
重回帰分析で、独立変数にカテゴリ変数を使う方法を解説する。
SPSSでは、ダミー変数を作成しておく必要がある。
ダミー変数とは何か?
ダミー変数の作り方は?

重回帰分析をSPSSで行う方法
重回帰分析をSPSSで行う場合、2つの方法がある。
ひとつは、「分析」→「回帰」→「線型」メニューを使う方法。
もう一つは、「分析」→「一般線型モデル」→「1変量」メニューを使う方法。
重回帰分析で独立変数にカテゴリ変数を使う場合、やり方が異なる。
一般線型モデルを使う場合、カテゴリ変数をそのまま使える。
「回帰」→「線型」を使う場合、ダミー変数を作る必要がある。
この記事では、「回帰」→「線型」を使う場合で、ダミー変数を作らないといけない場合を解説する。
重回帰分析でカテゴリ変数を使う方法 ダミー変数とは?
ダミー変数とは、カテゴリ変数を重回帰分析で使うために、0と1だけで表した変数のことである。
2カテゴリのカテゴリ変数は、2つの可能性がある。
例として性別をダミー変数にしてみると以下のようになる。
| 性別 | 性別_男性 | 性別_女性 |
|---|---|---|
| 男性 | 1 | 0 |
| 女性 | 0 | 1 |
解析には 性別_男性 か 性別_女性 のどちらかだけを使う。
参照カテゴリ(基準とかベースとか)にしたいほうがゼロのカテゴリを使う。
性別_男性 を使うと、女性を基準にした時の男性の偏回帰係数が計算される。
計算としては、女性の場合はゼロなので従属変数の推定値計算に足されず、男性の場合のみ偏回帰係数分だけ足されるという計算になる。
3カテゴリのカテゴリ変数は、以下のようにダミー変数を作ることができる。
| 該当性 | 該当性1 | 該当性2 | 該当性3 |
|---|---|---|---|
| あてはまる | 1 | 0 | 0 |
| どちらもありうる | 0 | 1 | 0 |
| あてはまらない | 0 | 0 | 1 |
2カテゴリの時は2つのうちどちらかを使った。
3カテゴリの時は、3つのうち2つを使う。
基準にしたいカテゴリが1になっている変数を使わないというルールで決める。
「基準にしたい」に迷う場合は、「ある」「いる」を使って、「ない」「いない」を使わないという方策がよい。
「(興味・特徴が)ある」ものは残し、「(興味・特徴)がない」ものを除外するという方策だと迷わない。
使わないカテゴリは、計算結果に何も出力されない。
なので、何も計算結果に出力されなくても構わないカテゴリを「基準」にするのがよい。
この場合の「基準」というのは、敢えて言うなら、特徴がなく、興味もないので、計算結果として何も返ってこなくても問題ないカテゴリという意味ととらえれば、使わないカテゴリが決められると思う。
今回の場合、あてはまら「ない」を基準にしたい場合は、該当性1と該当性2だけを使う。
この場合は、あてはまらないを基準としたときの、あてはまるとどちらもありうるカテゴリの偏回帰係数が計算される。
あてはまるを基準にしたい場合は、該当性2と該当性3を使う。
この場合は、あてはまるを基準としたときの、あてはまらないとどちらもありうるカテゴリの偏回帰係数が計算される。
では、ダミー変数はどのように作成するのか?

