
「適切なサンプルサイズはいくつか」
医学研究や行動科学において、研究デザイン段階で最も頭を悩ませる問題の一つである。特に、一般化線形混合モデル(GLMM)のような複雑なモデルでは、従来の簡易的な計算式では対応できないことが多々ある。
本記事では、Rの simr パッケージを使い、シミュレーション(モンテカルロ法)によって科学的にサンプルサイズを導き出す方法を解説する。

一般化線形混合モデル(二項ロジスティック)とは
「はい/いいえ」のような2値のアウトカム(二項分布)を扱い、かつ「同じ対象から複数回測定したデータ」のように、データ間の相関を考慮できるモデルである。
- 固定効果: 治療の有無や時間経過など、研究者が直接関心を持つ主たる要因を指す。
- 変量効果: 個人の体質や背景など、個人ごとに異なる「初期値のバラツキ」などを表現するものである。
サンプルサイズ計算の意義と必要性
なぜ研究を開始する前に計算が必要なのか。
特に、「観察研究で有意差が出なかったとき」にその意義は大きい。それが「本当に差がない」のか、単に「サンプル数が足りなくて差を検出できなかった(検定力不足)」のかを区別できないと、貴重な研究結果を見誤ることになるからだ。

なぜシミュレーションで行う必要があるのか
通常のロジスティック回帰でさえサンプルサイズ計算は複雑だが、GLMMでは「個人差の大きさ」や「測定タイミング」など、考慮すべき変数が極めて多い。
既存の公式に無理やり当てはめるよりも、「想定されるデータをコンピュータの中で何千回も生成(シミュレーション)し、何回有意になったかを確認する」方が、モデルの構造を正確に反映した現実的な数値を算出できるのである。
シミュレーションの主なステップ
- モデルの枠組み作成: 被験者数、測定回数、群割付などの構造を決定する。
- パラメータの仮定: 過去の文献などを参考に、期待される効果量(オッズ比)や個人差の分散を設定する。
- シミュレーションの実行: 指定した条件下でデータを繰り返し生成し、統計的検定を繰り返す。
- パワー曲線の描画: サンプルサイズを変動させ、検定力(Power)が80%を超えるポイントを特定する。
Rでの実践例
以下は、2群(Control/Test)× 4時点(0, 1, 2, 3ヶ月)のデザインで、「介入によって時間経過に伴う改善率に差が出るか(相互作用)」を検証するためのスクリプトである。
# 必要パッケージの読み込み
if(!require(simr)) install.packages("simr")
if(!require(lme4)) install.packages("lme4")
library(simr)
library(lme4)
# 再現性のためのシード設定
set.seed(123)
# 1. データ構造の定義(初期値: 1群50人、計100人)
n_subj <- 50
time_points <- c(0, 1, 2, 3)
temp_data <- expand.grid(time = time_points, subj = factor(1:(n_subj * 2)))
