-

EZR で IPTW Fine-Gray 回帰を実施する方法
IPTW Fine-Gray 回帰を実施する方法 Fine-Gray 回帰とは? Fine-Gray 回帰とは、競合リスクがある場合の多変量調整回帰モデルの一つ。 詳しくは以下をどうぞ。 IPTW とは? IPTW とは、逆確率重みづけという意味である。 逆確率重み付けとは、逆確率という... -
変化量の標準偏差を推定する場合に分散の加法性が成り立たないことについて
連続量の前後比較の際に、先行研究のデータ等から、変化量の標準偏差を知りたいと思うことがある。 しかし、たいていは変化量の標準偏差は掲載されていない。 前と後、別々の標準偏差から、変化量の標準偏差が分散の加法性を使って推定できないか? 変化量... -
Comparative Interrupted Time Series とは何か どんな時に使うのが良いか わかりやすく解説
Comparative interrupted time series (CITS) は、どんな分析方法で、どんなときに使うのが良いか? CITSの前にITS 現実世界の状況として、集団全部に介入するということが起き、時系列データだけがあり、そのデータを分析せざるを得ないことはある。 その... -
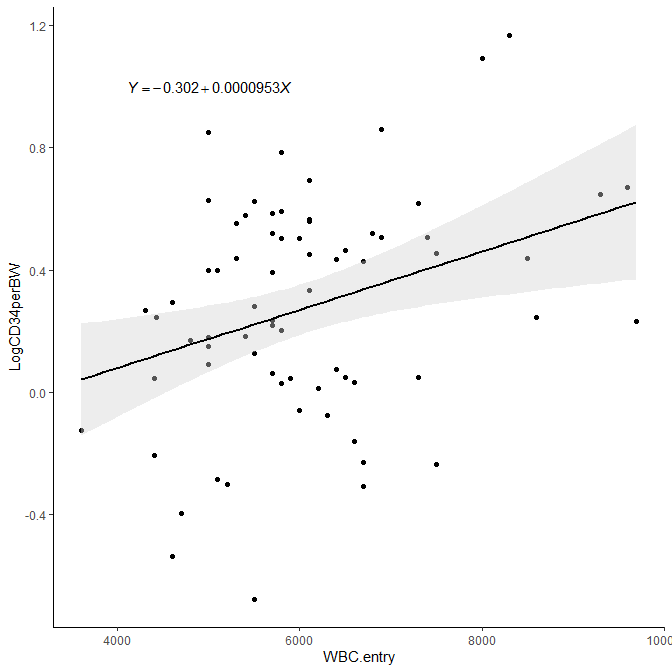
R の ggplot で書いた回帰直線に geom_smooth で 95 % 信頼区間を付ける方法
EZRで ggplot2 を使って95%信頼区間と回帰式付き回帰直線を描く方法。 EZRで回帰直線に95%信頼区間を描きたい場合どうするか? ggplot2 を使うと簡単・きれいに描ける。 ggplot で回帰直線を書く方法 ggplot2 とは? ggplot2 とは、簡単にきれいなグラフが... -
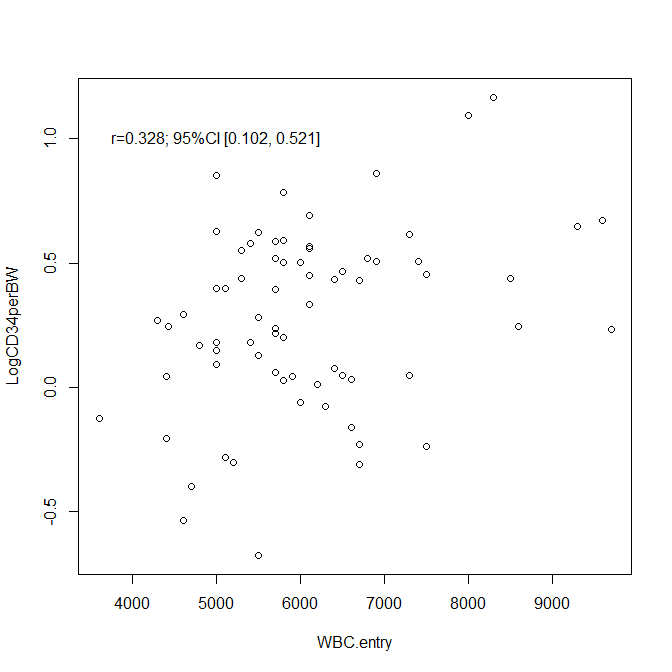
R で書いた散布図に相関係数を書き入れる方法
散布図内に相関係数と95%信頼区間を書き入れる方法 散布図を R の plot() で書く 以下のように Y 軸の変数をチルダ( ~ )の左側に書き、X 軸の変数を右側に書く。 plot(LogCD34perBW ~ WBC.entry, data=GCSF_CD34) すると、以下のように散布図が描かれる... -
