
オッズ比をマンテル・ヘンツェル(Mantel-Haenszel)の方法で統合する方法の解説。
マンテル・ヘンツェル法は、2x2の分割表を統合する方法で、層別解析の方法。
メタアナリシスに応用する方法。

マンテル・ヘンツェル法の準備
データは以下の通り。
a <- c(3,7,5,102,28,4,98,60,25,138,64,45,9,57,25,65,17)
n1 <- c(38,114,69,1533,355,59,945,632,278,1916,873,263,291,858,154,1195,298)
c <- c(3,14,11,127,27,6,152,48,37,188,52,47,16,45,31,62,34)
n0 <- c(39,116,93,1520,365,52,939,471,282,1921,583,266,293,883,147,1200,309)
dat <- data.frame(a,n1,c,n0)
まず分析の準備。
下図と同じように変数名を作成。
オッズ比は、$ \frac{ad}{bc} $ で計算。
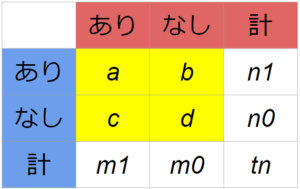
ai <- dat$a
bi <- dat$n1 - dat$a
ci <- dat$c
di <- dat$n0 - dat$c
tn <- dat$n1 + dat$n0
n1 <- dat$n1
n0 <- dat$n0
m1 <- ai + ci
m0 <- bi + di
各研究のオッズ比、標準誤差、対数オッズ比、95%信頼区間下限・上限、各研究の重みを計算する。
or <- ai*di/bi/ci
se <- sqrt(tn/bi/ci)
lgor <- log(or)
low <- exp(lgor-1.96*se)
upp <- exp(lgor+1.96*se)
w <- 1/se/se
各研究のオッズ比、95%信頼区間を並べてみる。
> round(cbind(ORi=or, LLi=low, ULi=upp),4)
ORi LLi ULi
[1,] 1.0286 0.1920 5.5103
[2,] 0.4766 0.2211 1.0274
[3,] 0.5824 0.2274 1.4912
[4,] 0.7818 0.6064 1.0079
[5,] 1.0719 0.6125 1.8760
[6,] 0.5576 0.1789 1.7377
[7,] 0.5991 0.4726 0.7594
[8,] 0.9244 0.6241 1.3692
[9,] 0.6543 0.4051 1.0568
[10,] 0.7155 0.5799 0.8826
[11,] 0.8078 0.5610 1.1633
[12,] 0.9618 0.6162 1.5015
[13,] 0.5525 0.2730 1.1184
[14,] 1.3252 0.8614 2.0387
[15,] 0.7252 0.4236 1.2416
[16,] 1.0558 0.7349 1.5169
[17,] 0.4893 0.2986 0.8020
統合オッズ比を推定し、統合オッズ比の95%信頼区間を計算する。
#----- Mantel-Haenszel Odds Ratio -----
mhor <- sum(ai*di/tn)/sum(bi*ci/tn)
#----- Variance of Mantel-Haenszel Odds Ratio -----
P <- (ai+di)/tn
Q <- (bi+ci)/tn
R <- ai*di/tn
S <- bi*ci/tn
mhv <- (sum(P*R)/sum(R)^2 + sum(P*S+Q*R)/sum(R)/sum(S) + sum(Q*S)/sum(S)^2)/2
#----- 95% confidence interval -----
mhorl <- exp(log(mhor)-1.96*sqrt(mhv))
