
IPTW ログランク検定をEZRとRを使って行う方法。

IPTWとは?
IPTW とは、Inverse Probability of Treatment Weights の頭文字語。
日本語では、逆確率重みづけと言う。
交絡因子調整方法の一つ。
詳しくは他の記事も参照のこと。
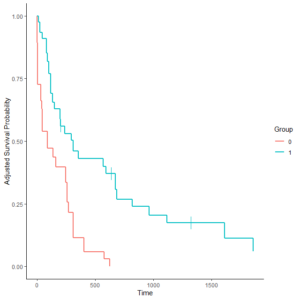
IPTW ログランク検定とは?
IPTW ログランク検定とは、IPTWで重みづけして、交絡因子調整を行ったログランク検定のこと。
ログランク検定は、生存時間解析における群間比較検定である。
必要に応じて、こちらの記事も参照のこと。

IPTW ログランク検定を行う方法
IPTW をEZRで計算する方法
IPTWは、EZRを使うと簡単に計算できる。
IPTWの計算には、ロジスティック回帰モデルを借りる。
「統計解析」→「名義変数の解析」→「ロジスティック回帰」を選択する。
目的変数に群分け変数を投入し、説明変数に考慮したい交絡因子を投入する。
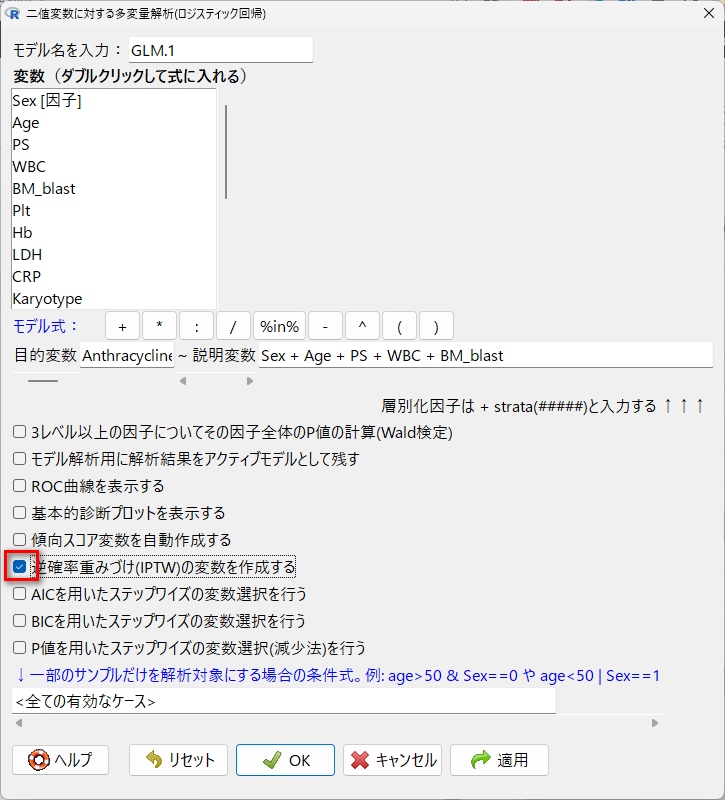
逆確率重みづけ (IPTW) の変数を作成する、にチェックを入れて、OKをクリックする。
すると、新しい変数 weight.ATE.GLM.1 が作成される。

