この記事では、予測研究における内的妥当性と外的妥当性に関して、重要性や考え方をわかりやすくお伝えしています。
また、外的妥当性に関しては最近提案されている、Internal-External Cross Validationといった方法も含めて紹介します。
論文アクセプトに少しでも近付くように、本内容をぜひ理解しましょう!

予測研究における妥当性の評価とは?内的妥当性と外的妥当性の違い
予測研究において、モデルがどの程度「使える」のかを判断するためには、妥当性の評価が欠かせません。
単にモデルを構築するだけでは、その予測性能が信頼できるかどうかはわかりません。
そこで、内的妥当性(internal validation) と 外的妥当性(external validation) を区別し、それぞれの方法で評価を行う必要があります。

内的妥当性の評価
内的妥当性は、開発データあるいは同一集団の中でモデルがどれだけ予測力を発揮できているかを確認するものです。
つまり、モデルが開発時に用いたデータに対して過不足なくフィットしているかを評価するもの。
例えば、ある病気の発症を予測するために年齢・性別・血圧・喫煙歴を説明変数としたロジスティック回帰モデルを構築したとします。
このとき「内的妥当性が高い」とは、その研究で集められた対象者のデータに対して、モデルが適切に予測精度を発揮している状態を指します。
主な方法は以下の通りです。
- 見かけの予測能(apparent performance)
- 開発データそのものに対する予測能を評価する方法。
- AUC(C統計量)やCalibration slope(予測確率と実測の整合性)を算出する。
- ただし、開発データに最適化されているため、過大評価になりやすい。
- 交差検証(cross-validation)
- データを複数のサブセットに分割し、交互に学習と検証を行う方法。
- 開発集団の中での安定性を確認できる。
- ブートストラップ法(bootstrapping)
- 元データから再標本を繰り返し抽出し、そのたびにモデルを構築して性能を評価する。
- モデルの過剰適合を補正した「optimism-corrected performance」を得られる。
これらの手法を通じて、開発データ内でのモデルの適切さを確認し、過剰適合のリスクを把握することが可能です。
外的妥当性の評価
一方、外的妥当性とは「研究の外に一般化できるか」という視点です。
すなわち、開発に使わなかった別のデータにおいても、モデルが同じように予測能を発揮できるかどうかを問います。
例えば、ある大学病院で作られた心血管リスク予測モデルが、地域のクリニックや他国の医療機関でも同様に機能するのか。あるいは、特定の年齢層で開発したモデルが、別の年齢層や背景を持つ患者集団でも通用するのか。
これらを確認するのが外的妥当性です。
外的妥当性を評価するには、以下の方法がよく用いられます。
- 独立データセットによる検証
- 開発データとは異なる施設・地域・時期に収集されたデータを用いる。
- 最も信頼性の高い外的妥当性評価。
- 地理的・時間的外部検証
- 地理的:別施設・別地域でのデータを用いる。
- 時間的:開発時期とは異なる期間のデータを用いる。
- サブグループ検証
- 年齢・性別・疾患背景など異なる患者層で予測能を確認する。
外的妥当性を検証することにより、モデルの一般化可能性が担保され、臨床現場や他の研究環境での利用が正当化されます。
予測モデルの妥当性評価のための評価指標
予測モデルの妥当性を評価する際には、複数の指標を組み合わせて解釈することが重要です。
- 識別能(discrimination)
- モデルがイベント発生群と非発生群を区別できる力。
- 代表指標:AUC(C統計量)、Harrell’s C-index。
- 適合度(calibration)
- 予測された確率と実際の発生率がどの程度一致しているか。
- Calibration plotなどで評価。
- 臨床的有用性
- モデルを使うことで臨床意思決定が改善するかどうか。
- Decision curve analysis(DCA)などを利用。
内的妥当性・外的妥当性のいずれの検証でも、これらの指標を組み合わせて解釈することが求められます。
内的妥当性と外的妥当性にはトレードオフの視点が必要
予測モデル研究には、「内的妥当性を追求しすぎると外的妥当性が損なわれる」というトレードオフがあります。
開発データに過度に適合させると、外部データでの性能が落ちる=オーバーフィッティングの状態になります。
逆に、外的妥当性を重視しすぎるとモデルが単純化され、開発集団での予測能が十分に得られない場合もあります。
したがって、研究者は「開発データでの適合」と「外部データへの一般化」のバランスを意識し、モデル構築から検証まで一貫した戦略を取ることが求められます。
IECV(内部–外部クロスバリデーション)とは?
予測モデル研究では、外的妥当性(generalizability) を示すことが必須です。
しかし、多施設データをまとめて「7:3にランダム分割」しても、開発と検証は同じ集団からのデータであり、真の外的妥当性とは言いにくいです。
そこでTRIPOD-Clusterが推奨するのが 内部–外部クロスバリデーション(IECV) という方法。
IECVの方法(例:施設ABCDE)
- 施設ごとに外部検証データを設定
- Aを検証用に外し、B+C+D+Eでモデルを開発 → Aで検証
- Bを検証用に外し、A+C+D+Eでモデルを開発 → Bで検証
- …以下、すべての施設について繰り返す
- 施設ごとに外的妥当性を評価
- 各施設で、C統計量(AUC)、Calibration slope、Brierスコアなどを算出
- 「施設Aでは良好だが、施設Bでは性能が低下」など、施設間の差を明らかにする
- 結果を統合
- 全施設の評価指標を統合し、平均的な外的妥当性を算出
施設間のばらつき(異質性)も評価可能(ランダム効果メタ解析のイメージ)です。
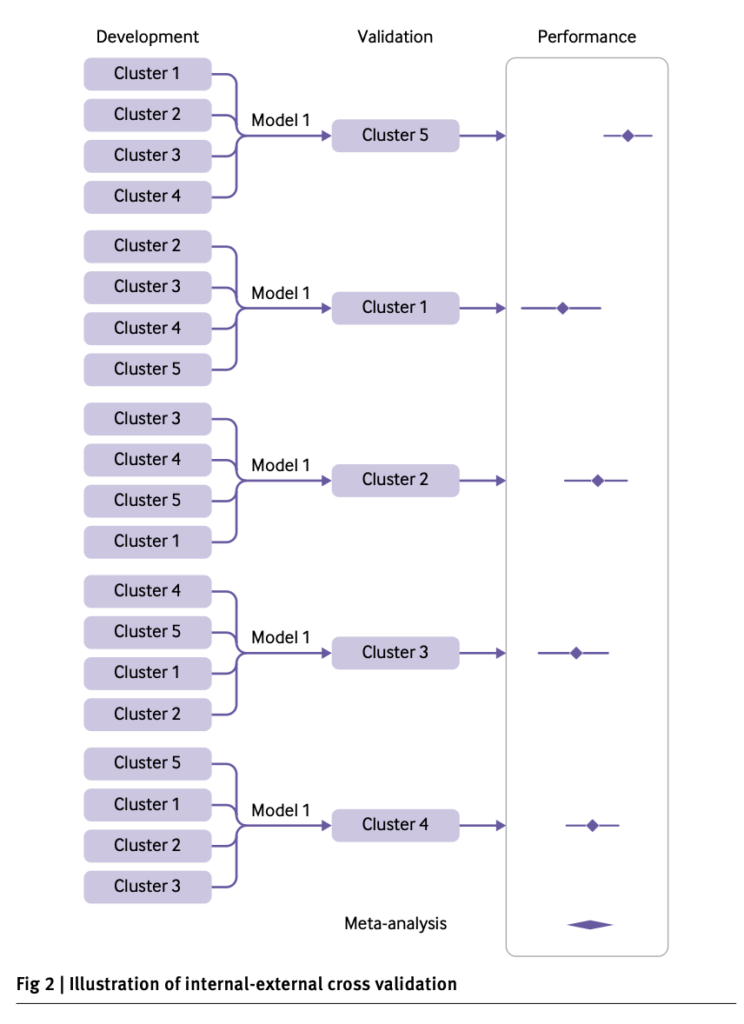
画像引用:Thomas P A Debray et al., 2022
TRIPOD-Clusterでの位置づけとIECVのメリット
TRIPOD-Clusterは、IECVを「クラスター化データにおける外的妥当性評価の基本手法」と位置づけています。
特に多施設共同研究では、IECVを行うことで、
- モデルの 一般化可能性
- 施設間の予測性能のばらつき
の両方を示すことが可能になります。
これにより、下記のメリットが期待できます。
- 真の外的妥当性を評価できる
- 施設を完全に独立データとして扱うため、「新しい集団でも通用するか」を直接検証できる。
- 施設間の異質性を明示できる
- 「このモデルは都市部の病院では有効だが、地方病院では性能が低い」といった特徴を把握できる。
- データを無駄にしない
- 7:3分割のように開発データを削らず、全データを活用できる