mhoru <- exp(log(mhor)+1.96*sqrt(mhv))
list(round(c(ORmh=mhor, LL=mhorl, UL=mhoru),4))
統合オッズ比と95%信頼区間は以下の通り。
> list(round(c(ORmh=mhor, LL=mhorl, UL=mhoru),4))
1
ORmh LL UL
0.7816 0.7058 0.8655
均質性の検定(重みは漸近分散法と同じ計算方法)、有意性の検定(Petoの方法と同じ)を行う。
k <- length(ai)
w1 <- 1/(1/ai+1/bi+1/ci+1/di)
q1 <- sum(w1*(lgor-log(mhor))^2)
df1 <- k-1
pval1 <- 1-pchisq(q1, df1)
o <- ai
e <- (ai+bi)*(ai+ci)/tn
v <- ((ai+bi)*(ci+di)/tn)*((ai+ci)*(bi+di)/tn)/(tn-1)
q2 <- (abs(sum(o-e))-0.5)^2/sum(v)
df2 <- 1
pval2 <- 1-pchisq(q2, df2)
list(round(c(Q1=q1, df1=df1,P1=pval1, Q2=q2, df2=df2, P2=pval2),4))
結果はこちら。
> list(round(c(Q1=q1, df1=df1,P1=pval1, Q2=q2, df2=df2, P2=pval2),4))
1
Q1 df1 P1 Q2 df2 P2
21.4811 16.0000 0.1607 22.2667 1.0000 0.0000
マンテル・ヘンツェルでの均質性の検定は、漸近分散法の重みを使った上述の方法よりもBreslow-Day検定のほうが適切。
DescToolsパッケージの BreslowDayTest() で実施できる。
2x2の分割表の準備が手間がかかる。
array()で準備している。
all <- c(0,0,0,0)
for (i in 1:17){
new <- c(ai[i], ci[i], bi[i], di[i])
all <- c(all, new)
}
out <- all[5:72]
out.bd <- array(out,
dim=c(2,2,17),
dimnames=list(exposure=c("Beta brokade", "Control"),
event= c("Yes","No"),
site= c(paste("site", 1:17, sep=""))
)
)
library(DescTools)
BreslowDayTest(out.bd)
BreslowDayTest(out.bd, correct=T)
Breslow-Day検定の結果はこちら。
連続性補正の有無では結果変わらず。
> BreslowDayTest(out.bd)
Breslow-Day test on Homogeneity of Odds Ratios
data: out.bd
X-squared = 21.714, df = 16, p-value = 0.1527
> BreslowDayTest(out.bd, correct=T)
Breslow-Day Test on Homogeneity of Odds Ratios (with Tarone correction)
data: out.bd
X-squared = 21.714, df = 16, p-value = 0.1527
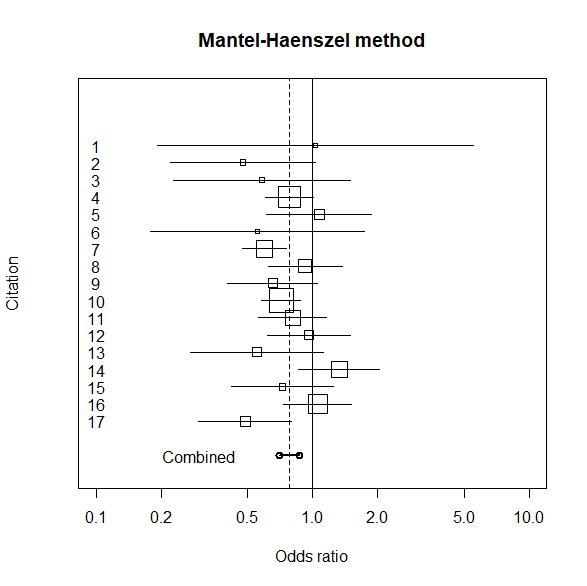
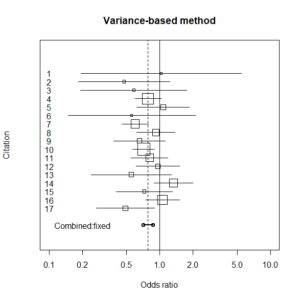
オッズ比メタアナリシスのグラフ表示
個々の研究のオッズ比95%信頼区間のグラフに、マンテル・ヘンツェルの方法で推定した、統合オッズ比と95%信頼区間を乗せて図示する。
