
IPTW カプランマイヤー曲線において、任意の時点における Number at Risk を書き入れる方法
R で作成する方法

IPTW カプランマイヤー曲線
IPTW は、逆確率重み付けとも呼ばれ、ランダム割り付けしていない群間の交絡因子を調整する方法の一つ
詳しくはこちらも参照

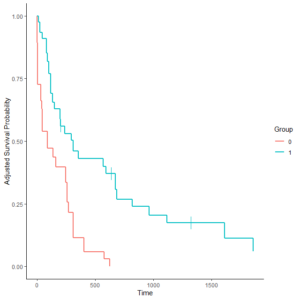
IPTW は、EZR を使うと簡単に作成できるが、後述のようなスクリプトでも作成可能
IPTW で調整したカプランマイヤー推定量を計算して、カプランマイヤー曲線を書く方法と、図の下に Number at Risk(何人イベントを起こさずに残っているか)を示す方法のスクリプトを紹介する
IPTW カプランマイヤー曲線の書き方
R の survival パッケージの、survfit を使って推定量を求めるときに、weight で IPTW を指定するという方法を取る
曲線自体を書くのは、survminer パッケージの ggsurvplot を使う
そうすると、Number at Risk を書き入れるのが簡単である
まず、必要なパッケージを読み込む
# 必要なパッケージを読み込み
library(survival)
library(survminer)
標準のカプランマイヤー曲線
ここでは、サンプルデータとして、ovarian データセットを用いる
survfit で カプランマイヤー推定量を求める
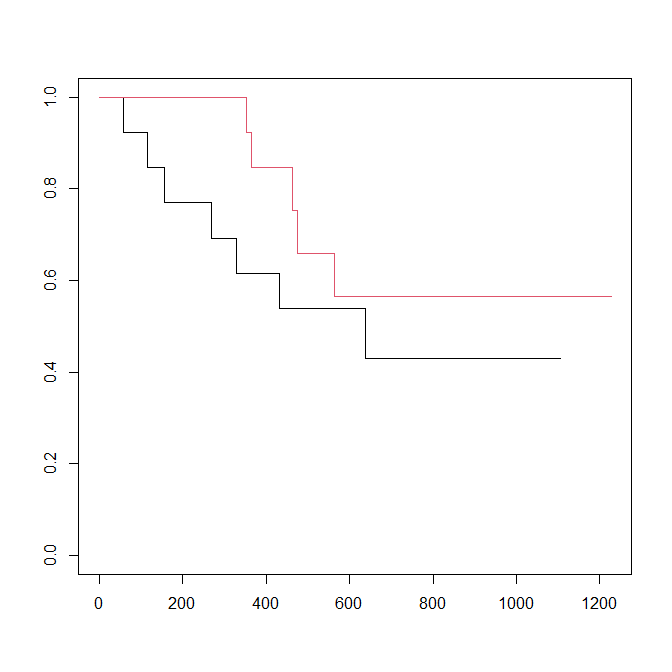
まずは、IPTW 調整なしで書いてみる
km_fit0 <- survfit(Surv(futime, fustat) ~ rx, data=ovarian)
plot(km_fit0, col=1:2)
IPTW で調整していない、rx 因子別のカプランマイヤー曲線が書かれる
傾向スコア及び IPTW の作成
# rx = 1,2 を rx1 = 0,1 に変換
rx1 <- ovarian$rx-1
# 傾向スコアの作成(EZR で作成しても可)
propensity <- glm(rx1 ~ age + resid.ds + ecog.ps,
family = binomial(link='logit'),
data = ovarian)$fitted.values
# IPTW の作成(EZR で作成しても可)
weights <- ifelse(rx1==1, 1/propensity, 1/(1-propensity))
IPTW カプランマイヤー曲線を書く
# カプランマイヤー曲線の作成
km_fit <- survfit(Surv(futime, fustat) ~ rx, data = ovarian,
weights = weights)
plot(km_fit, col=1:2)
IPTW カプランマイヤー曲線はこのようになる
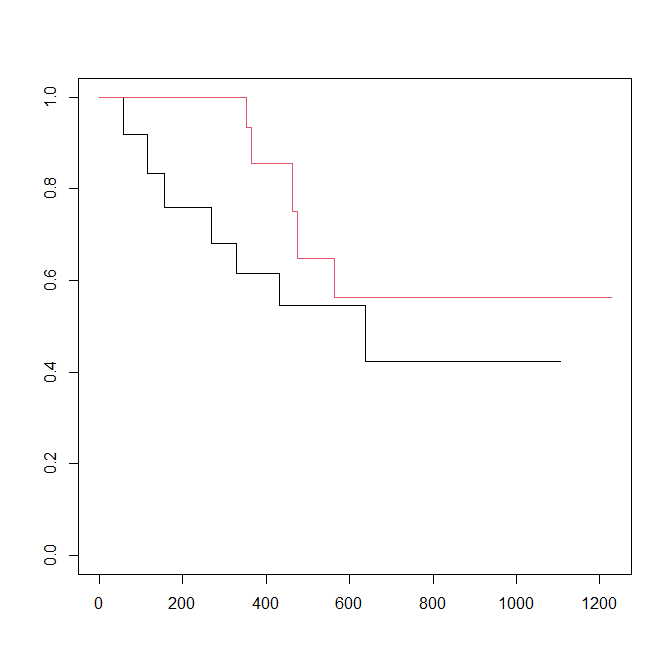
未調整のカプランマイヤー曲線と比較して、ほんの少し黒と赤が近づいたように見える
Number at Risk 入りのグラフを書く
# グラフを作成
ggsurv <- ggsurvplot(km_fit, data = ovarian,
risk.table = TRUE,
risk.table.col = "strata",
ggtheme = theme_minimal())
# Number at risk を表示
ggsurv$table$variables$nrisk <-
paste("At risk:", ggsurv$table$variables$n.risk)
# グラフを表示
ggsurv
ggsurvplot で書いたグラフはこちら
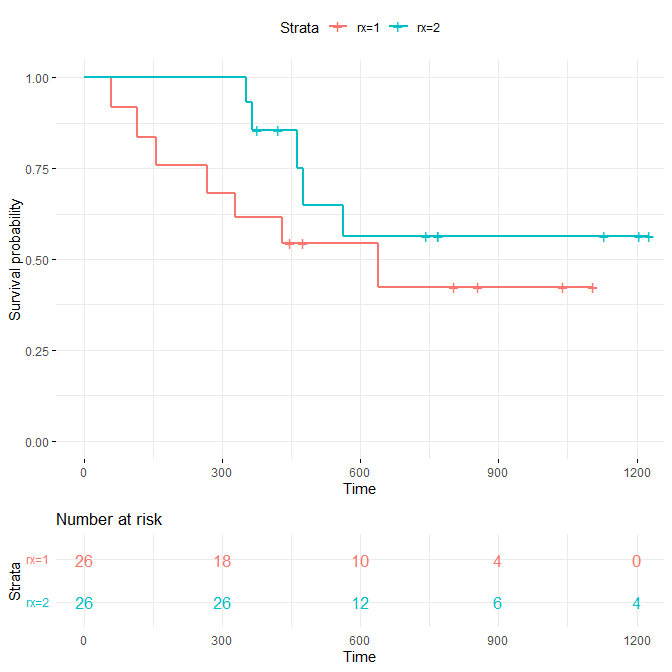
いきなり本格派っぽくなる
ただし、IPTW が反映していない Number at risk なので、更にひと工夫が必要(現在、検討中)

