

Rでテキストマイニングするやり方。
MeCab と RMeCab を使う方法。
例として、ワードクラウドを描く方法を紹介。

テキストマイニングとは?
テキストデータを名詞、動詞、形容詞など、濃い意味合いを持つ言葉と、助詞、助動詞、感嘆詞、疑問詞など意味合いが強くない言葉に分けて、発生頻度を分析する方法。
たくさんの顧客・症例から発せられる言葉は何か、同時に発せられる言葉は何か、たくさん発せられた言葉は、どんな属性の顧客・症例が発しているのか。
分析によって、傾向・流行・トレンド、意外な結びつき、いままで見えてこなかったまれな趣味趣向など、多種多様に分散した顧客のニーズやさまざまな情報を持つことで細分化された行動をとる症例などの新たな発見につながる。
一人一人の顧客の声を、マスとしてとらえたら、どんな風景が見えるか。
それが、テキストマイニングの醍醐味だ。
テキストマイニングツールMeCab(和布蕪、めかぶ)
統計ソフトRでテキストマイニングを行うには、さきにテキストマイニングツールをインストールする。その名もMeCab(めかぶ)だ。
MeCabは、京都大学とNTTの研究所の共同研究プロジェクトで開発されたソフトウェア。以下のページから無料でダウンロードしてインストールできる。
MeCab: Yet Another Part-of-Speech and Morphological Analyzer
インストールは、基本はインストーラーのおおせのままに、OKしていくと完了するが、途中で辞書の文字コードの選択画面があるので、UTF-8を選択する。
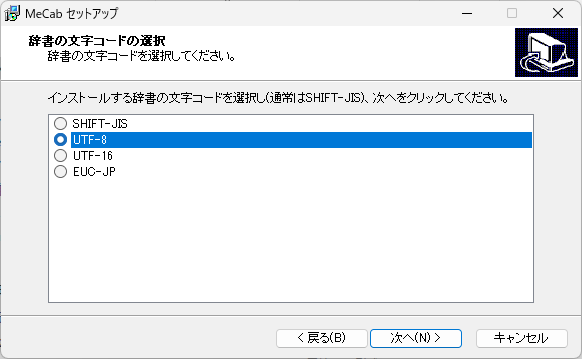
インストール後、Windowsメニューからアプリを探して起動する。
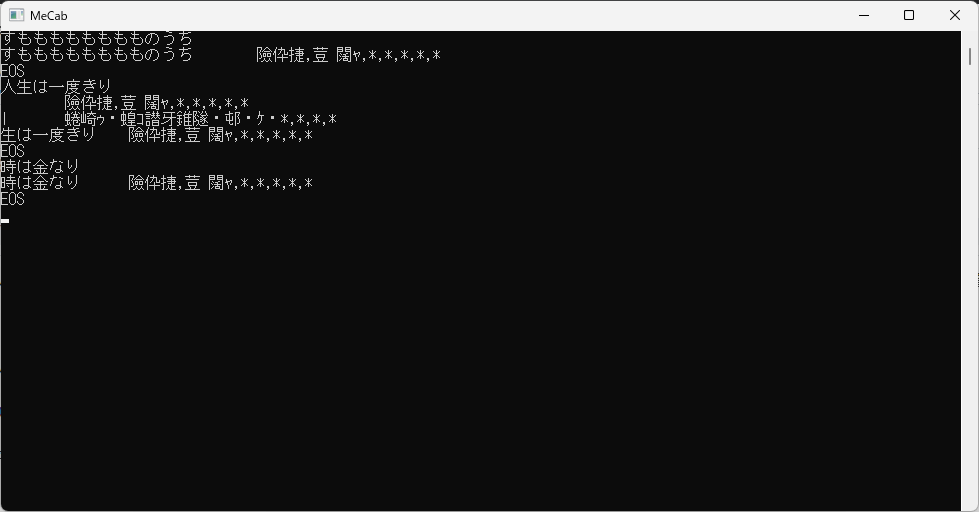
出てきた黒い窓枠に文字を書いてエンターをたたく。
すると、文字化けになってしまうが、構わずRMeCabへ進む。

