アンケート調査や臨床研究において、心理的な態度や主観的な評価を測定するために頻繁に使用されるのが「リッカート尺度」です。「非常に満足」から「非常に不満」までといった選択肢を用意し、回答者に自身の考えに最も近いものを選んでもらうこの形式は、多くの研究者にとって馴染み深いものでしょう。
しかし、いざ集まったデータを分析する段階になると、多くの人が一つの大きな壁にぶつかります。それは、「このデータを数値(連続変数)として扱って平均値を出し、t検定などを行ってもよいのか? それとも順序尺度(カテゴリカルデータ)として厳密に扱うべきなのか?」という問題です。
結論から言えば、この問いに「絶対的な正解」はありません。研究の目的やデータの性質、そしてその分野の慣習によって適切なアプローチは異なります。しかし、それぞれの方法が持つ統計学的な意味やリスクを理解せずに安易に手法を選択することは、誤った結論を導く原因となりかねません。
本記事では、リッカート尺度データの性質を深く掘り下げた上で、2つの主要な分析アプローチ(順序尺度としての分析、連続変数としての分析)について、それぞれのメリット・デメリットを解説します。これを読めば、あなたの研究に最適な統計手法を選ぶための判断基準が得られるはずです。

リッカート尺度とは? 4件法・5件法のデータの性質

リッカート尺度(Likert scale)は、主に心理学や社会調査、医療研究などで用いられる測定尺度の一つです。回答者に対して特定の質問文を提示し、それに対する同意や評価の程度を段階的な選択肢で尋ねる形式をとります。一般的には、「全くそう思わない」から「非常にそう思う」といった形容語句が用いられます。
分析手法を検討する前に、まずはこのデータの基本的な性質について理解を深めましょう。
順序尺度としての性質:「間隔は等しい」とは限らない
リッカート尺度は、本質的には「順序尺度(順序カテゴリカルデータ)」に分類されます 。順序尺度とは、選択肢の間に明確な順序(大小関係)は存在するものの、その「間隔」が数値的に等しいとは限らないデータを指します。
例えば、ある製品の満足度を以下の5段階で尋ねたとします。
- 非常に不満
- やや不満
- どちらともいえない
- やや満足
- 非常に満足
このとき、便宜上「1点、2点、3点…」と数値を割り振ることはよくあります。しかし、回答者の心理において、「非常に不満(1点)」と「やや不満(2点)」の間の心理的な距離(1点差)が、「やや満足(4点)」と「非常に満足(5点)」の間の距離(1点差)と完全に等しい保証はどこにもありません 。
温度計の目盛りであれば、10℃と11℃の差は、20℃と21℃の差と同じ熱エネルギーの違いを意味します(これは間隔尺度や比率尺度です)。
しかし、リッカート尺度における「1点の差」は、あくまで便宜的なものであり、数学的に厳密な等間隔性を保証するものではないのです。この性質が、後の分析手法の選択において大きな論点となります。
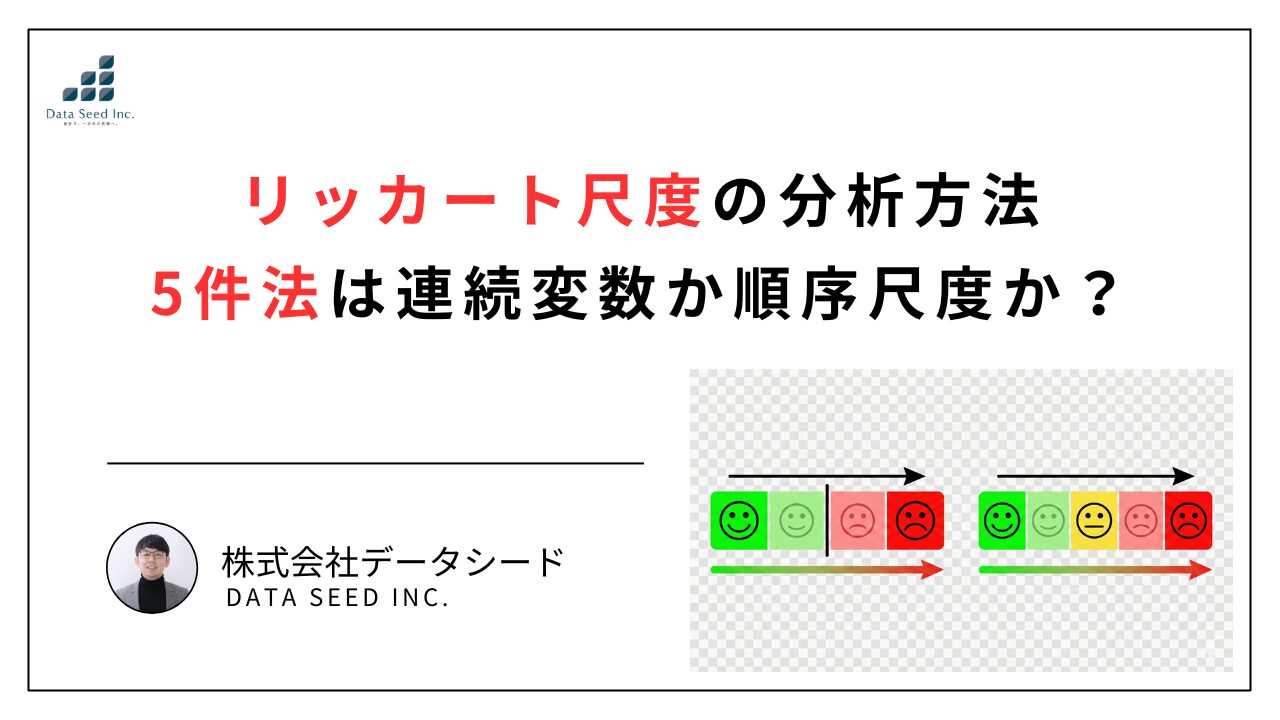
4件法と5件法の違い:中立的な選択肢の有無
リッカート尺度には、選択肢の数によっていくつかのバリエーションがありますが、代表的なものが「4件法」と「5件法」です。
- 5件法(5-point scale): 「どちらともいえない」「普通」といった中立的な選択肢が含まれます 。回答者が明確な意見を持っていない場合や、判断を保留したい場合に選択しやすいという特徴があります。データの分布としては、中央に回答が集まりやすくなる傾向があります。
