
R でテキストデータを単語に区切り、頻度表を作成して、N-gram を書く方法を解説

テキストデータの読み込みから頻度表作成まで
まず、前提として、MeCab と RMeCab をインストールしておく
MeCab と RMeCab の準備については、以下の関連記事を参照

まず、テキストデータを読み込む
準備しているテキストデータは、エクセルで以下のように入力されているとする
空気清浄機・加湿器のレビューコメントを取り出したものである
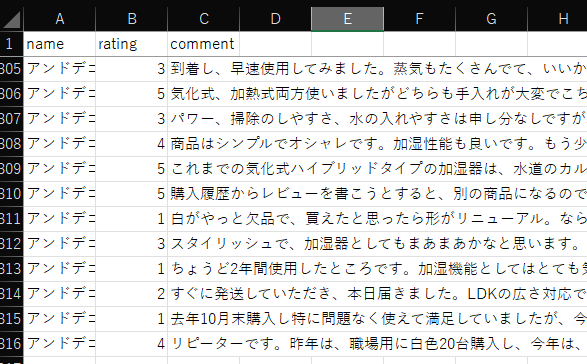
name と rating が comment に対する外部変数で、属性などを表す変数である
comment がテキストデータである
まずこのエクセルファイルを Dataset という名前で読み込む
library(readxl)
Dataset <- read_excel("20201121 Air Purifier Humidifier Review.xlsx")もし、readxl パッケージがインストールされていなければ、install.packages("readxl") でインストールしておく
RMeCab パッケージと dplyr パッケージも呼び出しておく
まだ、インストールしていなければ、インストールしておく
install.packages(c("RMeCab", "dplyr")) を実行すれば、一度にインストールしてくれる
まず、コメント列をテキストファイル temp_file として一時保存する
# コメント列をテキストファイルとして一時保存
temp_file <- tempfile(fileext = ".txt")
writeLines(Dataset$comment, temp_file)次が、本番で、docDF 関数で言葉に分ける作業を行う
revi <- docDF(temp_file, type=1, pos=c("名詞", "形容詞", "動詞"))
revi %>% head(10)temp_file を docDF に投入して、type=1 (形態素)で分割し、品詞は、名詞・形容詞・動詞のみを取り出すようにしている
形態素とは、簡単に言えば「単語」と思えばよい
head(10) で先頭の 10 行を表示してみると、以下のように出力される
> revi %>% head(10)
TERM POS1 POS2 file223470863193.txt
1 ! 名詞 サ変接続 1
2 # 名詞 サ変接続 1
3 % 名詞 サ変接続 35
4 %( 名詞 サ変接続 1
5 %) 名詞 サ変接続 1
6 %、 名詞 サ変接続 1
7 %。 名詞 サ変接続 1
8 %~ 名詞 サ変接続 1
9 &# 名詞 サ変接続 12
10 ( 名詞 サ変接続 34POS1 の列を見ると「名詞」と書いてあるが、いずれも記号であり、いわゆるイメージされる名詞ではないことがわかる
いわゆる名詞に絞る場合、POS2 で細かく指定する必要がある
名詞だけでなく、形容詞、動詞も考慮すると、POS2 に、一般、固有名詞、自立と書いてある語がいわゆる名詞・形容詞・動詞である
revi2 <- revi %>% filter(POS2 %in% c("一般", "固有名詞", "自立"))
revi2 %>% arrange(desc(file223470863193.txt)) %>% head(10)多い頻度順に先頭から 10 行を表示すると以下のようになる
する、なる、思う、あるなどありふれた動詞がもっとも多いのがわかる
> revi2 %>% arrange(desc(file223470863193.txt)) %>% head(10)
TERM POS1 POS2 file223470863193.txt
329 する 動詞 自立 991
407 なる 動詞 自立 235
1503 思う 動詞 自立 168
196 ある 動詞 自立 159
2065 空気 名詞 一般 154
1814 水 名詞 一般 140
990 使う 動詞 自立 124
1882 湿度 名詞 一般 119
399 ない 形容詞 自立 98
2181 良い 形容詞 自立 87ここで、arrange は並び替えの関数である
desc は降順(多いもの順)に並べる関数
file223470863193.txt は、一時ファイルに保存したときについたランダムなファイル名で、この名前の変数が出現頻度の変数名になっている
この頻度列名は、一時保存して読み込んだファイル名(自動付与されている)によって異なるので、まずは、docDF の結果オブジェクト(データフレームになっている)を開くなどして、変数名を確認しておくのが良い
また、ここでは、head(10) として 10 行だけを表示させたが、head(50) など数値を大きくするか、何も指定しなければ、もっと多くの単語の頻度が出力される
N-gram を書く方法 バイグラムを例に
次に、n-gram(N グラム)を生成して、グラフを描く方法を紹介する
