
SPSS で、一般線型モデルなどで求めることができる EM 平均(調整平均、調整推定平均、推定周辺平均など呼び方はいろいろあり)は、EZR ではどのように求めればよいか、emmeans パッケージを使って計算してみた

因子が二つで交互作用を考える場合
計算メニュー設定
まず、SPSS での設定方法は、以下のとおり
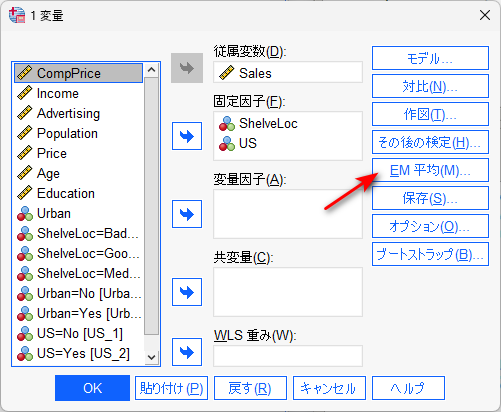
分析 → 一般線型モデル → 1 変量 を選択する
こんな感じに投入したとする
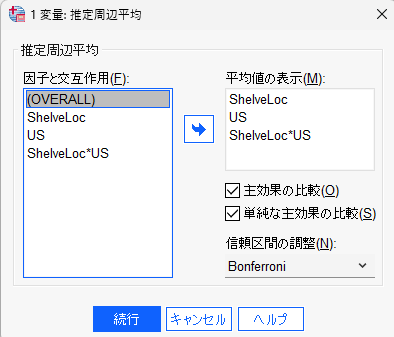
EM 平均では、以下のように設定する
これと同じことを EZR で実施するとすると以下のようになる
標準メニュー → 統計量 → モデルへの適合 → 線形モデル を選択する
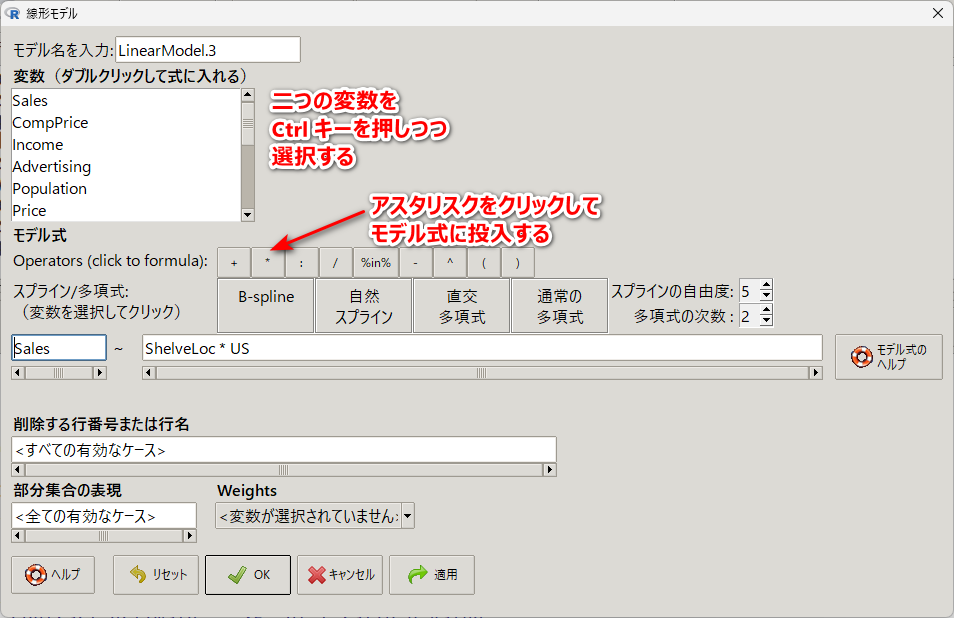
因子変数 2 つを選択して、アスタリスクをクリックして説明変数の枠に投入する
結果出力方法と結果の見方 SPSS と EZR を比較しながら
単純主効果の推定値と 95 % 信頼区間
SPSS の推定値は以下のとおり
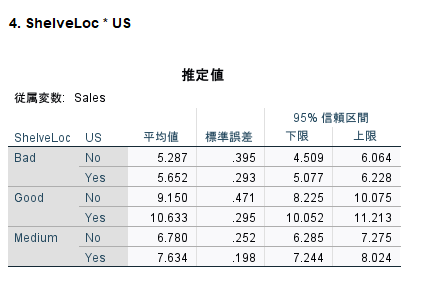
サブグループごとの平均値を単純主効果と呼ぶ
この場合、ShelveLoc Bad, Good, Medium ごとの US の Yes/No 別の平均値が計算されている
EZR では、emmeans パッケージの emmeans 関数を使用する
emmeans は事前にインストールしておく
パッケージのインストールは、R スクリプト窓に以下をコピペして、選択して実行する
install.packages("emmeans")
実行すると、Mirror Server のリストが現れるので、Japan(Yonezawa)を選択して、OK をクリックするとインストールされる(インストールは 1 回のみ)
emmeans パッケージを使うには、library で呼び出す必要がある
library(emmeans)
この一行を実行しておく
推定値を計算するには下記黄色ハイライトのモデルのところに表示されているモデル名を使う(例:今回は、LinearModel.2)