- 4件法(4-point scale): 中立的な選択肢を排除し、回答者に肯定的か否定的かのどちらかの態度を強制する形式です。これを「強制的選択法」と呼ぶこともあります。日本人は「どちらともいえない」を選びがちであると言われることがありますが、4件法はそうした中心化傾向を防ぎ、意見の方向性を明確にするために用いられることがあります。
どちらを採用するかは研究デザインによりますが、分析上の扱いは基本的に同じです。5件法であれば1〜5、4件法であれば1〜4の数値を割り当ててデータ化しますが、いずれも「順序尺度である」という根本的な性質は変わりません。
リッカート尺度の分析アプローチ①:順序カテゴリカルデータとして厳密に分析する(基本原則)
リッカート尺度が本質的に順序尺度である以上、統計学的に最も厳密で「本来あるべき姿」とされるのは、データを順序カテゴリカルデータとして扱うアプローチです 。このアプローチでは、数値の間隔に意味を持たせず、あくまで「順序(大小関係)」のみを利用して解析を行います。
推奨される要約統計量:中央値と割合(%)
データを連続変数(数値)として扱わない場合、要約統計量として「平均値」や「標準偏差」を算出することは適切ではありません。なぜなら、平均値は「足し算」や「割り算」の結果であり、間隔が等しいことを前提とした計算だからです。
その代わりに用いられるのが、「中央値(Median)」や「四分位範囲(IQR)」、あるいは各選択肢を選んだ人数の「度数」や「割合(%)」です 。
- 中央値: データを大きさの順に並べたときに、ちょうど真ん中にくる値です。例えば、5人の回答が「1, 1, 5, 5, 5」だった場合、平均値は3.4ですが、中央値は5になります。リッカート尺度のような偏りが出やすいデータや、外れ値の影響を受けやすいデータにおいて、中央値は集団の代表的な値をより適切に示すことができます 。
- 割合(%): 「満足と回答した人の割合(4点以上を選んだ人の割合)」などを算出します。これは直感的にも理解しやすく、順序尺度の性質を崩さずに結果を提示できる優れた方法です。
論文やレポートでの記述例としては、「満足度は中央値4(四分位範囲:3-5)であった」や、「回答者の80%が肯定的評価(4または5)を選択した」といった表現が適切です。
統計手法:順序ロジスティック回帰分析の活用
では、要因分析や群間比較を行いたい場合はどうすればよいでしょうか。順序尺度としてデータを扱う場合に推奨される多変量解析の手法が、「順序ロジスティック回帰分析(Ordinal Logistic Regression)」です 。
順序ロジスティック回帰分析は、目的変数が3つ以上のカテゴリーを持ち、かつそれらに順序関係がある場合(例:不満 < 普通 < 満足)に特化した統計モデルです 。
通常のロジスティック回帰分析(二項ロジスティック回帰)が「イベントが起きるか否か(0か1か)」の2値を扱うのに対し、順序ロジスティック回帰は「あるカテゴリー以下になる確率(累積確率)」や「その起こりやすさ(累積オッズ)」に説明変数がどのように影響するかを分析します 。
例えば、「ある治療法を行った群(説明変数)は、行わなかった群に比べて、満足度(目的変数)が高いカテゴリーに属する傾向があるか」を検定することができます。この手法を用いれば、データの「間隔が等しくない」という性質を保ったまま、順序関係に基づいた妥当な推測を行うことが可能です。統計学的な厳密さを最優先するならば、この手法が第一選択となります。

