
SPSS で連続データを区切ってカテゴリカルデータを作る方法を解説

SPSS で連続データをカテゴリカルデータにする方法 例 1 :変数の計算
年齢を 10 歳の区切りでカテゴリカルデータにしたい場合
10 で割って小数点以下を切り捨てるという方法を使う
まず、変換 → 変数の計算 を選択
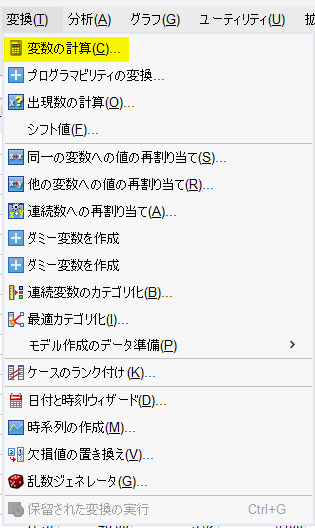
目標変数に agec など適切な変数名を書く
数式に、算術の中の Trunc(1) を選択して、数式枠にダブルクリックで投入し、カッコ内に age / 10 と書く
Trunc(1) は、カッコ内の小数点を切り捨てるという関数である
age / 10 で年齢を 10 で割ると、61 歳が、6.1 になり、小数点以下を切り捨てると 6 という値になる
OK をクリックして、agec を作成した後、確認してみると、それぞれのカテゴリの最小値最大値が、何十歳代におさまっているのがわかる
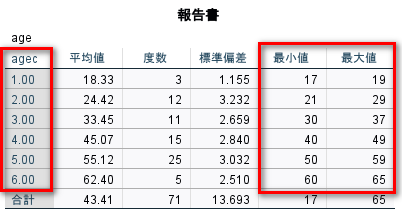
これで、10 歳刻みのカテゴリカルデータに変換できた
SPSS で連続データをカテゴリカルデータにする方法 例 2 :他の変数への再割り当て