N-gram は単語の連なりを意味していて、一般的には 2 つ(バイグラム)または、 3 つ(トリグラム)の連なりを解析する
ここでは、一番シンプルなバイグラムを生成し、グラフにしてみる
まず、バイグラムを生成するには、以下のようなスクリプトを書いて実行する
bigram <- docDF(temp_file, type=1, nDF=1, N=2,
pos=c("名詞", "形容詞", "動詞")) %>%
filter(POS2 %in% c("一般-一般","一般-自立", "自立-一般",
"固有名詞-固有名詞", "固有名詞-自立", "自立-固有名詞",
"一般-固有名詞", "固有名詞-一般"))docDF 関数を使うのは、頻度表と同じである
type=1 は、形態素(いわゆる単語)で分析するという指定である
nDF=1 は、単語ごとに列を独立させたデータフレームを作成する指定である
N=2 は、2 つの単語の連なり、バイグラムを生成する指定である
そして、こちらでも、名詞・形容詞・動詞に限っている
さらに、POS2 に、バイグラムの品詞の組み合わせがあるので、その組み合わせで必要な組み合わせに絞っている
例えば、一般-一般は、一般名詞と一般動詞、一般形容詞と一般名詞、という組み合わせを意味している
生成されたバイグラムの先頭 25 行と 最後尾の 25 行を見てみる場合、以下のスクリプトで表示できる
bigram %>% arrange(file223470863193.txt) %>% head(25)
bigram %>% arrange(file223470863193.txt) %>% tail(25)arrange 内に desc を加えないと昇順(少ないもの順)に並ぶ
先頭は、1 件ばかりである
> bigram %>% arrange(file223470863193.txt) %>% head(25)
N1 N2 POS1 POS2 file223470863193.txt
387 CM 言う 名詞-動詞 一般-自立 1
388 CM 馴染み 名詞-名詞 一般-一般 1
392 HP 水 名詞-名詞 一般-一般 1
398 LDK 広い 名詞-形容詞 固有名詞-自立 1
399 LED 光量 名詞-名詞 一般-一般 1
401 MAX する 名詞-動詞 一般-自立 1
402 MAX ヒーター 名詞-名詞 固有名詞-一般 1
403 MAX 使う 名詞-動詞 一般-自立 1
406 OFF する 名詞-動詞 一般-自立 1
407 OFF クーポン 名詞-名詞 固有名詞-一般 1
409 OH ラジカル 名詞-名詞 固有名詞-一般 1
410 ON OFF 名詞-名詞 固有名詞-一般 1
413 PC TV 名詞-名詞 固有名詞-固有名詞 1
416 Pana 買う 名詞-動詞 固有名詞-自立 1
417 SHARP 型番 名詞-名詞 一般-一般 1
424 TV エアコン 名詞-名詞 固有名詞-一般 1
426 VAPE 窓 名詞-名詞 一般-一般 1
427 W ホワイト 名詞-名詞 一般-一般 1
431 and コロナ 名詞-名詞 一般-一般 1
432 cm 離す 名詞-動詞 一般-自立 1
433 cm 離す 名詞-動詞 固有名詞-自立 1
434 cm 高い 名詞-形容詞 一般-自立 1
435 dB 低い 名詞-形容詞 一般-自立 1
437 h つけ 名詞-名詞 一般-一般 1
461 あたり 外れ 名詞-名詞 一般-一般 1最後尾は、登場回数が多い連なりが並ぶ
> bigram %>% arrange(file223470863193.txt) %>% tail(25)
N1 N2 POS1 POS2 file223470863193.txt
7436 水 こぼれる 名詞-動詞 一般-自立 5
7468 水 減る 名詞-動詞 一般-自立 5
9400 部屋 空気 名詞-名詞 一般-一般 5
9670 音 大きい 名詞-形容詞 一般-自立 5
411 ON する 名詞-動詞 一般-自立 6
1649 する 音 動詞-名詞 自立-一般 6
2939 コス パ 名詞-名詞 固有名詞-固有名詞 6
4918 効果 ある 名詞-動詞 一般-自立 6
7448 水 入る 名詞-動詞 一般-自立 6
7675 湿度 上がる 名詞-動詞 一般-自立 6
9569 電源 入れる 名詞-動詞 一般-自立 6
1589 する 湿度 動詞-名詞 自立-一般 7
2958 コンセント 抜く 名詞-動詞 一般-自立 7
3153 タバコ 吸う 名詞-動詞 一般-自立 7
1583 する 水 動詞-名詞 自立-一般 8
5216 商品 届く 名詞-動詞 一般-自立 9
9677 音 気 名詞-名詞 一般-一般 9
9570 電源 切る 名詞-動詞 一般-自立 10
3110 セット する 名詞-動詞 一般-自立 11
3194 タンク 水 名詞-名詞 一般-一般 12
7443 水 タンク 名詞-名詞 一般-一般 13
9568 電源 入る 名詞-動詞 一般-自立 14