まとめ
R で IPTW カプランマイヤー曲線を書いて、Number at Risk を書き入れる方法を解説した
survminer パッケージの ggsurvplot を使うと、とてもきれいなグラフが簡単にかける
参考になれば

コメント
コメント一覧 (4件)
ありがとうございます。大変勉強になります。もし可能であればIPTW後の2群に対してのスチューデントの t 検定、マンホイットニーの U 検定が可能なのかもご教授頂けますと幸いです。
SPSSなどでは2群のnが145.3など小数点人数になってしまい、2群比較ができず困っておりました。
以下の論文で解析が行われており、Rで可能なのか知りたいと考えております。ご検討いただけますと幸いです。
Ann Rheum Dis. 2021 Sep;80(9):1130-1136.
コメントありがとうございます!
論文を拝見しましたが、どのように計算したか記載がありませんでしたね
R では、lm 関数や glm 関数の weights を使えば、重みをかけて計算できますので、同様の計算ができる気がします
ただし、二値より多いカテゴリカルデータは MASS パッケージの polr 順序ロジスティックとか、nnet パッケージの multinom 多項ロジスティック(いずれも EZR で計算可能)などを使えばできないことはないような・・というところです
でも、論文の表のような人数や%、標準偏差はどうやって計算するのか?よくわからないです
迅速なお返事をいただきありがとうございました。
ご教授いただいた関数を用いて計算できるか試行錯誤してみようと思います。
論文によってはJMPという統計ソフトやStataを使用しているものがあり、それらならできるのかもしれません。
ありがとうございます。いつも大変参考にさせていただいております。
[…] R で IPTW カプランマイヤー曲線グラフに Number at Risk を書き入れる方法 IPTW カプランマイヤー曲線において、任意の時点における Number at Risk […]