データセットの最後尾に付け足される。
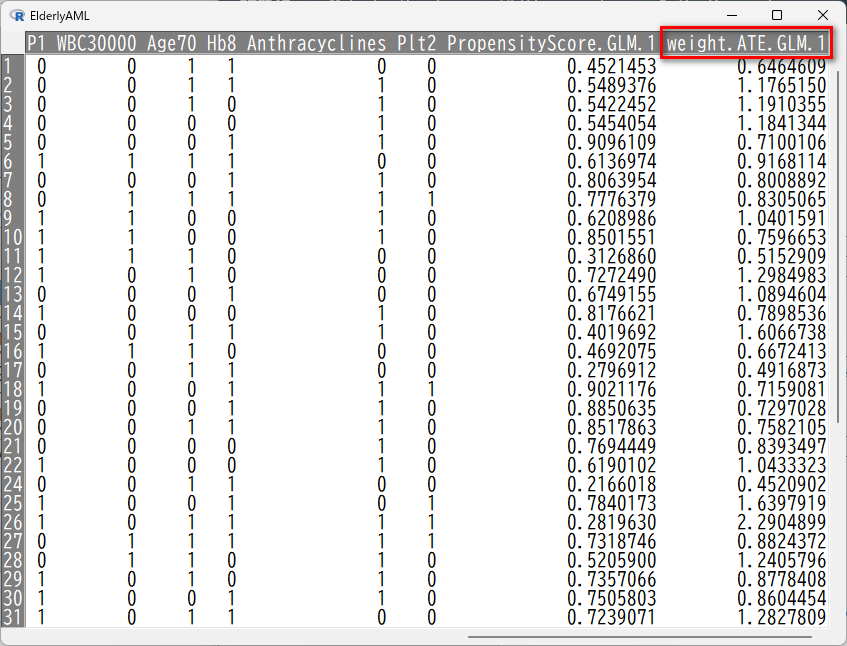
これが、IPTWの重み変数である。
IPTW ログランク検定をRで実行する方法
IPTW ログランク検定は、RISCA パッケージの ipw.log.rank() 関数を使って計算する。
RISCA パッケージをインストールしてもよいが、ipw.log.rank() 関数のみ使いたい場合は、以下のリンクのRスクリプト部分をコピペして使うことも可能である。
RISCA source: R/ipw.log.rank.R
ipw.log.rank() 関数には、以下の変数を投入して計算する。
- times: 観察時間変数
- failures: イベント変数
- variable: 群別変数(2群比較のみ)
- weights: 重み
今回の場合は、以下のように投入することになる。
with(ElderlyAML,
ipw.log.rank(
times = Days,
failures = Survival,
variable = Anthracyclines,
weights = weight.ATE.GLM.1
))欠損値があると計算されないので、事前に欠損値があるケースを削除しておく。
「アクティブデータセット」→「欠損値の操作」→「欠損値をひとつでも含む行を削除する」で、削除できる。
survfit() 関数を使用するため、事前に library(survival) を実行し、survival パッケージを呼び出しておく。
計算結果は以下の通りに出力される。
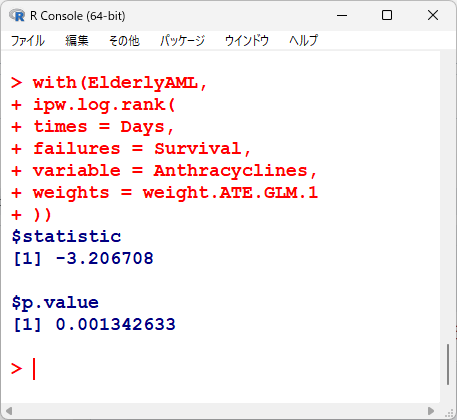
statistic が標準正規分布に従うZ値で、p.value がp値である。
有意水準5%とすると、統計学的有意に異なるという結果である。
IPTWで調整しないと以下の結果になる。
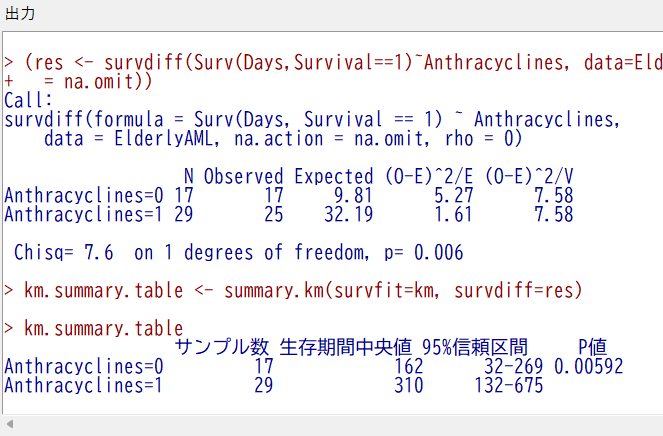
こちらであるとカイ二乗値が7.6で、p値0.00592という結果であった。
IPTW を計算する際に考慮した交絡因子の調整が必須である場合は、IPTWの結果のほうをメインにしてよいだろう。
加えて、Cox比例ハザードモデルでの確認も行うとより適切である。
まとめ
IPTW ログランク検定をEZRとRを使って行う方法を紹介した。
何らか役に立てば幸い。
参考サイト
RISCA source: R/ipw.log.rank.R


コメント
コメント一覧 (4件)
いつも勉強させていただいております。
IPTWを用いたカプランマイヤー曲線やログランク検定の記事大変参考になりました。恐れ入りますが、IPTWのかかった2群のハザード(HR)や95%信頼区間の求め方をご存じでしたらご教授いただけませんでしょうか。
お手隙の際に、ご検討いただけますと幸いに存じます。
[…] EZR と R で IPTW ログランク検定を実行する方法 IPTW ログランク検定をEZRとRを使って行う方法。 […]
いつも勉強させていただいております。Zではなく、EZRでIPTWログランク検定でのP値をだすにはどうしたらよいでしょうか。
お忙しいところ恐縮ですが、ご教授いただければ幸いです。
ご質問ありがとうございます!R スクリプトではなくて、EZR のメニューで、検定するにはどうしたらよいか?というご質問と理解しました。いまのところ、EZR ではその機能は実装されていませんので、実施することはできません。将来的に、できるようになるよう、期待してお待ちしましょう!