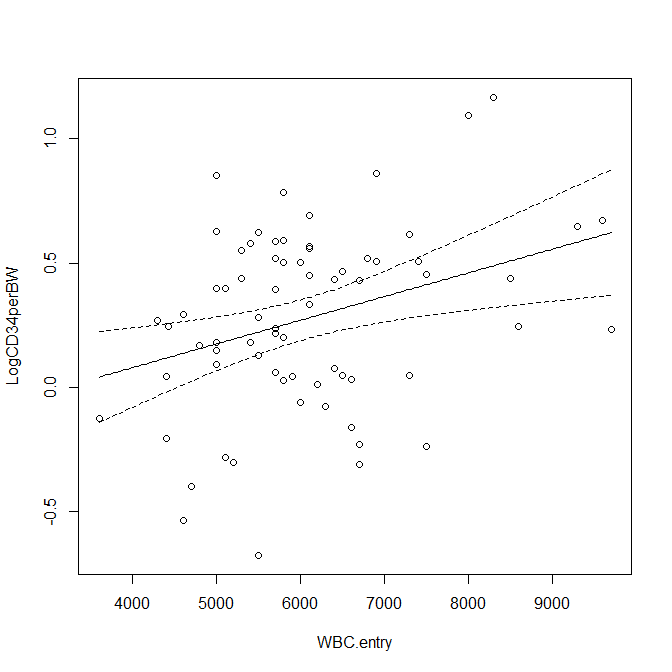
EZR で書いた回帰直線に信頼区間を付ける方法
EZRで回帰直線のグラフに95%信頼区間を付ける方法 回帰直線を書くために EZRで線形回帰(単回帰)を実行する まずEZRで単回帰を実行する。 例えば、以下のような感じに R スクリプト窓に出力される。 #####線形回帰(単回帰、重回帰)##### library(aod, pos... -
R と EZR で同等性検定に必要なサンプルサイズを計算する方法
積極的に同等であることを証明していく同等性の検定。 サンプルサイズ計算はどのようにすればよいか? 同等性検定はどのようにするのか? 同等性の検定は、簡単に言えば、非劣性検定の群を入れ替えて、片側検定を2回行うことで実施できる。 劣っていないが... -
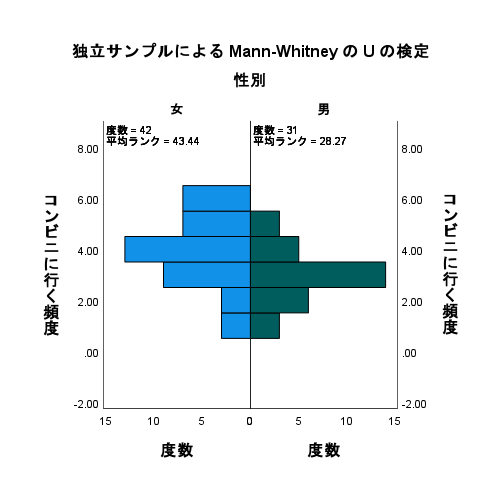
SPSS でマンホイットニーの U 検定を実行する方法
SPSSでマンホイットニーのU検定を実施するにはどうすればよいか? SPSSでマンホイットニーのU検定を実施するサンプルデータ 今回使用するサンプルデータは文末の参考書籍で紹介されているデータ。 男女別にコンビニに行く頻度を比較するという解析である。... -
EZR で指数関数データをガンマ分布の一般化線形モデルで解析する方法
指数関数的に上昇するデータを共変量調整の回帰分析したい場合どのようにすればよいか? ガンマ分布の一般化線形モデルを使えばできる。 指数関数的に上昇するデータに対して共分散分析をあてはめようとすると サンプルデータは「データ解析のための統計モ... -
ANOVA Type I Type II Type III の違い
ANOVAには3つの種類がある。 Type I, II, IIIの3つ。 どんな時にどれを使えばよいか? RにおけるANOVAの種類:Type I ANOVA Rのデフォルトで使えるANOVAは、anova()とaov()である。 これらはともにType I と呼ばれるANOVAである。 Type I は、複数の因子...