
各研究で無視できない異質性がある場合でも、適切にメタアナリシスできる方法の解説。

メタアナリシスのデータ準備
使用するデータは以下の通り。
a <- c(3,7,5,102,28,4,98,60,25,138,64,45,9,57,25,65,17)
n1 <- c(38,114,69,1533,355,59,945,632,278,1916,873,263,291,858,154,1195,298)
c <- c(3,14,11,127,27,6,152,48,37,188,52,47,16,45,31,62,34)
n0 <- c(39,116,93,1520,365,52,939,471,282,1921,583,266,293,883,147,1200,309)
dat <- data.frame(a,n1,c,n0)
オッズ比や標準誤差の計算は、漸近分散法と同様。
ai <- dat$a
bi <- dat$n1 - dat$a
ci <- dat$c
di <- dat$n0 - dat$c
tn <- dat$n1 + dat$n0
lgor <- log(ai*di/bi/ci)
se <- sqrt(1/ai+1/bi+1/ci+1/di)
low <- exp(lgor-1.96*se)
upp <- exp(lgor+1.96*se)
round(cbind(ORi=exp(lgor), LLi=low, ULi=upp),4)
オッズ比と95%信頼区間下限・上限。
> round(cbind(ORi=exp(lgor), LLi=low, ULi=upp),4)
ORi LLi ULi
[1,] 1.0286 0.1943 5.4454
[2,] 0.4766 0.1849 1.2287
[3,] 0.5824 0.1926 1.7611
[4,] 0.7818 0.5963 1.0250
[5,] 1.0719 0.6184 1.8581
[6,] 0.5576 0.1483 2.0964
[7,] 0.5991 0.4565 0.7862
[8,] 0.9244 0.6197 1.3788
[9,] 0.6543 0.3824 1.1194
[10,] 0.7155 0.5688 0.9000
[11,] 0.8078 0.5514 1.1836
[12,] 0.9618 0.6135 1.5081
[13,] 0.5525 0.2401 1.2713
[14,] 1.3252 0.8859 1.9822
[15,] 0.7252 0.4046 1.2998
[16,] 1.0558 0.7384 1.5096
[17,] 0.4893 0.2671 0.8965
漸近分散法で統合
比較のために、漸近分散法を計算する。
漸近分散法は、Petoの方法、Mantel-Haenszelの方法と同じく、固定効果(Fixed Effect)モデルと呼ばれる。
k <- length(ai)
# --------------- fixed effects ---------------
w <- 1/se/se
sw <- sum(w)
varor <- exp(sum(lgor*w)/sw)
varorl <- exp(log(varor)-1.96*sqrt(1/sw))
varoru <- exp(log(varor)+1.96*sqrt(1/sw))
q1 <- sum(w*(lgor-log(varor))^2)
df1 <- k-1
pval1 <- 1-pchisq(q1, df1)
q2 <- log(varor)^2*sw
df2 <- 1
pval2 <- 1-pchisq(q2, df2)

