# load sample data データ読み込みload("C:/Users/touke/OneDrive/R_Datasets/lung_rev.RData")
df <- lung_rev
summary(df)# imputation 多重代入library(mice)
df_imputed <-mice(df, seed=0)
df_imputed
# Initialize a list to store the results 結果格納オブジェクトの初期化
anova.values1 <-list()
anova.values2 <-list()# Cox model using cph in rms; rms パッケージの cph 関数を使った Cox 回帰を実施# Loop through numbers 1 to 5; 代入データセット 1 から 5 をループ処理library(rms)for(i in1:5){# Complete the data with imputation number i
df_imp <-complete(df_imputed, i)# Fit the Cox proportional hazards model
cph_imp <-with(df_imp,cph(Surv(time, status01)~ ph.ecog012 + meal.cal))# Perform ANOVA and store the result in the list
anova_result1 <-anova(cph_imp)[1]
anova_result2 <-anova(cph_imp)[2]
anova.values1[[i]]<- anova_result1
anova.values2[[i]]<- anova_result2
}# Combine the ANOVA results into a single vector; Wald 検定の結果を結合
anova_values1 <-unlist(anova.values1)
anova_values2 <-unlist(anova.values2)# Display the combined ANOVA results; Wald 検定の結果を表示
anova_values1
anova_values2
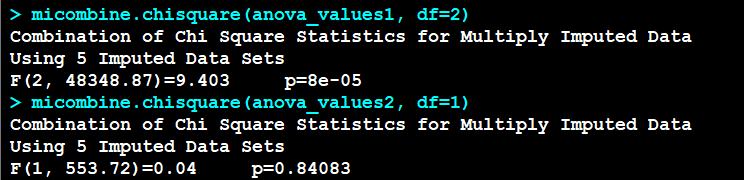
# Pool chi-squares カイ二乗値の統合library(miceadds)micombine.chisquare(anova_values1, df=2)micombine.chisquare(anova_values2, df=1)
結合したカイ二乗値は、以下のとおりになる
統合した結果は、以下のとおり
説明変数 1 番目の ph.ecog012 は、統計学的に有意である
2 番目の meal.cal は統計学的有意ではなかった
まとめ
R において、mice で多重代入したのち、Cox 回帰の Wald 検定を統合したいときのスクリプトを紹介した










コメント