BMI のような、先行研究で区切りが決まっている場合
この場合は、変換 → 他の変数への値の再割り当て を使う
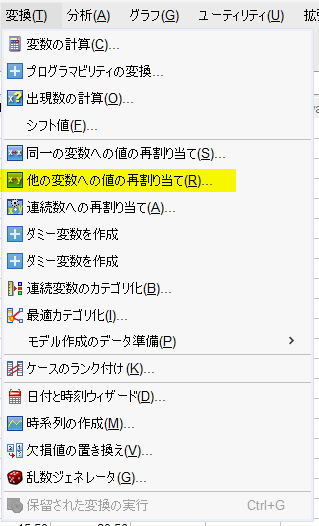
BMI を入力変数 -> 出力変数 の枠に投入する
変換先変数の名前を決める(例えば bmic )
変更をクリック
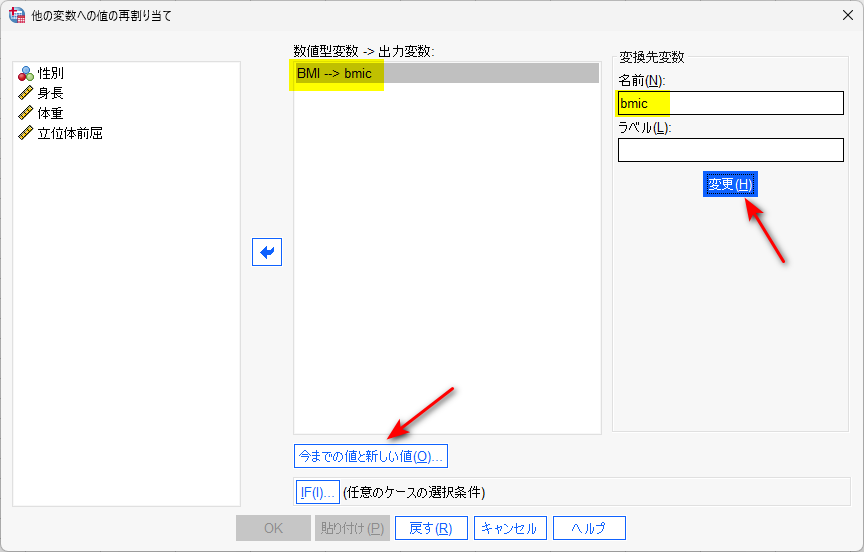
次に、今までの値と新しい値 をクリック
- 18.5 未満を 1
- 18.5 以上 25 未満を 2
- 25 以上 30 未満を 3
- 30 以上を 4
としたいとする
この場合、範囲:最小値から次の値まで の枠に 18.49 を入力して、新しい値に 1 を入力して、追加をクリック
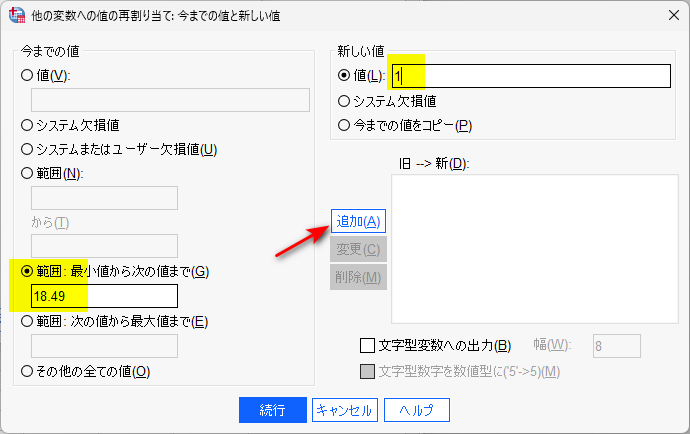
すると、以下のように、旧 -> 新の枠に、変換条件が追加される
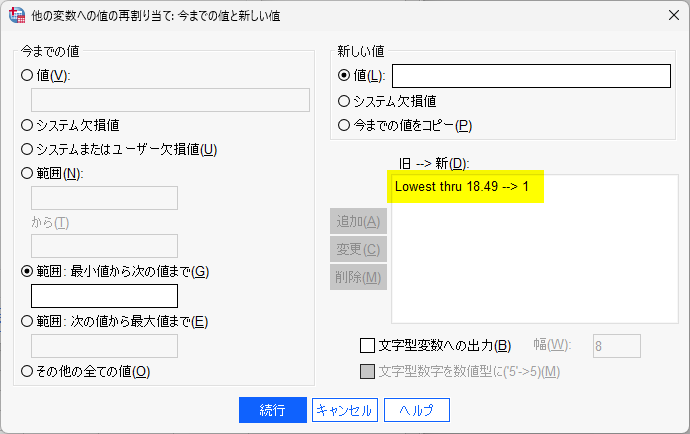
次に、範囲:何々から何々 とある枠に、18.50 と 24.99 を入力して、新しい値に 2 を入力して追加をクリックする
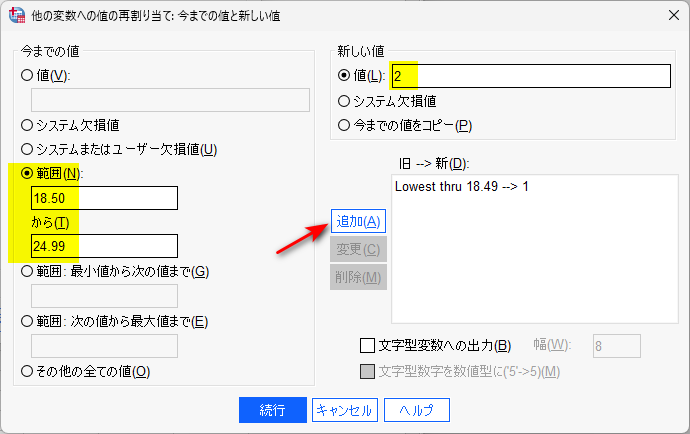