DerSimonian-Laird 法で統合
それに引き換え、無視できない異質性がある場合に使う、DerSimonian-Lairdの方法は変量効果(Random Effect)モデルと呼ばれる。
研究間のばらつきの大きさ$ \tau^2 $ を推定し、重みの分母に$ \hat{\tau}^2 $ (tau2)を足している。
# ------------- random effects ----------------
tau2 <- (q1-(k-1))/(sw-sum(w*w)/sw)
tau2 <- max(0, tau2)
wx <- 1/(tau2+se*se)
swx <- sum(wx)
varord <- exp(sum(lgor*wx)/swx)
varordl <- exp(log(varord)-1.96*sqrt(1/swx))
varordu <- exp(log(varord)+1.96*sqrt(1/swx))
qx2 <- log(varord)^2*swx
dfx2 <- 1
pvalx2 <- 1-pchisq(qx2, dfx2)
結果を見比べてみる。
# Fixed Effect
list(round(c(ORv=varor, LL=varorl, UL=varoru, Q1=q1, df1=df1,
P1=pval1, Q2=q2, df2=df2, P2=pval2),4))
#Random Effect
list(round(c(ORdl=varord, LL=varordl, UL=varordu, Q2dl=qx2,
df2dl=dfx2, P2dl=pvalx2, tau2=tau2),4))
統合オッズ比は、ほとんど変わらないが、固定効果に比べて、変量効果のほうが95%信頼区間が若干広い。
有意性の検定Q2とQ2dlはともに統計学的有意だが、変量効果のQ2dlのほうが、p値が大きく控えめな結果だ。
均質性の検定Q1の結果からは不均質とは判断できないが、$ \hat{\tau}^2 $ (tau2)が0.0169と、ゼロではないことから、変量効果モデルのほうがより適切かもしれない。
> # Fixed Effect
> list(round(c(ORv=varor, LL=varorl, UL=varoru, Q1=q1, df1=df1,
+ P1=pval1, Q2=q2, df2=df2, P2=pval2),4))
1
ORv LL UL Q1 df1 P1 Q2 df2 P2
0.7831 0.7067 0.8677 21.4798 16.0000 0.1608 21.8063 1.0000 0.0000
>
> #Random Effect
> list(round(c(ORdl=varord, LL=varordl, UL=varordu, Q2dl=qx2,
+ df2dl=dfx2, P2dl=pvalx2, tau2=tau2),4))
1
ORdl LL UL Q2dl df2dl P2dl tau2
0.7908 0.6949 0.8998 12.6794 1.0000 0.0004 0.0169
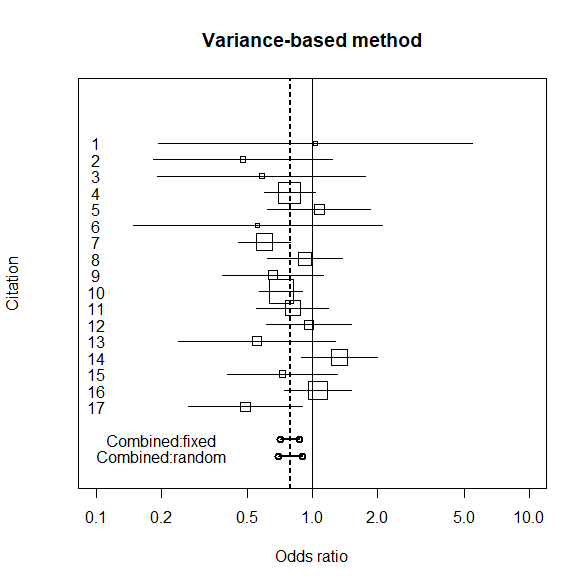
各研究結果と統合結果を図示してみる
固定効果と変量効果を同じグラフに描いた。
変量効果のほうが95%信頼区間が若干広いのがわかる。
# ------------- individual graph ----------------
id <- k:1
plot(exp(lgor), id, ylim=c(-3,20),
log="x", xlim=c(0.1,10), yaxt="n", pch="",
ylab="Citation", xlab="Odds ratio")
title(main=" Variance-based method ")
symbols(exp(lgor), id, squares=sqrt(tn),
add=TRUE, inches=0.25)
for (i in 1:k){
j <- k-i+1
x <- c(low[i], upp[i])
y <- c(j, j)
lines(x, y, type="l")
text(0.1, i, j)
}
# -------------- Combined graph --------------
varorx <- c(varorl, varoru)
varory <- c(-1, -1)
lines(varorx, varory, type="o", lty=1, lwd=2)
varordx <- c(varordl, varordu)
varordy <- c(-2, -2)
lines(varordx, varordy, type="o", lty=1, lwd=2)
abline(v=c(varor, varord), lty=2)
abline(v=1)
text(0.2, -1, "Combined:fixed")
text(0.2, -2, "Combined:random")
変量効果モデルのためにmetaforパッケージを使う方法
metaforパッケージのrma.uni()を使って、DerSimonian-Lairdの方法を実施してみよう。
escalc()で推定値と分散を計算する。
measureは何を指標にするか。今回はオッズ比。
推定値、今回はオッズ比がyiとして計算される。
分散は、viとして計算される。
rma.uni()の中で、method=”DL”とDerSimonian-Lairdの方法を指定する。
library(metafor)
dat.escalc <- escalc(measure="OR", ai=a, n1i=n1, ci=c, n2i=n0, data=dat)
res.dl <- rma.uni(yi, vi, method="DL", data=dat.escalc)
summary(res.dl)
round(exp(c(ORdl=res.dl$b, LLdl=res.dl$ci.lb, ULdl=res.dl$ci.ub)),4)
結果はこちら。
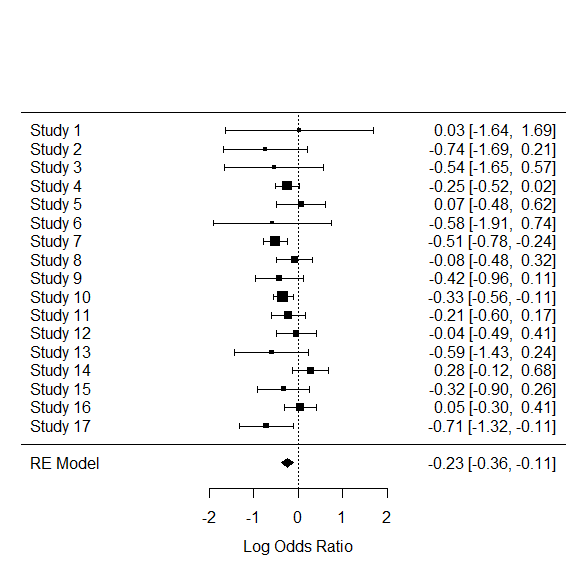
> summary(res.dl)
Random-Effects Model (k = 17; tau^2 estimator: DL)
logLik deviance AIC BIC AICc
-3.9845 20.2071 11.9689 13.6353 12.8260
tau^2 (estimated amount of total heterogeneity): 0.0169 (SE = 0.0240)
tau (square root of estimated tau^2 value): 0.1299
I^2 (total heterogeneity / total variability): 25.51%
H^2 (total variability / sampling variability): 1.34
Test for Heterogeneity:
Q(df = 16) = 21.4798, p-val = 0.1608
Model Results:
estimate se zval pval ci.lb ci.ub
-0.2348 0.0659 -3.5608 0.0004 -0.3640 -0.1055 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> round(exp(c(ORdl=res.dl$b, LLdl=res.dl$ci.lb, ULdl=res.dl$ci.ub)),4)
ORdl LLdl ULdl
0.7908 0.6949 0.8998
フォレストプロットも描いておく。
forest(res.dl)
まとめ
研究間の無視できない異質性があった場合の方法を紹介した。
均質性の検定Q1が統計学的有意であるときはもちろんのこと、統計学的有意でなくても、フォレストプロットで、均質性が怪しいと感じたら、DerSimonian-Lairdの方法をやってみてもいいかも。
漸近分散法とDerSimonian-Lairdの方法を並べて、発表しても悪くない。
参考書籍
丹後俊郎著 メタ・アナリシス入門 朝倉書店
3.1 2×2分割表 3.1.4 DerSimonian-Lairdの方法―オッズ比
付録B.4 アルゴリズム3.2 varor.s
")
新版はこちら
")




コメント
コメント一覧 (1件)
[…] R でメタアナリシス ― DerSimonian-Laird 法 […]