RでMeCabを使うためにRMeCabをインストールする
以下のサイトからRMeCabをインストールさせてもらう。
install.packages("RMeCab", repos = "http://rmecab.jp/R")
使うときはlibrary()
library(RMeCab)
このとき、以下のメッセージが出るようであれば、MeCabをインストールしなおす必要がある。
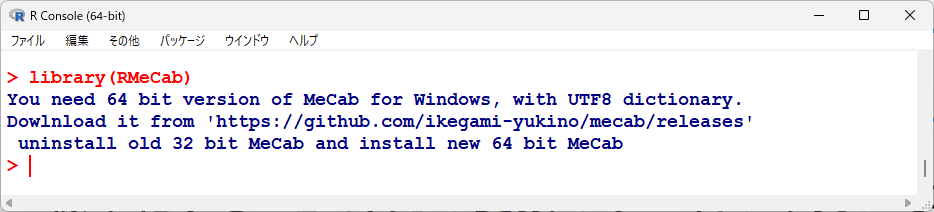
インストールの時に、上記の辞書の文字コードの選択のときに選択しなおさないと、Shift-JISになっているが、そのため文字化けする。
辞書の文字コードをUTF-8に変更する必要がある。
もしそのまま実行すると以下のような文字化けになる。
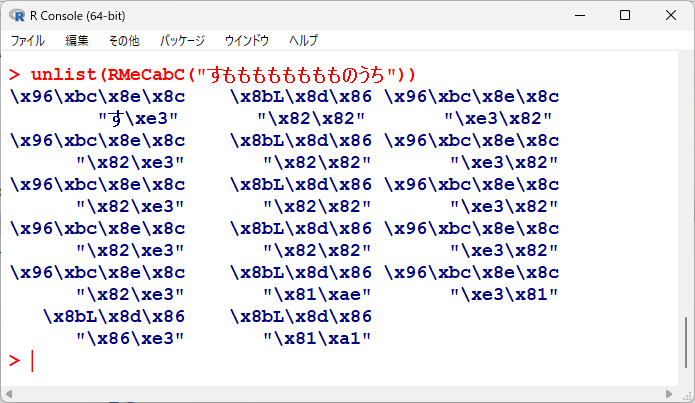
Rでテキストの分割をしてみる
時は金なりをテキスト分割してみる。
res <- RMeCabC("時は金なり")
unlist (res)
> res <- RMeCabC("時は金なり")
> unlist (res)
名詞 助詞 名詞 助動詞
"時" "は" "金" "なり"
人生は一度きりはどうか。
> res <- RMeCabC("人生は一度きり")
> unlist (res)
名詞 助詞 名詞 名詞 名詞
"人生" "は" "一" "度" "きり"
こんな感じに分割される。
このように言葉が分割されれば、発せられた回数を数えることが可能になる。
似たような言葉を集めることや、一つの文章や一人のコメントの中で同時に発せられた言葉を同定することが可能になる。
ワードクラウドとは?
ワードクラウドは直訳すれば言葉の雲。
発せられた頻度が多い言葉が大きく目立つように表示され、言葉の塊がまるで雲のように見える視覚に訴えるまとめ方。
wordcloudパッケージをインストールして使う。
install.packages("wordcloud")
ワードクラウドを作る前に、テキストデータを整理する。
今回使うのはTwitterのTweetデータ。
- テキストデータだけのファイルを用意する。
tweets.csvには投稿日時情報などが含まれる。
textという列だけを取り出して他はすべて削除した。
タブ区切りテキストにしておいた。Google Sheetを使った。
一つ注意点は、TweetsはUTF-8という文字コードだ。
MeCabをインストールするときに辞書の文字コードをUTF-8にしたので、そのままでOK。
- RMeCabFreq()で言葉を分割して集計する。
w.tweets <- RMeCabFreq("C:/data/tweets.tsv")
- 注目する品詞だけに絞る。今回は名詞だけにする。
w.tweets.n1 <- subset(w.tweets, Info1=="名詞")
- 名詞の中のさらにいらない種類を削除する。
type <- c("数","非自立","接尾")
w.tweets.n2 <- subset(w.tweets.n1, !Info2 %in% type)
kigo <- c("@", ".", "/", "t", "://", "#", ":", "co", "RT", "https", "_", "(", ")", "inc", "-", "Nn", "tlbQ", "uqSDp", "via", "ー", "♪")
w.tweets.n2 <- subset(w.tweets.n2, !Term %in% kigo)
- 高頻度の言葉順に並べ替える。
w.tweets.n3 <- w.tweets.n2[order(w.tweets.n2$Freq, decreasing=T),]