と条件が増える
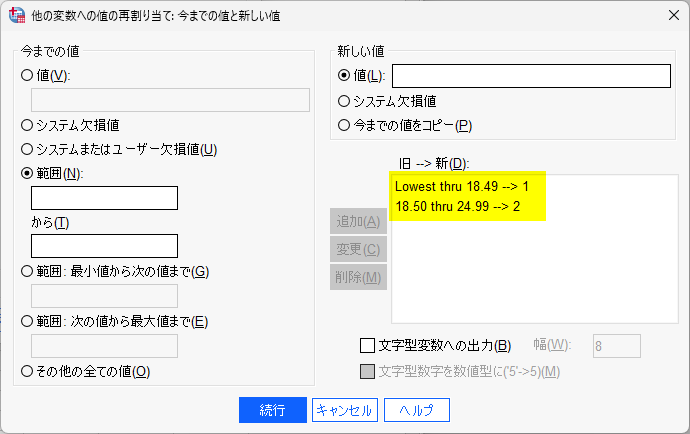
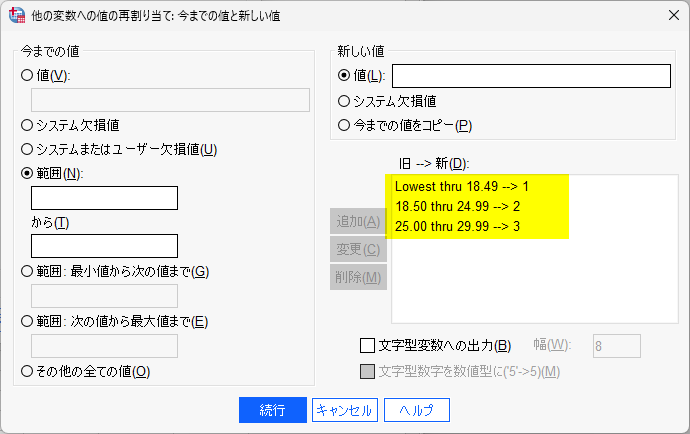
25 以上 30 未満は同様に、新しい値 3 とする
最後、30 以上は、範囲:次の値から最大値まで の枠に 30.00 を入力して、新しい値 4 として、追加をクリックすると以下のようになる
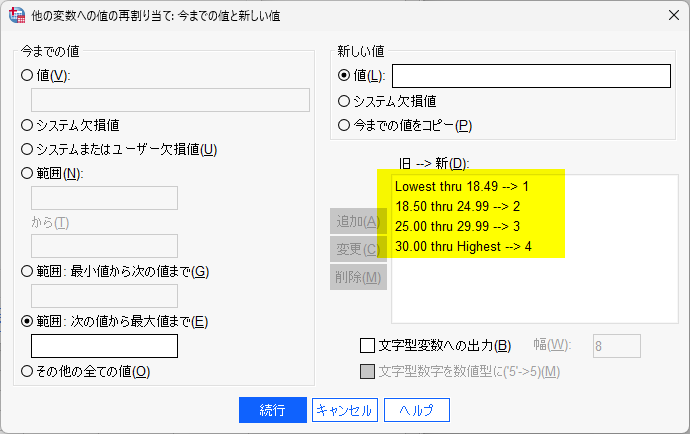
続行をクリックして、OK をクリックすると新しいカテゴリ変数 bmic が作成される
グループごとの最小値最大値を確認すると以下のようになっている
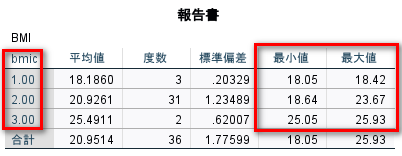
カテゴリ 1 は、18.5 未満、カテゴリ 2 は 18.5 以上 25 未満、カテゴリ 3 は 25 以上 30 未満であることが確認できる
30 以上の人はおらず、カテゴリ 4 はいない
小数点第二位まで記述したので、境界の境目で欠損値になってしまう人はいないと思うが、念のため確認するなら、全症例数を確認しておくとよい
全症例は 36 例で、カテゴリ別の 3、31、2 の合計 36 例と一致している

