
カイ二乗検定のためのサンプルサイズ計算の方法

目次
パッケージのインストール
R の pwr パッケージをインストールして使用する
install.packages('pwr') # 1 回だけインストール
library(pwr)
サンプルサイズ計算をする分割表の例
サンプルサイズ計算をする分割表は以下の割合の 2 x 4 の分割表とする

例えば、全体で 1000 例とすれば、以下のような人数分布になる


R スクリプト
上記の分割表とした場合のサンプルサイズは以下のようなスクリプトで計算できる
prob<-matrix(c(0.225,0.125,0.125,0.125,0.16,0.16,0.04,0.04),nrow=2,byrow=TRUE)
prob
ES.w2(prob)
pwr.chisq.test(w=ES.w2(prob),df=(2-1)*(4-1), power=0.8)
分割表の割合を使って、ES.w2() 関数で効果量 w を計算する
自由度 df は、行と列それぞれから 1 を引いた数の積となる
検出力を 80 % ( 0.8 ) とする
そうすると以下の通り、167 例必要と計算される

想定していた割合にかけ合わせて、想定の人数を計算すると以下のようになる
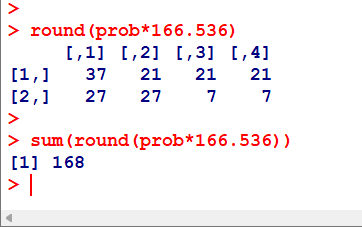
セルごとに丸めているので、合計して検算すると 1 例ずれているが、これはやむを得ない
ちなみに、効果量 w は、約 0.26 である
Cohen によれば、w には以下のような参考にできる慣例がある
- 小さい効果量:0.1
- 中等度効果量:0.3
- 大きい効果量:0.5
まとめ
独立性の検定をカイ二乗検定で行うときのサンプルサイズ計算の方法を解説した
参考になれば
参考書籍
Jacob Cohen. Statistical Power Analysis for the Behavioral Sciences Second Edition.





コメント
コメント一覧 (1件)
[…] R でカイ二乗検定に必要なサンプル数を計算する方法 カイ二乗検定のためのサンプルサイズ計算の方法 […]