以下の 2 行を R スクリプト窓に書いて、選択して実行する
emm2 <- emmeans(LinearModel.2, spec = "US", by = "ShelveLoc") summary(emm2)
spec が比較したいカテゴリカルデータ(例題では US)、by が群別に検討したいと思っているカテゴリカルデータ(例題では ShelveLoc)
結果は、以下のとおり
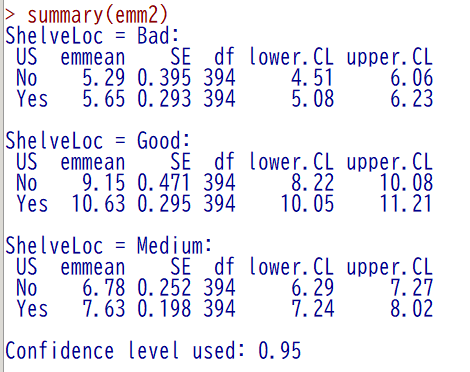
平均値(emmean)と信頼区間(CL)が小数点以下の丸めは違うものの、SPSS の結果と同様の数値になっていることがわかる
サブグループごとの群間比較
SPSS では、以下のようなペアごとの比較の出力も同時に出力される
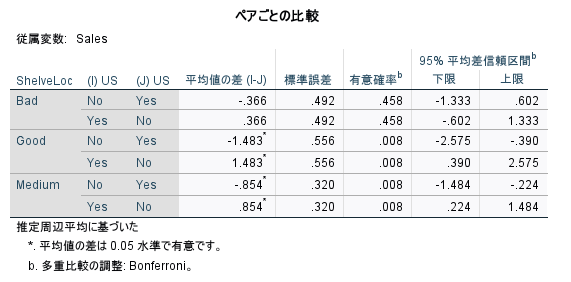
これは、ShelveLoc のカテゴリごとの US Yes vs. No の検定結果が表示されている
No – Yes と Yes – No の 2 種類が出力されているので、2 行ずつ同じ結果(符号が違うだけ)と見ればよい
EZR では、以下の一行で同じ結果を出力させられる
pairs(emm2)