- 高頻度から必要なところまでに区切る。
n=で区切りを指定するのだが、いくつを指定すればよいかわからないため、最初は少し多めに表示させて、発言頻度例えば30回以上とかに最終的に区切れるようにn=を決める。
今回は38個まで使えば、30回以上発言している言葉がカバーできることが分かったので、n=38とした。
w.tweets.n4 <- head(w.tweets.n3, n=38)
w.tweets.n4
> w.tweets.n4
Term Info1 Info2 Freq
4752 犬 名詞 一般 271
4544 介助 名詞 一般 204
4230 ヘルプ 名詞 一般 151
5102 障害 名詞 一般 141
2256 補助 名詞 サ変接続 137
5162 人 名詞 一般 130
1689 マーク 名詞 サ変接続 117
5670 盲導犬 名詞 一般 94
7514 今日 名詞 副詞可能 90
3444 woofoo 名詞 一般 57
7377 これ 名詞 代名詞 57
4902 子 名詞 一般 56
4416 ワンコ 名詞 一般 55
1615 お願い 名詞 サ変接続 51
3099 kaijoken 名詞 一般 51
6803 日本 名詞 固有名詞 50
2870 barry 名詞 一般 49
4745 月 名詞 一般 46
4350 ユーザー 名詞 一般 45
7404 私 名詞 代名詞 44
3774 カード 名詞 一般 43
5113 情報 名詞 一般 42
7382 それ 名詞 代名詞 41
4932 視覚 名詞 一般 39
5244 全国 名詞 一般 39
5946 必要 名詞 形容動詞語幹 38
5161 身体 名詞 一般 37
5211 声 名詞 一般 37
2249 保護 名詞 サ変接続 35
2636 OpenGate 名詞 一般 35
2343 AL 名詞 一般 34
2696 SPkaeru 名詞 一般 34
1928 支援 名詞 サ変接続 33
4156 パラリンピック 名詞 一般 32
1740 応援 名詞 サ変接続 31
3113 kogumaken 名詞 一般 31
4979 自分 名詞 一般 31
7400 何 名詞 代名詞 30
ここまできて初めてワードクラウドを表示させる。
library(wordcloud)
pattern <- brewer.pal(8, "Dark2")
wordcloud(w.tweets.n4$Term, w.tweets.n4$Freq,
min.freq=30, colors=pattern)
出来上がりはこちら。出現頻度が高い言葉は大きく表示される。

Rでテキストマイニングするその他の方法
ワードクラウド以外にも共起ネットワークとか、対応分析とか、結果としてわかりやすくて、おもしろい解析はできる。
対応分析は、Tweetテキストでは対応させる属性がないという理由で分析できないため今回は割愛。
対応分析(コレスポンデンス分析)の方法はこちら。
まとめ
Rを使ったテキストマイニングを紹介した。
TwitterのTweetsテキストを用いて、MeCabとRMeCabを使った言葉の抽出と、Wordcloudパッケージを使ったワードクラウド描画を行ってみた。
Rでテキストマイニングをやろう!ワードクラウドを描こう!【解説動画】
解説動画を作ったので、よければどうぞ。
MacでMeCabをインストールしたが文字化けるときの対処法【解説動画】
MacでMeCabをインストールしたが文字化けるときの対処としては、Homebrewを使えば簡単解決!






コメント
コメント一覧 (1件)
[…] R と MeCab でテキストマイニングを行う方法 Rでテキストマイニングするやり方。 MeCab と RMeCab を使う方法。 […]