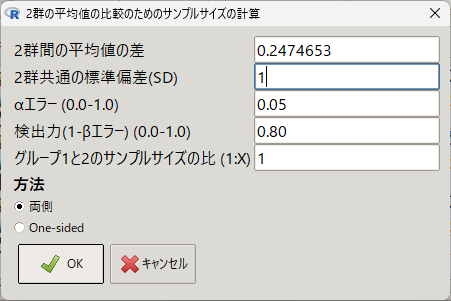
OK をクリックすると必要サンプルサイズが計算される

今回の群間差が、統計学的有意となるためには、必要サンプルサイズは一群 257 例、合計で 514 例必要と計算された
いまデータから得られている差が、意味あるものであるならば、このような巨大な症例数が必要になる
逆に、こんなに症例数が必要になるならば、この群間差は意味のないものではないか? など、改めて、クリニカルクエスチョンから考え直してもよいかもしれない
まとめ
検出力計算、サンプルサイズ計算は、統計解析して、結果を見てから必要性に気づくことがよくある
EZR に effsize パッケージを追加して、cohen.d 関数で生データから効果量を計算する方法を紹介した
参考になれば





コメント