
EZR で IPTW を作成したのち、IPTW 背景データのサマリー表を作成したい場合どうしたらよいか

IPTW 背景データのサマリー表作成手順全体像
EZR で IPTW(逆確率重み)を作成したのち、IPTW 背景データの集計表を作成したい場合、どのようにしたらよいか
具体的な手順は以下のとおり
- 欠損値を含まないデータセットにする
- survey パッケージの svydesign 関数で weights の指定
- tableone パッケージの svyCreateTableOne 関数で IPTW 背景データのサマリー表を作成する
- clipr パッケージの write_clip 関数を使って、クリップボード経由でエクセルに貼り付ける
3 つのパッケージをまだインストールしていなければ、インストールしておく
install.packages(c("survey", "tableone", "clipr"))まずは、以下のように IPTW (weights.ATE.GLM.1)が作成されたとする
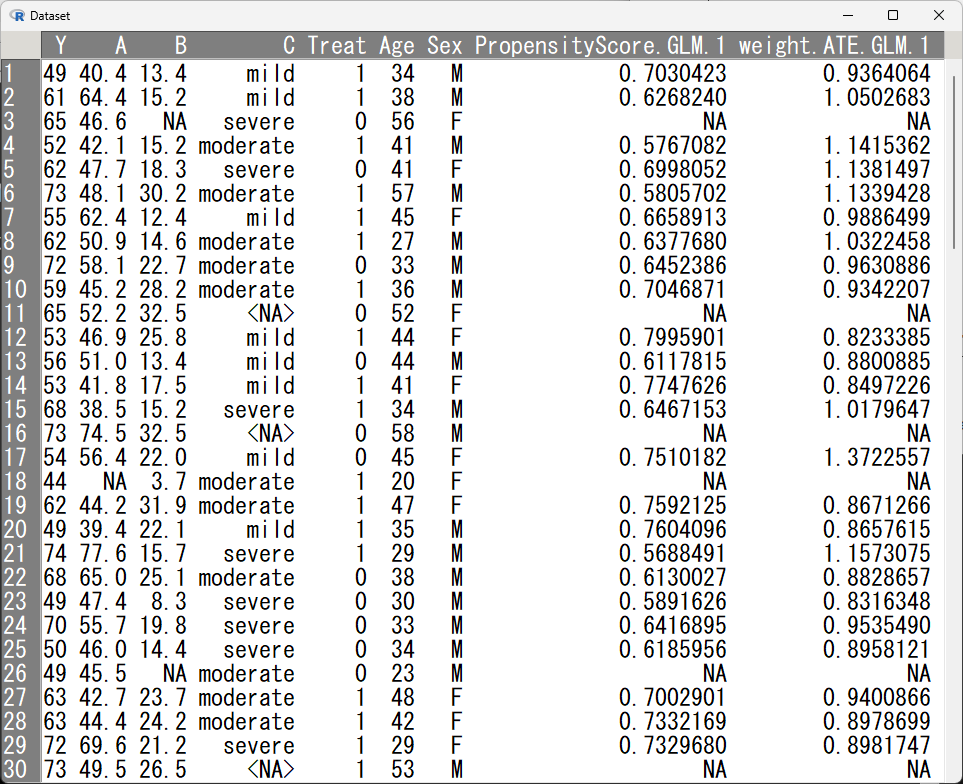
具体的な手順
欠損値を含まないデータセットにする
IPTW が欠損していない症例のみに絞って、出力する必要がある
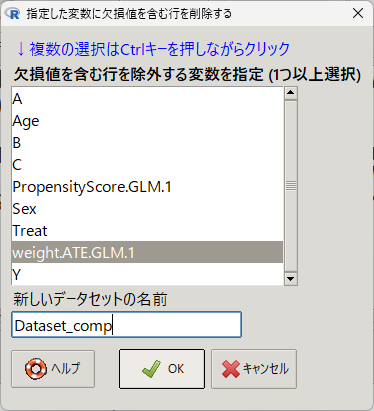
EZR のメニューから「指定した変数に欠損値を含む行を削除する」を用いて、削除する
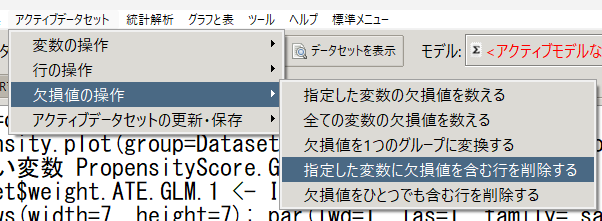
欠損値を含む行を除外する変数に weight.ATE.GLM.1 を選択し、新しいデータセットの名前を Dataset_comp とする
svydesign 関数で weights を指定する
survey パッケージの svydesign 関数を用いて、IPTW を weights として指定する
library(survey)
Dataset_svy <- svydesign(ids= ~1, data=Dataset_comp, weights= ~weight.ATE.GLM.1)ids は、クラスターを指定する引数で、クラスターがない場合、~1 と書く
weights が IPTW を意味していて、weights = ~weight.ATE.GLM.1 と書く
tableone で背景データのサマリー表を作成する
tableone パッケージの svyCreateTableOne 関数で、重み付けした背景データのサマリー表が作れる
library(tableone)
table1 <- svyCreateTableOne(vars=c("C", "Sex", "A", "Age", "B", "Y"), strata="Treat", data=Dataset_svy)