リッカート尺度の分析アプローチ②:連続変数として扱ってパラメトリック検定やノンパラメトリック検定を行う(現実的対応)
一方で、実務や多くの研究現場では、リッカート尺度を「連続変数(連続量)」とみなして分析することが広く行われています。これは、便宜的に「1点と2点の間隔は、4点と5点の間隔と同じである」と仮定して計算を進めるアプローチです 。
なぜ、厳密には正しくないこの方法が頻繁に採用されるのでしょうか? それには実用上の大きなメリットがあるからです。
「間隔が等しい」と仮定して分析するメリット
リッカート尺度を連続変数として扱う最大のメリットは、「パラメトリック検定」と呼ばれる強力で汎用性の高い統計手法が利用可能になる点です 。
- 平均値と標準偏差の算出: データの分布を一目で把握できる「平均値」や、ばらつきを示す「標準偏差」を計算できます。「満足度の平均は4.2点」といった表現は、中央値よりも直感的に微細な差を伝えやすい場合があります。
- t検定や分散分析(ANOVA)の利用: 2群間の比較には「t検定」、3群以上の比較には「分散分析(ANOVA)」といった、統計学の教科書で必ず登場する標準的な検定手法を適用できます。これらの手法は多くの研究者にとって馴染み深く、解釈もしやすいという利点があります。
- 重回帰分析や共分散分析の適用: 他の連続変数(年齢や検査値など)と組み合わせて、より高度な多変量解析を行う際にも、連続変数扱いすることでモデルへの組み込みが容易になります。
このように、連続変数として扱うことで、分析の選択肢が広がり、結果の解釈や伝達がスムーズになるという実利的な側面があります。
連続変数扱いする際の注意点とリスク
しかし、このアプローチには常にリスクが伴います。あくまで「間隔が等しいと仮定している」に過ぎないため、その仮定が現実と大きく乖離している場合、分析結果の信頼性が揺らぐ可能性があります 。
- 前提条件の不成立: パラメトリック検定(t検定など)は、データが「正規分布(左右対称の釣り鐘型の分布)」に従うことを前提としています。しかし、リッカート尺度のデータは、天井効果(全員が5を選ぶなど)や床効果によって分布が歪むことが多く、正規分布の仮定を満たさないケースが多々あります 。
- 解釈の難しさ: 計算上「平均値 3.5」という結果が出たとしても、リッカート尺度において「3.5」という状態は現実には存在しません。「どちらともいえない(3点)」と「やや満足(4点)」の中間とは具体的にどのような心理状態なのか、厳密に定義することは困難です 。
- 精度の低下: 本来は等間隔ではないデータを無理やり等間隔として扱うことで、データの持つ情報を歪めてしまい、本来あるはずの差を見逃したり(βエラー)、逆にないはずの差を有意としてしまったり(αエラー)するリスクも否定できません。
したがって、連続変数として扱う場合には、「各選択肢が等間隔であると仮定した上で解析を行っている」という前提(リミテーション)を、研究者自身が常に意識しておく必要があります 。
>>リッカート尺度は「平均」を出してもいい?連続データとして扱う根拠と注意点
リッカート尺度の分析には結局どちらを選ぶべきか? 適切な統計手法の選び方
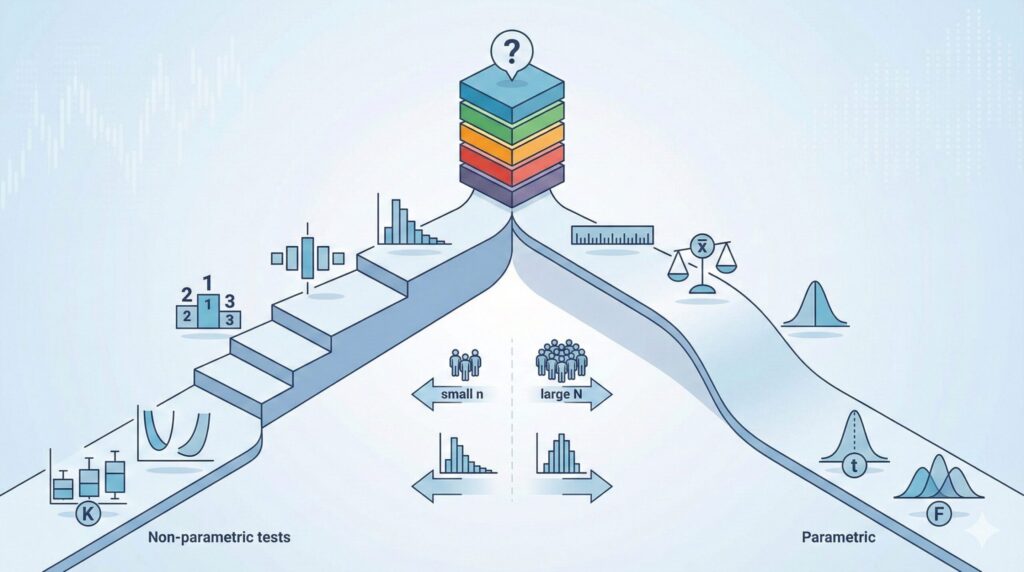
ここまで2つのアプローチを見てきましたが、結局のところ、自分の研究ではどちらを選べばよいのでしょうか。
研究目的と先行研究との整合性で判断する