# ------------- individual graph ----------------
id <- k:1
plot(exp(lgor), id, ylim=c(-2,20),
log="x", xlim=c(0.1,10), yaxt="n", pch="",
ylab="Citation", xlab="Odds ratio")
title(main=" Mantel-Haenszel method ")
symbols(exp(lgor), id, squares=sqrt(tn),
add=TRUE, inches=0.25)
for (i in 1:k){
j <- k-i+1
x <- c(low[i], upp[i])
y <- c(j, j)
lines(x, y, type="l")
text(0.1, i, j)
}
# -------------- Combined graph --------------
mhorx <- c(mhorl, mhoru)
mhory <- c(-1, -1)
lines(mhorx, mhory, type="o", lty=1, lwd=2)
abline(v=c(mhor), lty=2)
abline(v=1)
text(0.3, -1, "Combined")

オッズ比のメタアナリシスをmetaforパッケージで行う
metaforパッケージのrma.mh()を使った方法。
library(metafor)
rma.mh.res <- rma.mh(ai=a, bi=n1-a, ci=c, di=n0-c, data=dat)
rma.mh.res
結果は、estimate, ci.lb, ci.ub。
均質性の検定は、Test for Heterogeneity。
有意性の検定は、Cochran-Mantel-Haenszel Test。
Breslow-Day検定は、Tarone’s Test for Heterogeneity。
それぞれチェック。
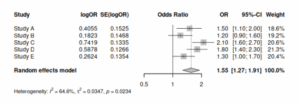
> rma.mh.res
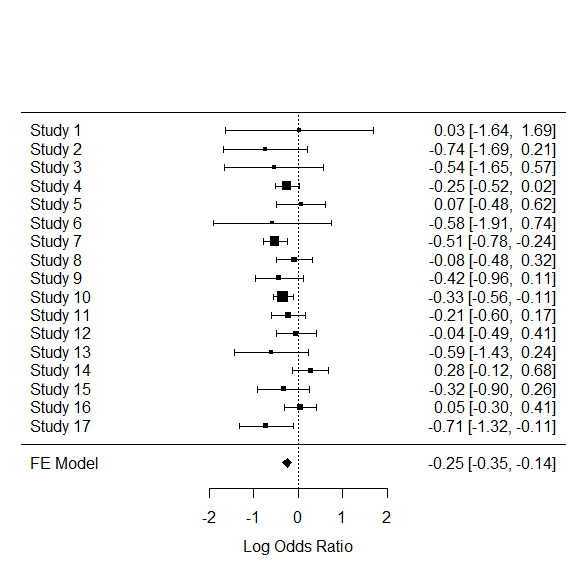
Fixed-Effects Model (k = 17)
Test for Heterogeneity:
Q(df = 16) = 21.4811, p-val = 0.1607
Model Results (log scale):
estimate se zval pval ci.lb ci.ub
-0.2464 0.0520 -4.7370 <.0001 -0.3484 -0.1445
Model Results (OR scale):
estimate ci.lb ci.ub
0.7816 0.7058 0.8655
Cochran-Mantel-Haenszel Test: CMH = 22.2667, df = 1, p-val < 0.0001
Tarone's Test for Heterogeneity: X^2 = 21.7143, df = 16, p-val = 0.1527
フォレストプロットを描くのも簡単。
forest(rma.mh.res)
まとめ
マンテル・ヘンツェルの方法でオッズ比を統合する方法を紹介した。
すべての試験で、2x2の分割表が得られて、均質性の検定で、不均質の結論がでなければ、マンテル・ヘンツェルの方法がおすすめ。
ただし、交絡要因を調整しなくていい、ランダム割付の試験に限る。
交絡要因の調整が必要な観察研究では、調整済みオッズ比と95%信頼区間から標準誤差を求めて、漸近分散法で統合するのがいい。
関連記事
参考書籍
丹後俊郎著 メタ・アナリシス入門 朝倉書店
3.1 2×2分割表 3.1.3 Mantel-Haenszelの方法―オッズ比
付録B.5 アルゴリズム3.3 mhor.s
")
新版はこちら
")




コメント
コメント一覧 (1件)
[…] […]