
Tukey HSD検定をRで行う方法の解説。

目次
Tukey HSD検定をRで行う方法
aov()とTukeyHSD()という二つの関数を使う。
ダネット検定のときと同じように、例としてwarpbreaksというデータを使う。
ダネット検定は以下を参照。
あわせて読みたい

R でダネット検定を行う方法
ダネット検定は、比較対照群といくつかの実験群を多重比較する方法。 Rでダネット検定をするにはどうしたらよいか? Rでダネット検定をするには? まずmultcompパッケー…
機織りにおいて、tension(緊張、張り、テンション)の違いによって、warpbreaksがいくつ起きるかというデータを分析する。
ちなみにWarpは縦糸。横糸はWeftという。
手順としては、まず、一元配置分散分析 ANOVAを行う。
次に、ANOVAのオブジェクトを使ってTukey HSD検定を行う。
この流れになる。
amodがANOVAのオブジェクトだ。
今回はtensionの三種類を総当たりで比較する。
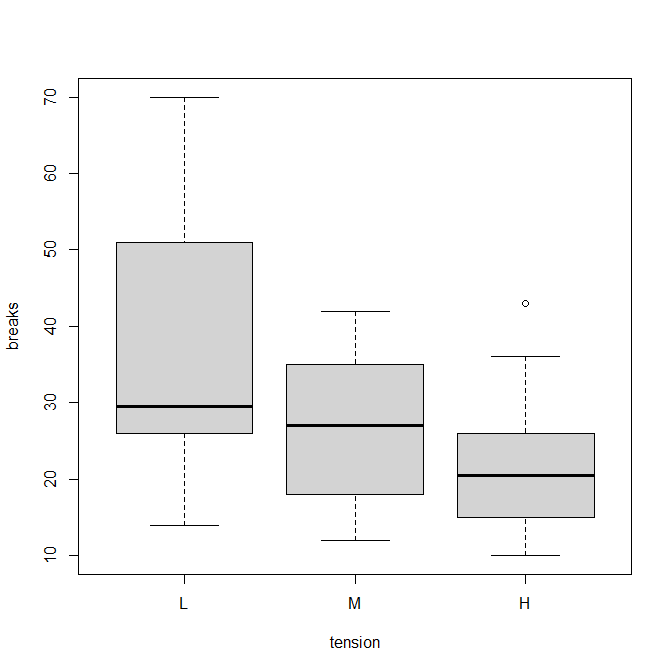
boxplot(breaks ~ tension, data = warpbreaks)
amod <- aov(breaks ~ tension, data = warpbreaks)
TukeyHSD(amod)
tension(緊張、張り)はL(Low)、M(Middle)、H(High)の三種類。
箱ひげ図にしてみると、Lが多くて、M、Hへtensionが高くなると数が減る傾向がある。
Tukey HSD検定の結果は、MもHもLに比べて統計学的有意で、breaksの数はどちらもLに比べて少ない。
HとMの間には統計学的に有意な差はない。
MはLに比べて平均10個少ない。
HはLに比べて平均約15個少ない。
HとMは違いがない。
warpbreaksを予防するなら、Lはやめておいたほうがよい。
HとMはどちらでもよい。
信頼区間の結果も一緒に表示されている。
M-L間とH-L間は、95%信頼区間の上限がマイナスであるのに対し、H-M間は、上限がプラス。
つまりゼロ=差がないことが否定できないわけで、信頼区間と検定の結果が矛盾していないことが確認できる。
> TukeyHSD(amod)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = breaks ~ tension, data = warpbreaks)
$`tension`
diff lwr upr p adj
M-L -10.000000 -19.55982 -0.4401756 0.0384598
H-L -14.722222 -24.28205 -5.1623978 0.0014315
H-M -4.722222 -14.28205 4.8376022 0.4630831
まとめ
Tukey HSD検定は、Rのaov()とTukeyHSD()の二つの関数を使えば、簡単にできる。

EZRで多重比較【動画】
EZRの方法は動画で解説している。
よければ。






コメント
コメント一覧 (4件)
[…] R でチューキー検定を行う方法 Tukey HSD検定をRで行う方法の解説。 […]
[…] R でチューキー検定を行う方法 Tukey HSD検定をRで行う方法の解説。 Tukey HSD検定をRで行う方法 […]
[…] R でチューキー検定を行う方法 Tukey HSD検定をRで行う方法の解説。 Tukey HSD検定をRで行う方法 […]
[…] まずmultcompパッケー… あわせて読みたい R でチューキー検定を行う方法 Tukey HSD検定をRで行う方法の解説。 Tukey HSD検定をRで行う方法 […]