重回帰分析でカテゴリ変数を使う方法 ダミー変数の作り方
SPSSで、ダミー変数を作るためには、「変換」→「ダミー変数を作成」を使う。
もし「変換」メニューに「ダミー変数を作成」メニューが2つある場合、どちらを使っても構わない。
下のほうが完全に日本語化されている。
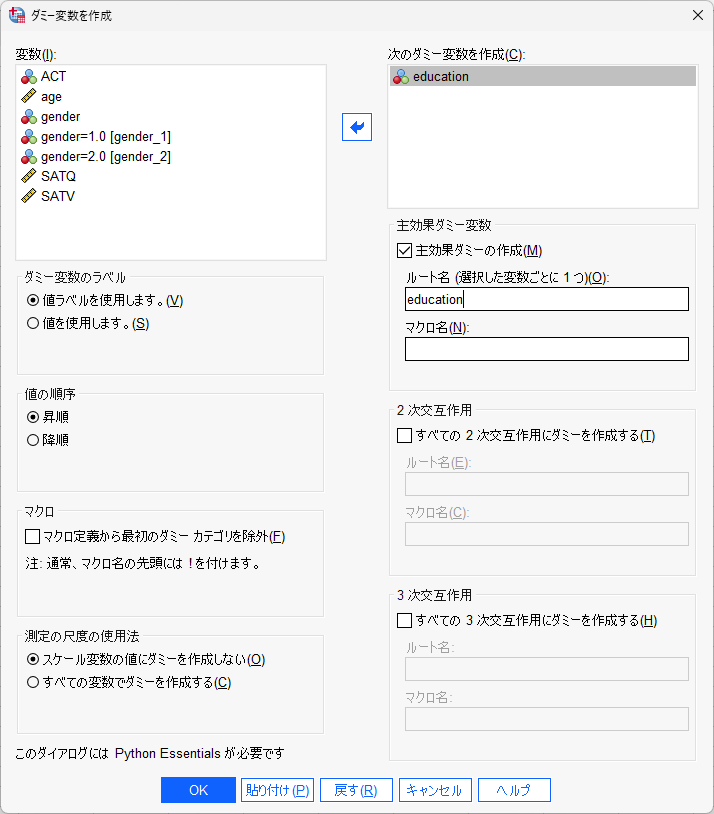
ウィンド内でgenderを作成ボックスに移し、ルート名にgenderと記載する。
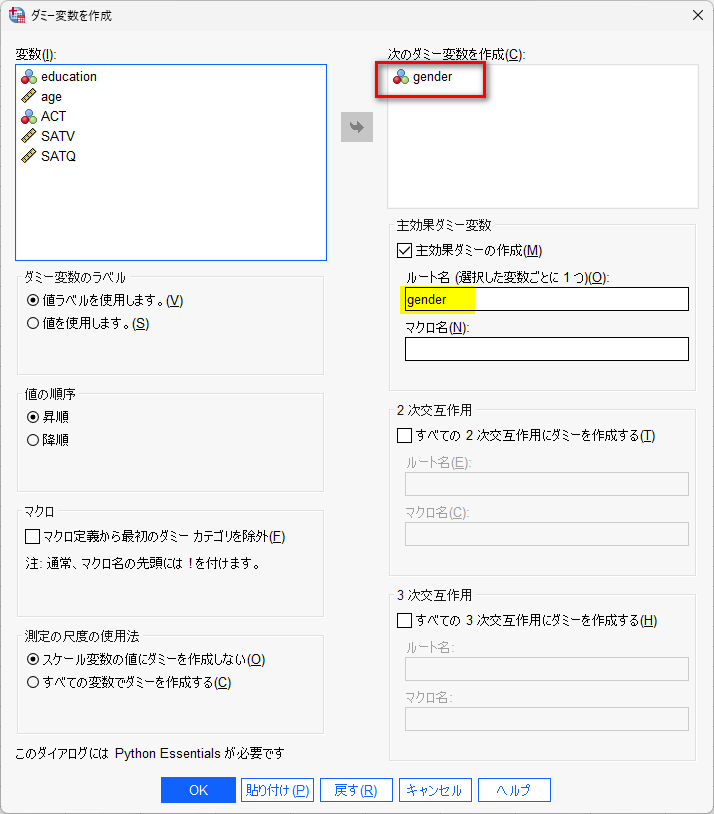
OKを押すと、ダミー変数が作成される。
変数ビューで見ると、一番最後に2つの変数が追加されているのがわかる。
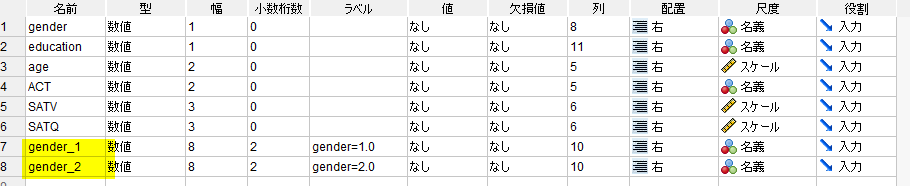
変数を並べ替えて、データビューで見てみると、元の変数とダミー変数の関係が良くわかる。
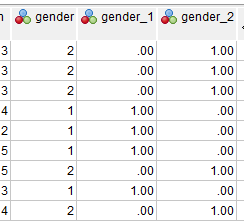
genderの場合はgender_1またはgender_2のいずれかを使えばよい。
3カテゴリ以上の場合はどうなるだろうか?