症例全体の最小値最大値も一致しているので、問題ない

SPSS で連続データをカテゴリカルデータにする方法 例 3 :連続変数のカテゴリ化
カテゴリにする区切りが先行研究等で明らかではなく、恣意性を排除したい場合は、等分に分割するとよい
三分位、四分位、五分位、程度がよくつかわれる
変換 → 連続変数のカテゴリ化 を選択する
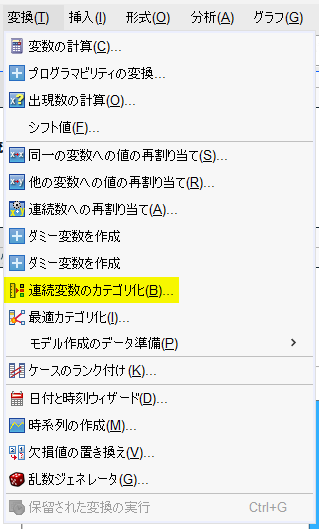
等分割する変数を ビン分割する変数 へ投入する
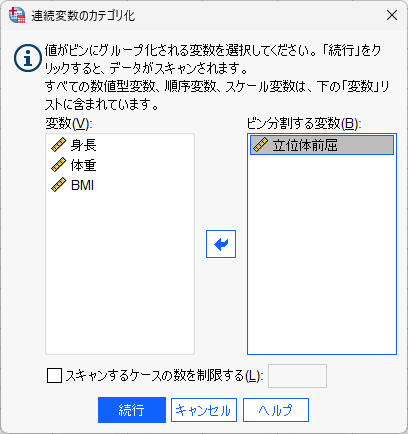
分割の数のことを ビン bin と呼ぶ
ビン分割する変数に変数名を入れ、分割点の作成をクリック
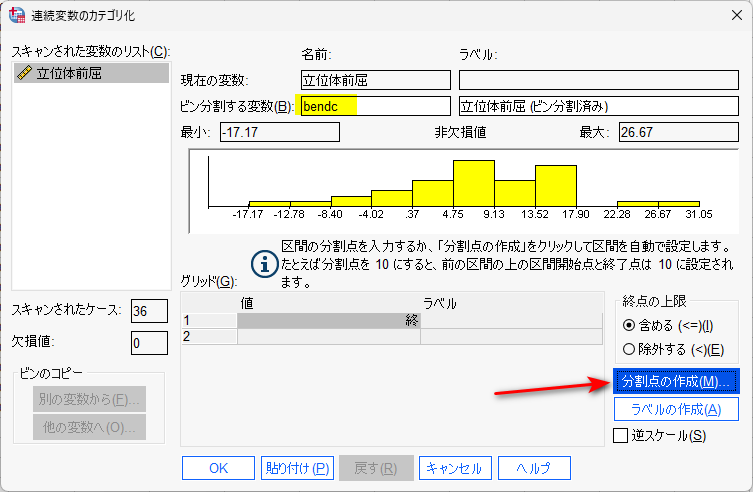
スキャンされたケースに基づく、等しいパーセンタイルを選び、三分位( 3 分割)であれば、分割点の数に 2 と入力する
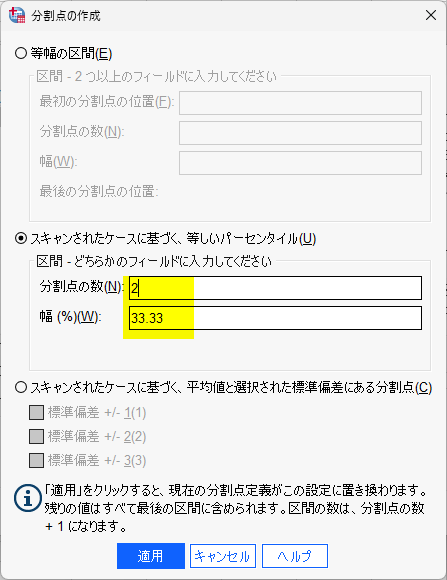
すると、自動で幅のほうに、33.33 が入力される
適用をクリック
ヒストグラムに区切りが表示される