print(table1)背景データは、C, Sex, A, Age, B である
Y は、連続データのアウトカムである
Treat が群間比較の strata である
data は、一節前で作成した svydesign データ(今回は、Dataset_svy)を指定する
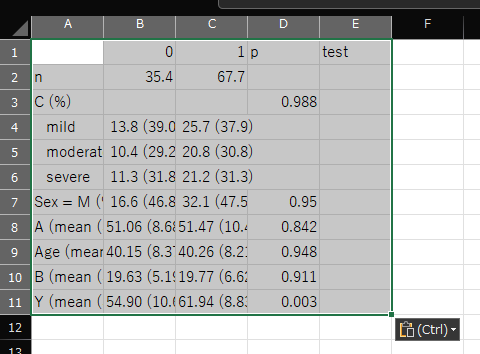
print 関数で出力すると以下のようになる
> print(table1)
Stratified by Treat
0 1 p test
n 35.4 67.7
C (%) 0.988
mild 13.8 (39.0) 25.7 (37.9)
moderate 10.4 (29.2) 20.8 (30.8)
severe 11.3 (31.8) 21.2 (31.3)
Sex = M (%) 16.6 (46.8) 32.1 (47.5) 0.950
A (mean (SD)) 51.06 (8.68) 51.47 (10.45) 0.842
Age (mean (SD)) 40.15 (8.37) 40.26 (8.21) 0.948
B (mean (SD)) 19.63 (5.19) 19.77 (6.62) 0.911
Y (mean (SD)) 54.90 (10.66) 61.94 (8.83) 0.003
clipr でエクセルに貼り付ける
以下のスクリプトで、クリップボードに、上記 table1 をコピーする
library(clipr)
write_clip(as.data.frame(print(table1)))write_clip 関数の中に、as.data.frame 関数が入っているが、これは、print(table1) がデータフレーム型でないためである
データフレーム型の解析結果の場合は、as.data.frame は不要である
エクセルのスプレッドシートを開いて、コントロール+V で貼り付けると以下のように各セルに数値が入って貼りつく
サマリー表をオリジナルのものと比較してみる
左側のオリジナルは、EZR メニューを使っている
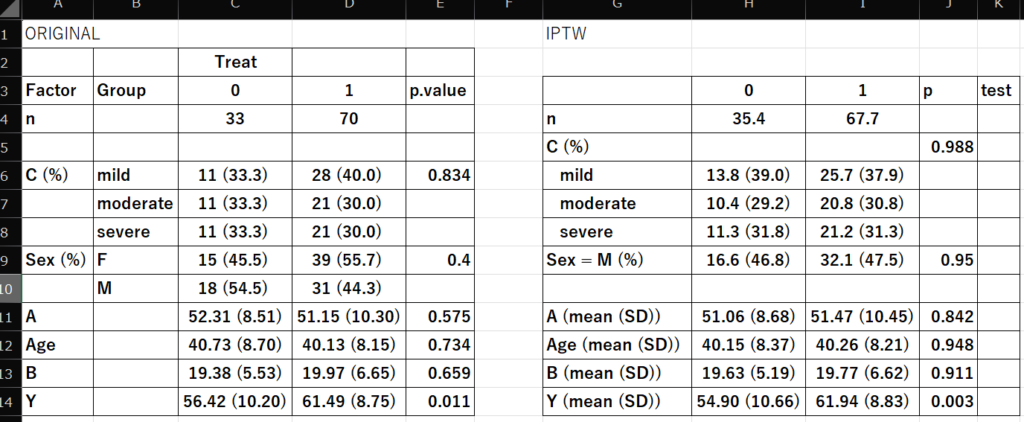
IPTW 側に Sex = F がないなど、若干の違いはあるが、ほぼ同様のサマリー表が作成できる
IPTW では、Y を除き、いずれの背景データもオリジナルと比較して、群間に、より差異がないように見えるのがわかる

まとめ
IPTW データセットを作成したときに、IPTW 背景データのサマリー表を作成する方法を紹介した
svydesign で weights を指定して IPTW データセットを作成し、svyCreateTableOne できれいな出力を作成する、最終的には、write_clip でクリップボードを経由してエクセルに簡単・きれいに貼り付ける
参考になれば



コメント