9653 音 する 名詞-動詞 一般-自立 17
7450 水 入れる 名詞-動詞 一般-自立 31
7396 気 なる 名詞-動詞 一般-自立 48バイグラム全体の集計も以下のようにすると確認できる
bigram %>% NROW()
bigram %>% group_by(POS2) %>%
summarize(SUM = sum(file223470863193.txt))バイグラムの種類としては、2404 種類の連なりがあった
> bigram %>% NROW()
[1] 2404POS2 の連なりの種類で集計すると以下のようになった
> bigram %>% group_by(POS2) %>%
+ summarize(SUM = sum(file223470863193.txt))
# A tibble: 8 × 2
POS2 SUM
<chr> <int>
1 一般-一般 867
2 一般-固有名詞 19
3 一般-自立 1230
4 固有名詞-一般 32
5 固有名詞-固有名詞 9
6 固有名詞-自立 18
7 自立-一般 777
8 自立-固有名詞 20一般-自立 が最も多く、一般名詞と自立動詞(例:水を入れる など)の組み合わせが多かったものと思う
生成した n-gram をグラフにする方法
上記のバイグラムの最後尾を見ると、最大で 48 回出現(気 なる)で、6 回以上に絞ると、特徴的なバイグラムのみにできると思われる
今回は、5 回を超えて登場したバイグラムに絞って、ネットワークグラフを描いてみようと思う
bigram2 <- bigram %>% select(N1, N2, file223470863193.txt) %>%
filter(file223470863193.txt > 5)
bigram2 %>% arrange(file223470863193.txt)
bigram2 %>% NROW()21 個の連なりが抽出された
> bigram2 %>% arrange(file223470863193.txt)
N1 N2 file223470863193.txt
411 ON する 6
1649 する 音 6
2939 コス パ 6
4918 効果 ある 6
7448 水 入る 6
7675 湿度 上がる 6
9569 電源 入れる 6
1589 する 湿度 7
2958 コンセント 抜く 7
3153 タバコ 吸う 7
1583 する 水 8
5216 商品 届く 9
9677 音 気 9
9570 電源 切る 10
3110 セット する 11
3194 タンク 水 12
7443 水 タンク 13
9568 電源 入る 14
9653 音 する 17
7450 水 入れる 31
7396 気 なる 48
> bigram2 %>% NROW()
[1] 21グラフは、igraph と ggraph というパッケージを使用する
まだインストールしていなければ、install.packages(c("igraph", "ggraph")) を実行してインストールする
library(igraph)
bigramN <- graph_from_data_frame(bigram2)
print(bigramN)graph_from_data_frame でバイグラムデータをグラフデータに変換する
print すると以下のように出力される
> print(bigramN)
IGRAPH 726aaa8 DN-- 24 21 --
+ attr: name (v/c), file223470863193.txt (e/n)
+ edges from 726aaa8 (vertex names):
[1] ON ->する する ->水 する ->湿度 する ->音 コス ->パ コンセント->抜く セット ->する
[8] タバコ ->吸う タンク ->水 効果 ->ある 商品 ->届く 気 ->なる 水 ->タンク 水 ->入る
[15] 水 ->入れる 湿度 ->上がる 電源 ->入る 電源 ->入れる 電源 ->切る 音 ->する 音 ->気 これは矢印の根元から矢印の矢の方向に流れる連なりという「つながり」であることを示している
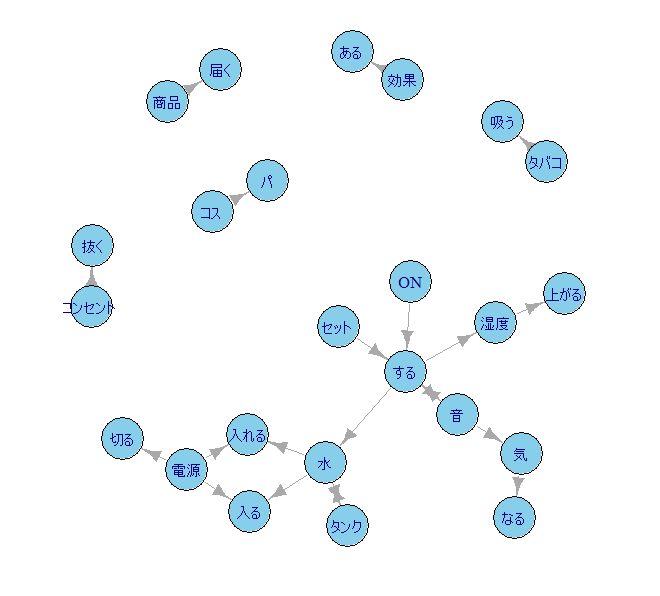
このつながりを plot でグラフにする
vertex.color は ノード(この場合は単語)の色であり、vertex.size はノードの丸の大きさである
library(ggraph)
plot(bigramN, vertex.color="SkyBlue", vertex.size=18)連なりの元と先がわかるような矢印が付いている
「する」にはさまざまな語から連なっているのがわかるし、「水」や「電源」はいろいろな語に連なっていくさまがわかる

まとめ
R で RMeCab を用いて、形態素(単語)解析を行い、頻度表を出力し、バイグラムを生成し、グラフを描く方法を紹介した
参考になれば





コメント