No と Yes を逆にしたい場合は、reverse = TRUE を追加する
pairs(emm2, reverse=TRUE)
結果は以下のとおり
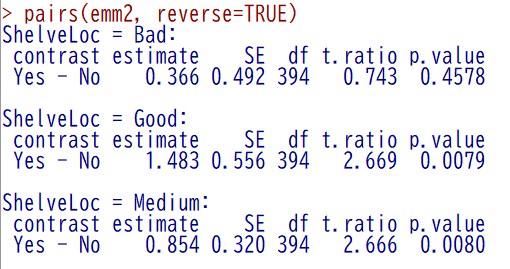
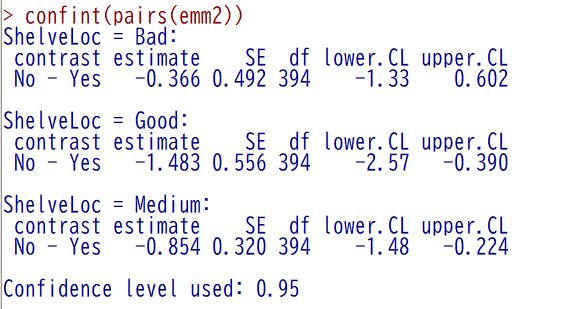
差の 95 % 信頼区間を表示させたい場合は、以下のように pairs 関数の外側に confint 関数をかぶせると出力される
confint(pairs(emm2))
因子が一つで連続データを共変量とする場合(交互作用項なし)
計算メニュー設定
SPSS の場合は、同じように、分析 → 一般線型モデル → 1 変量を選択し、以下のように変数を投入する
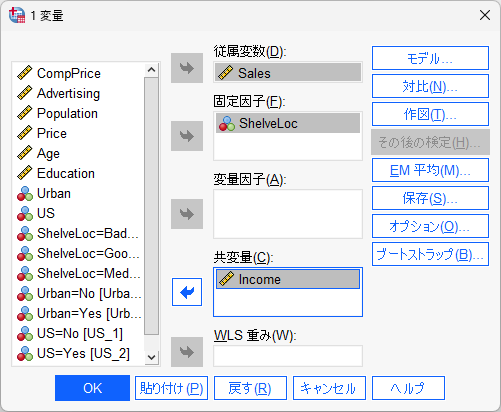
さきほどとの違いは、固定因子は一つだけで、共変量枠に連続データが入っていることだ
EM 平均の設定は、以下のようになる
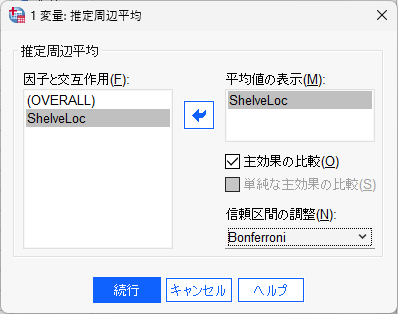
交互作用項を設定しないため、主効果となる(他の因子別の因子間比較という 2 つの因子の交互作用がないため、単純主効果という効果は計算しない)
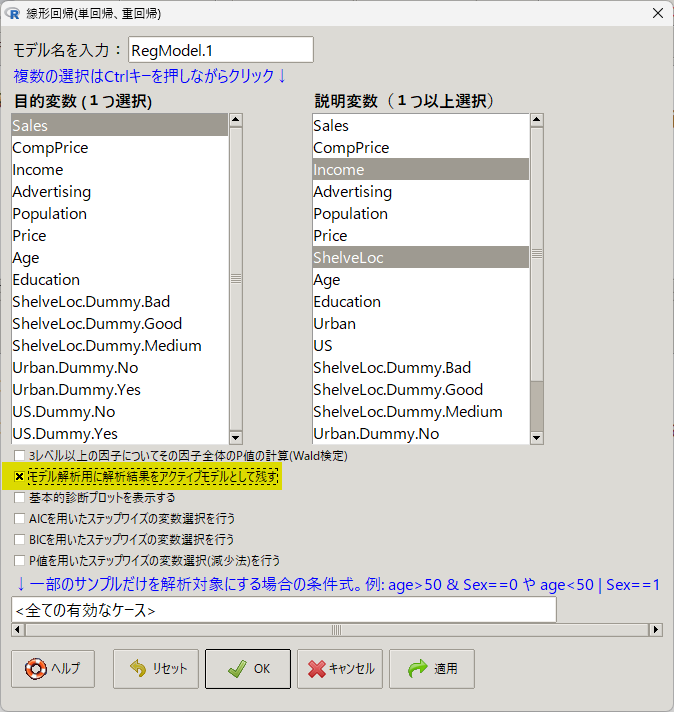
EZR の場合は、統計解析 → 連続変数の解析 → 線形回帰(単回帰、重回帰)という EZR のメニューから実行できる
その際、「モデル解析用に解析結果をアクティブモデルとして残す」にチェック
結果出力方法と結果の見方
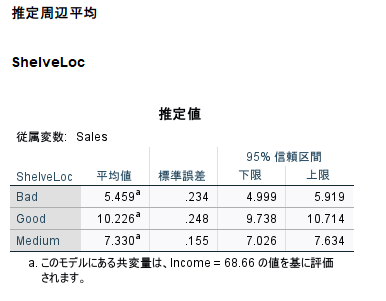
主効果 EM 平均(推定周辺平均)と 95 % 信頼区間
SPSS の場合は、以下のように出力される
EZR の場合は、emmeans パッケージを呼び出し、emmeans 関数で EM 平均を計算し、summary 関数で出力する
library(emmeans) emm1 <- emmeans(RegModel.1, spec = "ShelveLoc") summary(emm1)
結果は以下のとおり