6カテゴリのeducationのダミー変数を作成してみる。
変数の指定やルート名の指定はgenderと同様である。
educationは、0から5の値がついていて、0から5が末尾1から6に変換されているので、少々わかりずらい。
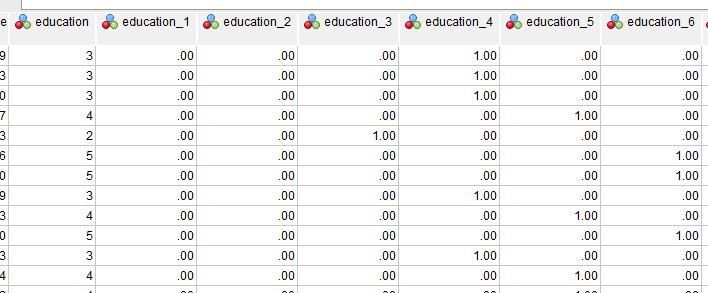
カテゴリ3の人は、education_4が1になっている。
このようなわかりにくい状態にならないように、なるべく値は1からつけておいたほうがよい。
変数ビューのラベル列を見れば、一応わかるようにはなっている。
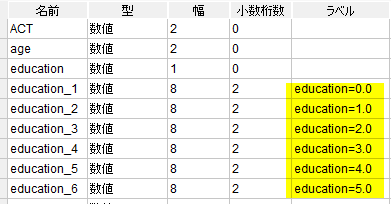
しかし、なるべくあとあと混乱しないように値のつけ方はいつも1からとか、小さいカテゴリ(例:「ない」「あてはまらない」「思わない」「一番低い」「一番短い」「一番少ない」)に必ず1をつけるとか決めておいたほうが良い。
では、作成したダミー変数をどのように使うか?
重回帰分析でカテゴリ変数を使う方法 SPSSの「線型」メニューの使い方
重回帰分析でカテゴリ変数を使う方法を、SPSSの「回帰」→「線型」を使う場合で解説する。
「分析」→「回帰」→「線型」メニューを選択する。
従属変数枠に従属変数ACTを入れる。
独立変数枠(ブロック 1/1とある枠)にage とgender=1.0を入れる。
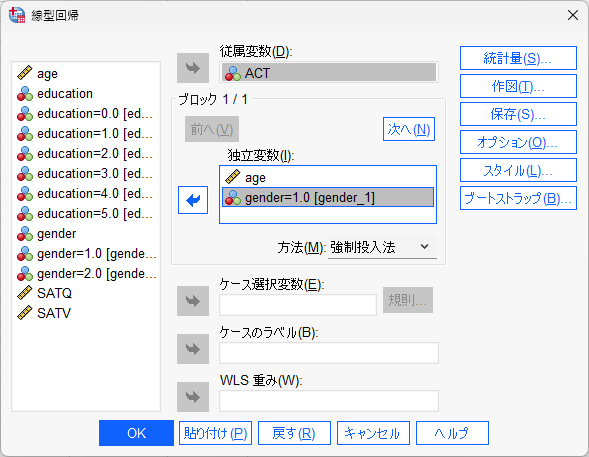
交絡因子のageを計算に入れながら、genderとACTの関係を見る。
genderは2(女性)を基準に、1(男性)の偏回帰係数を計算するというモデルである。
OKをクリックすると結果が出力される。
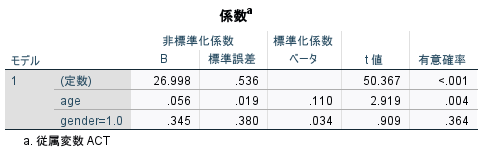
係数というタイトルの表がメインの結果である。
この表から、男性と女性の差は、統計学的有意でなく(p=0.364) 、性別はACTと関連していないことがわかる。
それでは、educationはどうか?
