
医療現場において、臨床予測モデルは疾患の診断、予後の予測、治療法の選択など、多岐にわたる意思決定を支援する強力なツールである。しかし、これらのモデルが誤って設定された場合、その予測は患者の健康を危険にさらし、医療資源の無駄遣いにも繋がりかねない。本記事では、臨床予測モデルの誤設定がなぜ起こるのか、そしてそれを避けるためにどのような対策を講じるべきかについて詳しく解説する。

目次
臨床予測モデルの誤設定の概要
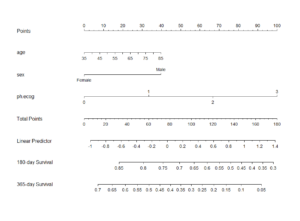
臨床予測モデルは、患者の臨床データ(年齢、性別、既往歴、検査値など)を用いて、将来起こりうるイベント(疾患の発症、死亡、特定の治療への反応など)の確率を予測する数理モデルである。これらのモデルは、統計学的手法や機械学習アルゴリズムを用いて構築される。
しかし、モデルの構築過程やその後の運用において、以下のような誤設定が生じる可能性がある。
- 不適切なデータ選択と前処理: モデル構築に使用するデータが、対象となる集団を適切に代表していない場合や、データの欠損値処理、外れ値処理が不適切である場合、モデルの予測精度は著しく低下する。例えば、特定の人種や年齢層に偏ったデータで学習されたモデルは、それ以外の集団には正確な予測を提供できない可能性がある。
- 誤った変数選択: 予測に寄与しない変数を含めたり、重要な変数を除外したりすると、モデルの性能は低下する。変数が多すぎると過学習(学習データに過剰に適合し、未知のデータへの汎化能力が低い状態)を引き起こし、少なすぎると過小学習(データの特徴を十分に捉えきれていない状態)に陥る可能性がある。
- 不適切なモデル選択: 線形モデルが適しているデータに非線形モデルを適用したり、その逆を行ったりすると、モデルの予測精度は低下する。また、複雑すぎるモデルは解釈性が低く、臨床現場での利用が困難になることがある。
- 過学習と過小学習: モデルが学習データに過剰に適合しすぎると(過学習)、未知のデータに対しては性能が著しく悪化する。逆に、モデルがデータのパターンを十分に学習できていない場合(過小学習)も、予測精度は低くなる。
- 外部妥当性の欠如: ある特定の集団や環境で開発されたモデルが、異なる集団や環境で適用された場合に、同様の予測性能を発揮しないことがある。これは、モデルが開発された環境の特性に過度に依存している場合に起こる。
- 実装時の誤り: 開発されたモデルを実際のシステムに組み込む際に、計算式の間違いやデータの入力形式の誤りなど、技術的なミスが発生することもある。
これらの誤設定は、予測の不正確さ、誤診、不適切な治療介入、患者の不安増大など、さまざまな負の影響をもたらす可能性がある。
臨床予測モデルの誤設定を避ける方策
臨床予測モデルの信頼性と有用性を高めるためには、開発から運用までの各段階で慎重なアプローチが求められる。
- 質の高いデータ収集と前処理:
- 代表性の確保: モデルの対象となる患者集団を正確に反映したデータを収集する。特定のバイアスがかからないように、多様な背景を持つ患者のデータを含めることが重要である。
- データのクレンジングと標準化: 欠損値の適切な処理、外れ値の特定と対応、データの尺度合わせ(正規化や標準化)などを徹底する。
- データの質の評価: データの完全性、正確性、一貫性を定期的に評価し、問題があれば修正する。
- 適切な変数選択とモデル構築:
- 臨床的知識との融合: 統計的手法や機械学習の手法だけでなく、医師や専門家の臨床的知識に基づいて、予測に重要な変数を慎重に選択する。
- モデルの選択と評価: データの特性や予測の目的に合わせて、適切なモデル(例:ロジスティック回帰、決定木、サポートベクターマシン、ニューラルネットワークなど)を選択する。交差検定などの手法を用いて、過学習や過小学習を避け、モデルの汎化性能を評価する。
- 解釈性の重視: 特に臨床現場で利用されるモデルでは、予測結果がなぜ導き出されたのかを理解できる解釈性の高いモデルを選ぶことが望ましい。
- 厳密なモデル評価と外部妥当性の検証:
- 多様な評価指標: 精度(Accuracy)、感度(Sensitivity)、特異度(Specificity)、陽性的中率(PPV)、陰性的中率(NPV)、ROC曲線下面積(AUC)など、目的に応じた複数の評価指標を用いてモデルの性能を多角的に評価する。
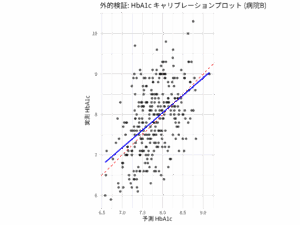
- 外部妥当性の検証: モデルを開発したデータセットとは異なる、独立したデータセットを用いてモデルの性能を検証する。異なる医療機関や地域、人種集団などでの妥当性も確認することで、モデルの汎用性を高める。
- 継続的なモニタリングと更新:
- 性能の監視: 導入後もモデルの予測性能を定期的にモニタリングし、時間の経過とともに性能が低下していないかを確認する。医療環境や治療法の変化によって、モデルの有効性が失われることがある。
- モデルの再学習と更新: 性能の低下が見られた場合や、新たなデータが利用可能になった場合には、モデルを再学習させたり、必要に応じて更新したりする体制を整える。
- 透明性と倫理的配慮:
- モデルの透明性: モデルの仕組みや予測根拠について、可能な限り透明性を確保する。特に、患者や医療従事者に対しては、予測結果の信頼性や限界を明確に伝えることが重要である。
- 倫理的なガイドラインの遵守: 患者のプライバシー保護、データのセキュリティ、予測結果がもたらす社会的・倫理的影響についても十分に考慮し、関連するガイドラインや規制を遵守する。

まとめ
臨床予測モデルは、現代医療において不可欠なツールとなりつつある。しかし、その強力な力を最大限に引き出し、かつ安全に利用するためには、誤設定を徹底的に回避することが不可欠である。
質の高いデータ収集と前処理、適切なモデルの選択と構築、厳密な評価と外部妥当性の検証、そして継続的なモニタリングと更新。これらすべてのステップにおいて細心の注意を払うことで、より信頼性の高い臨床予測モデルを構築し、患者にとって最適な医療を提供できるはずである。
医療のデジタル化が進む中で、臨床予測モデルの適切な活用は、医療の質向上と効率化の鍵を握っている。


コメント