どちらの方法を選ぶかに、絶対的な正解・不正解はありません。両者の特性を把握した上で、研究目的に応じて研究者自身が判断する必要があります 。判断の指針として以下のポイントを参考にしてください。
- 先行研究を確認する: あなたの研究分野(医学、心理学、社会学など)や、投稿を予定しているジャーナルにおいて、類似の研究がどのような手法を採用しているかを確認しましょう 。その分野で「リッカート尺度は連続変数としてt検定を行うのが通例」となっているのであれば、それに倣うことは合理的です。逆に、厳密さを重視する分野であれば、順序ロジスティック回帰などを選択すべきです。
- データの分布を確認する: ヒストグラムや箱ひげ図を作成し、データの分布を確認します 。もしデータが極端に偏っており、明らかに正規分布から外れている場合は、連続変数としての分析(パラメトリック検定)は避けたほうが無難です。その場合は、順序尺度として扱うか、ノンパラメトリック検定(マンホイットニーのU検定など)の利用を検討しましょう 。
- 統計専門家への相談: 判断に迷う場合は、統計の専門家に相談しながら進めることを強くお勧めします 。
また、結果の報告においては、「平均値と中央値を併記する」という方法も有効です 。パラメトリックな分析を行いつつも、ノンパラメトリックな要約統計量(中央値や四分位範囲)を併せて提示することで、データの分布特性を読者に誤解なく伝えることができます。
>>ウィルコクソンの順位和検定とは?マンホイットニーのU検定との違いは?
より精度の高い代替案:VAS(Visual Analogue Scale)の検討
もし、これから研究を計画する段階であり、より精度の高い連続データが必要であるならば、リッカート尺度ではなくVAS(Visual Analogue Scale:視覚的アナログ尺度)の導入を検討するのも一つの手です 。
VASとは、例えば長さ100mmの直線を提示し、左端を「全くない(0)」、右端を「想像できる限り最大(100)」と定義して、回答者に自分の感覚に該当する位置に印をつけてもらう方法です。
回答者は「左端から何mm」という形で回答するため、得られるデータは0〜100の連続量となります。VASで得られたデータであれば、間隔や順序の悩みを抱えることなく、堂々と連続変数として扱い、平均値の算出やパラメトリック検定を行うことができます 。痛みの評価などでよく用いられる手法ですが、満足度や主観的な評価全般に応用可能です。

まとめ
リッカート尺度(4件法・5件法)の分析方法には、大きく分けて2つの道があります。
- 順序カテゴリカルデータとして扱う(厳密なアプローチ):
- 要約には「中央値」や「割合」を用いる。
- 解析には「順序ロジスティック回帰分析」やノンパラメトリック検定を用いる。
- 統計学的な妥当性が高い。
- 連続変数として扱う(現実的なアプローチ):
- 要約には「平均値」や「標準偏差」を用いる。
- 解析には「t検定」「分散分析」「重回帰分析」などのパラメトリック検定を用いる。
- 分析の選択肢が多く、解釈が直感的だが、「間隔が等しい」という仮定が必要。
どちらを選択するかは、データの分布状況、研究の目的、そして先行研究の慣例を総合的に判断して決定しましょう。重要なのは、選んだ手法の限界と前提条件を理解し、誠実に結果を報告することです。迷ったときは、VASのような代替手法の検討や、専門家への相談も視野に入れつつ、最適な分析計画を立ててください。








コメント