「分析」→「回帰」→「線型」メニューをもう一度選択する。
ageを残してgender=1.0は戻す。
ブロック枠にeducation=1.0からeducation=5.0を投入する。
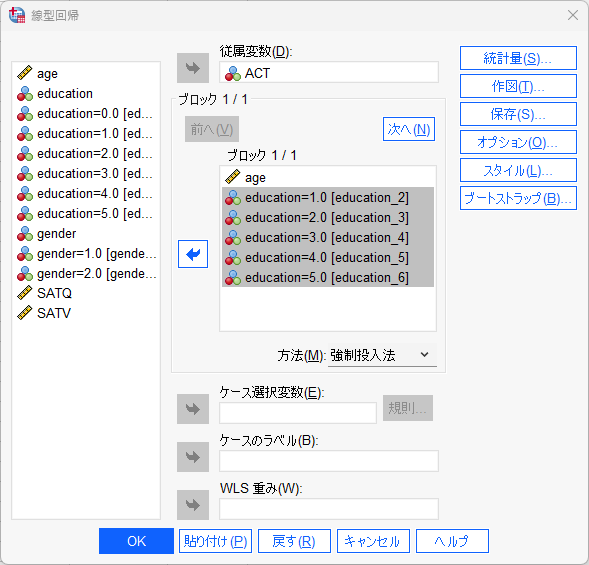
この時注意しないといけないのは、基準となるカテゴリが1となっているダミー変数は入れないということだ。
基準をeducation=0.0としたいので、1.0から5.0までを入れた。
どのカテゴリも、基準にすることは可能だ。
基準としたいカテゴリが1となっている変数を除けばよい。
これでOKをクリックすると解析される。
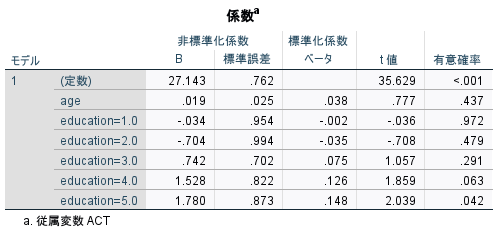
結果を見ると、education=5.0が統計学的有意(p=0.042)であることがわかる。
このことから、education=0.0を基準としたときにeducation=5.0は統計学的有意に異なっていて、偏回帰係数は1.780である。
すなわち、従属変数の推定値を1.78上昇させる。
また、標準化係数の絶対値はどの説明変数よりも大きく、この重回帰モデルの中でもっとも影響力が大きい変数である。
これでカテゴリ変数を使った重回帰分析ができた。
もちろん、genderとeducationを同時に入れた解析もできる。
このように投入する。
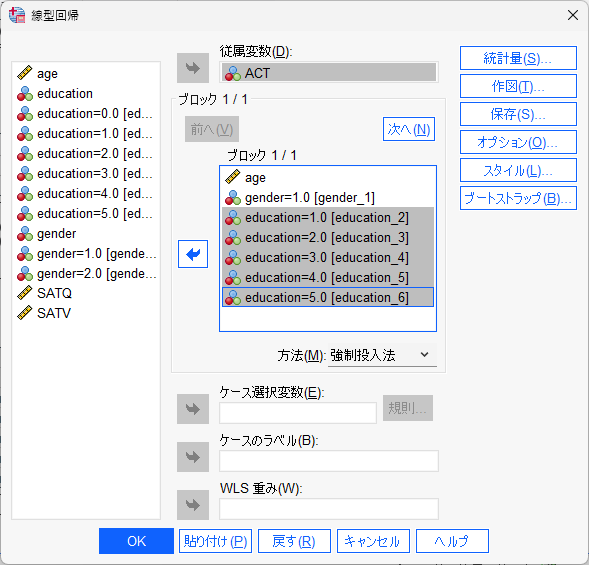
結果は以下のとおりである。
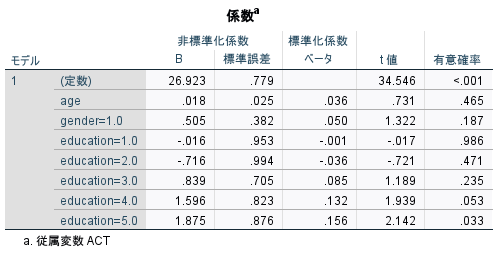
education=5.0は、少しだけ解析結果が変わったが、方向性は変わらず、統計学的有意であることには変わりない。
先行研究に照らして、年齢、性別とともに交絡因子として投入したほうが良ければ、こちらを最終モデルとする。
まとめ
重回帰分析で独立変数にカテゴリ変数を使う方法を解説した。
SPSSの「回帰」→「線型」メニューを使う場合、あらかじめダミー変数を作らないといけない。
ダミー変数は、「変換」→「ダミー変数の作成」を使えば、簡単に作ることができる。
参考になれば。


コメント
コメント一覧 (1件)
[…] SPSS でダミー変数を作成し重回帰分析でカテゴリ変数を使う方法 重回帰分析で、独立変数にカテゴリ変数を使う方法を解説する。 […]