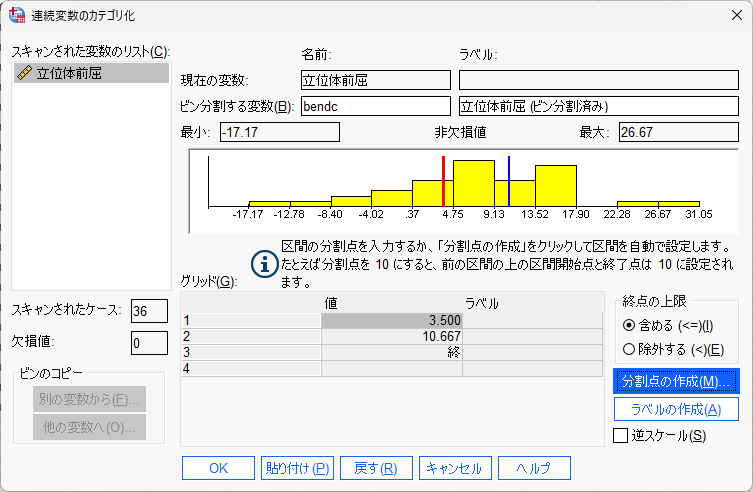
OK をクリックするとカテゴリ変数が作成される
最小値最大値を確認してみると、こんな感じになっている
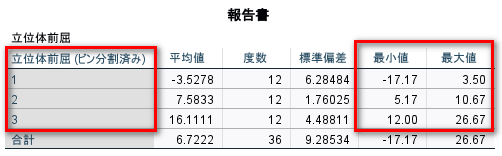
ちょうど 12 例ずつになっている
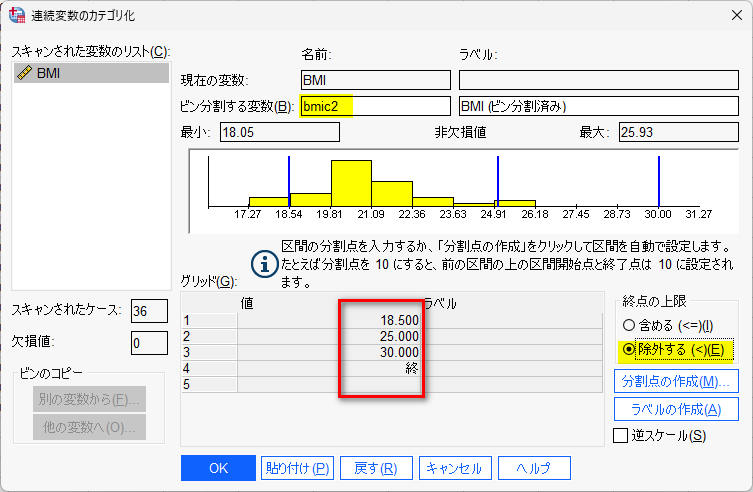
この方法を使うと、例 2 で実施した BMI のカテゴリ化がもっと簡単にできる
以下のようにグリッドに書き入れれば、適切に区切ってくれる
グリッドの境界の上限は 未満 にするのが一般的である
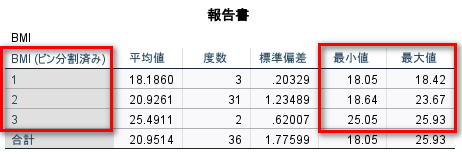
ビン分割したカテゴリ別の最小値最大値は、例 2 のやり方と同じ結果になる
もっとも、例 1 の年齢を 10 歳刻みに分割する方法も、このメニューを使えばできる
まとめ
SPSS で連続データをカテゴリカルデータにする方法を解説した
変数の計算を用いる方法、他の変数への再割り当てを用いる方法、連続変数のカテゴリ化を用いる方法の 3 つ
参考になれば
おすすめ書籍
SPSS医療系データ解析の定本

SPSSで学ぶ医療系多変量データ解析 第2版



コメント