群間比較と群間差の 95 %信頼区間
SPSS の場合は、同時に以下の表が出力される
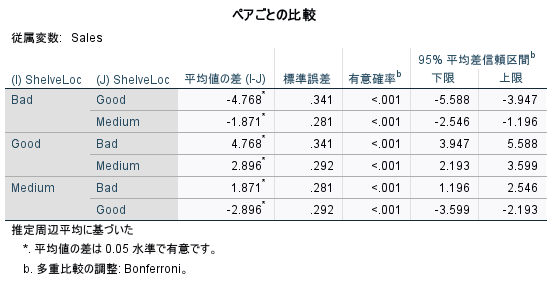
3 カテゴリの総当たりで、検定している
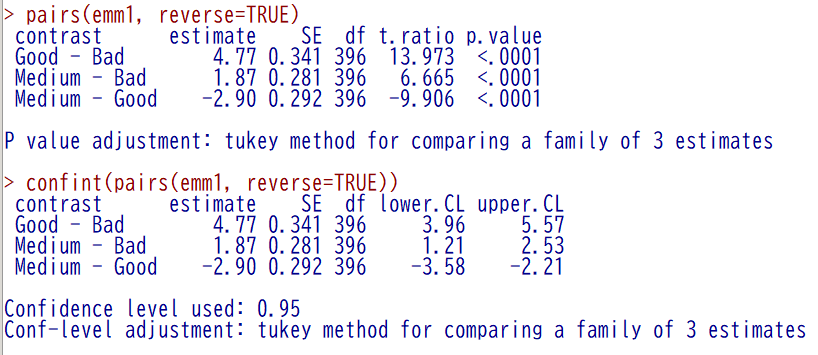
EZR の場合は、以下のスクリプトを R スクリプト枠に書いて、一行ずつ実行する
pairs(emm1) confint(pairs(emm1))
群間差の検定結果はこちら

群間差の 95 % 信頼区間はこちら

ペアを逆順にするには、reverse = TRUE を足す
pairs(emm1, reverse=TRUE) confint(pairs(emm1, reverse=TRUE))
結果が逆順(差の符号が逆、95 % 信頼区間は上下も符号も逆)になる

まとめ
SPSS と EZR で、共分散分析の群間比較における主効果・単純主効果・EM 平均を求める方法を紹介した
参考になれば



コメント