
臨床現場でますます重要性を増している臨床予測モデル。病気の診断、予後の予測、治療効果の推定など、多岐にわたる場面で活用されている。しかし、複数のモデルが存在する場合、どのモデルが最も優れているのか、どのように判断すればよいのだろうか?
本記事では、臨床予測モデルの性能を比較するための主要な方法と、それぞれの指標の適切な使い分けについて、わかりやすく解説する。

臨床予測モデルの性能比較方法概要
臨床予測モデルの性能比較は、単に「予測が当たったか外れたか」だけでなく、その予測が臨床的にどれほど有用であるかを多角的に評価するプロセスだ。主な比較方法として、以下の3つの側面が挙げられる。
- 識別能 (Discrimination):モデルが、結果(病気の有無、イベント発生の有無など)を持つ人と持たない人をどれだけ正確に区別できるかを示す能力。
- 較正能 (Calibration):モデルが予測する確率が、実際のイベント発生確率とどれだけ一致しているかを示す能力。
- 臨床的有用性 (Clinical Utility):モデルの予測が、患者のケアや意思決定にどれほど貢献するかを示す能力。
これらの側面を評価するために、さまざまな統計的手法や指標が用いられる。
それぞれの方法の解説
1. 識別能の評価
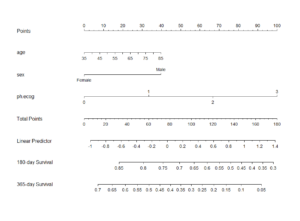
識別能を評価する最も一般的な指標は、ROC曲線 (Receiver Operating Characteristic Curve) とその下の面積であるAUC (Area Under the Curve) だ。
- ROC曲線:診断閾値を変化させたときの真陽性率(感度)と偽陽性率(1-特異度)の関係を図示したものだ。左上隅に近づくほど、識別能が高いことを示す。
- AUC:ROC曲線の下の面積で、0から1までの値を取る。1に近いほど識別能が高く、0.5はランダムな予測と変わらないことを意味する。一般的に、AUCが0.7以上であれば許容できる識別能、0.8以上であれば良好な識別能とされる。
複数のモデルを比較する場合、それぞれのモデルのAUC値を比較したり、統計的に有意差があるかを検定したりすることで、識別能の高いモデルを特定できる。
2. 較正能の評価
較正能は、モデルの予測確率が実際の観測値とどれだけ一致しているかを示す。識別能が高くても較正能が低いモデルは、臨床的な意思決定において誤った情報を提供する可能性がある。
較正能を評価するための主な方法には、以下のようなものがある。
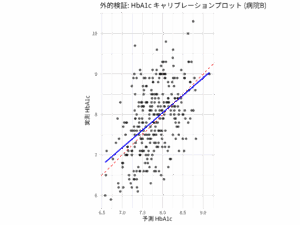
- 較正プロット (Calibration Plot):予測確率の区間ごとに、予測確率の平均値と実際のイベント発生率をプロットしたものだ。理想的には、点が45度線(対角線)上に並ぶことが望ましい。
- Hosmer-Lemeshow検定:予測確率をいくつかのグループに分け、各グループにおける予測イベント数と実際のイベント数を比較する適合度検定だ。p値が0.05より大きい場合、モデルの較正能は良好であると判断される。ただし、サンプルサイズに影響されやすいという欠点がある。
- E-statistic (Expected-Observed statistic) や Brierスコアなども較正能の評価に用いられる。
3. 臨床的有用性の評価
識別能や較正能が統計的な性能を示すのに対し、臨床的有用性は、そのモデルが実際に患者のケアや医療経済にどれだけ貢献するかを評価する。
- 意思決定曲線分析 (Decision Curve Analysis; DCA):異なる閾値確率において、モデルを使用することで得られる純粋な利益(Net Benefit)を評価する手法だ。モデルを使用することによる真の陽性と偽の陽性のバランスを考慮し、臨床的な意思決定に資するかどうかを視覚的に判断できる。
- Net Reclassification Improvement (NRI):既存のモデルと比較して、新しいモデルが患者の分類(低リスク/高リスクなど)をどれだけ適切に再分類できたかを示す指標だ。
- Integrated Discrimination Improvement (IDI):新しいモデルが既存のモデルよりもどれだけ予測能力を向上させたかを示す指標だ。
これらの指標は、モデルが臨床現場でどのように役立つかをより具体的に示すことができる。

性能比較指標の使い分け
どの指標を重視するかは、モデルの目的と臨床的な文脈によって異なる。
- スクリーニングや診断が目的の場合:識別能(AUC)が特に重要だ。高いAUCは、病気の人とそうでない人を明確に区別できる能力を示す。
- リスク層別化や予後予測が目的で、具体的な確率に基づいて治療方針を決定する場合:較正能が非常に重要になる。モデルの予測確率が実際のイベント発生率と乖離していると、誤った意思決定につながる可能性がある。
- 介入の意思決定に直接モデルを活用する場合:臨床的有用性(DCAなど)が最も重要だ。モデルが患者にとってどれだけの利益をもたらすかを評価することで、実用的な価値を判断できる。
一般的には、これらの指標を単独で評価するのではなく、組み合わせて評価することが推奨される。例えば、AUCが高いモデルであっても、較正能が低ければ臨床現場での信頼性は低くなる。逆に、較正能が良好でもAUCが低いモデルは、そもそも識別能力が不足している可能性がある。
まとめ
臨床予測モデルの性能比較は、単一の指標に頼るのではなく、識別能、較正能、臨床的有用性という3つの側面から多角的に評価することが不可欠だ。
- 識別能は、モデルが陽性と陰性をどれだけ区別できるかを示す(主にAUC)。
- 較正能は、モデルの予測確率が実際の確率とどれだけ一致しているかを示す(較正プロット、Hosmer-Lemeshow検定など)。
- 臨床的有用性は、モデルが臨床的な意思決定にどれだけ貢献するかを示す(DCA、NRI、IDIなど)。
これらの指標を適切に理解し、目的に応じて使い分けることで、より信頼性が高く、臨床現場で真に役立つ臨床予測モデルを選択し、活用することができるだろう。
臨床予測モデルの導入を検討する際は、ぜひこれらの評価方法を参考に、最適なモデルを選んでほしい。


コメント