temp_data$group <- factor(ifelse(as.numeric(temp_data$subj) <= n_subj, "control", "test"))
# 2. ダミーデータの生成とモデル定義
temp_data$y <- rbinom(nrow(temp_data), 1, 0.5)
model <- glmer(y ~ group * time + (1|subj), data = temp_data, family = "binomial")
# 3. 効果量と変量効果の設定
# ここでは相互作用(grouptest:time)を 0.3 と設定
fixef(model) <- c(-1.0, 0.0, 0.2, 0.3) # 係数: (切片, 群間差, 時間効果, 相互作用)
VarCorr(model) <- list(subj = 0.3^2)
# 4. サンプルサイズの拡張とシミュレーション
# 1群200人(計400人)まで拡張してパワーの変化を確認
model_ext <- extend(model, along = "subj", n = 400)
pc <- powerCurve(model_ext, fixed("grouptest:time", "z"), along = "subj",
breaks = c(100, 200, 300, 400), nsim = 100)
# 5. 結果のプロット
plot(pc)
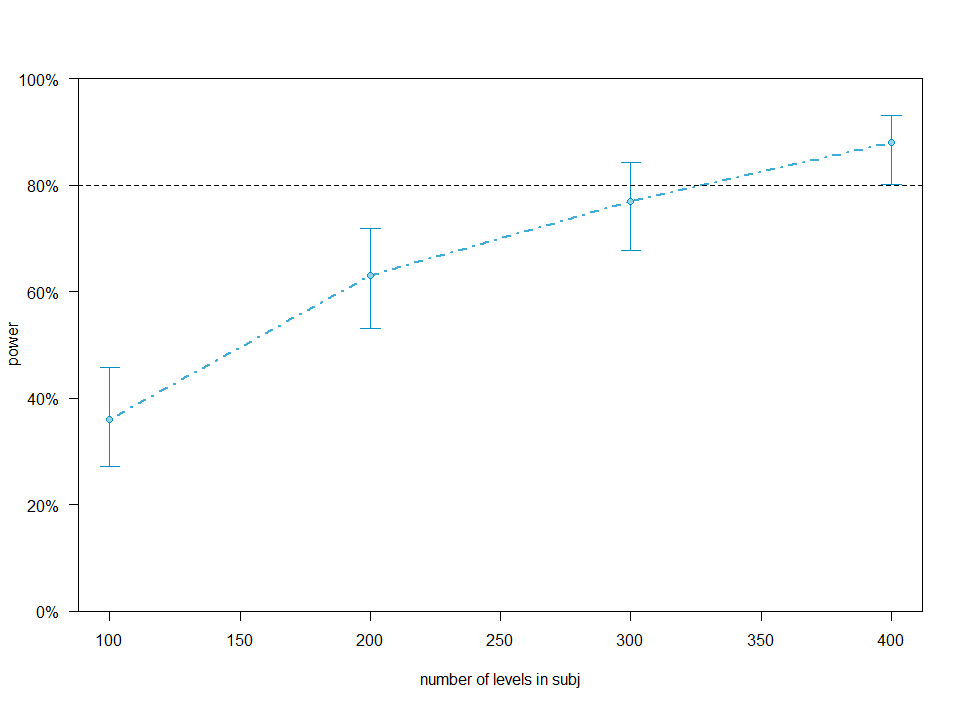
結果・パワーカーブの解釈
シミュレーションの結果、以下のようなパワーカーブが得られる。
- x軸: 被験者数(number of levels in subj)
- y軸: 検定力(power)
- 一般的に、Powerが80%を超える点が目標となるサンプルサイズである。
- 今回の設定(相互作用 = 0.3)では、350名を超えたあたりで推定値が80%を超え、400名では95%信頼区間の下限も80%を上回った。これにより「400名集めれば、十分な検定力を持って検証可能である」と判断できる。
実践におけるガイド・注意点
- 効果量(係数)の見積もり: 最も重要かつ困難なステップである。先行研究のオッズ比を対数変換(
log(OR))して設定するのが基本となる。 - 収束エラーへの対処: 二項ロジスティックの混合モデルは計算が不安定になりやすい。モデルが収束しない場合は、変量効果の構造を簡略化する検討も必要である。
- 計算時間:
nsim(試行回数)を増やすほど結果は安定するが、相応の時間が必要となる。まずはnsim=100程度で傾向を掴み、最終的な判断は1000程度で実行するのが通例である。
まとめ
GLMMのサンプルサイズ計算は、数式に頼るよりもシミュレーションを用いる方が直感的であり、かつ研究の実態に即した計画を立案できる。simr を活用すれば、複雑な相互作用モデルであっても、視覚的に説得力のある根拠を示すことが可能である。
科学的な妥当性を担保するために、解析前のシミュレーションを習慣化すべきである。
おすすめ書籍
誰も教えてくれなかった 医療統計の使い分け〜迷いやすい解析手法の選び方が,Rで実感しながらわかる!




コメント