そもそも妥当性とは?妥当性と信頼性の違い
予測研究を理解するうえで混同されがちな概念に、「妥当性(validity)」と「信頼性(reliability)」があります。
どちらも研究の質を語る際に頻繁に登場しますが、意味するところは大きく異なります。
ここでは特に多変量解析による予測モデルを念頭に、その違いを整理していきます。
妥当性とは何か?
妥当性とは、予測モデルが「本当に測りたいものを測れているか」「研究の目的に沿った正しい推定ができているか」を指します。つまり「正確さ」に関わる概念です。
予測モデルにおける妥当性を考えるとき、先に説明した内的妥当性と外的妥当性に分けて考えるとわかりやすいでしょう。
- 内的妥当性:モデルが開発集団の中でどの程度うまく予測できているか
- 外的妥当性:そのモデルが別の集団や環境でも予測性能を維持できるか
妥当性が高いとは、「モデルが本来の目的に即して適切に機能している」ということです。
信頼性とは何か?
一方、信頼性は「測定や予測の一貫性」を指します。つまり、同じ条件で繰り返し評価したときに同様の結果が得られるかどうか、という安定性の問題です。
例えば、同じ患者集団で同じ予測モデルを複数回適用したとき、予測確率や判別性能が大きく変動しないのであれば、そのモデルには高い信頼性があるといえます。
逆に、データの取り扱いが少し変わるだけで結果が大きく揺らぐ場合は、信頼性が低いと評価されます。
信頼性は「正しさ(validity)」とは別物であり、たとえ一貫性が高くても間違った方向に安定していることもあります。
その場合は「信頼性は高いが妥当性が低い」という状態になります。
妥当性と信頼性の違いを例で考える
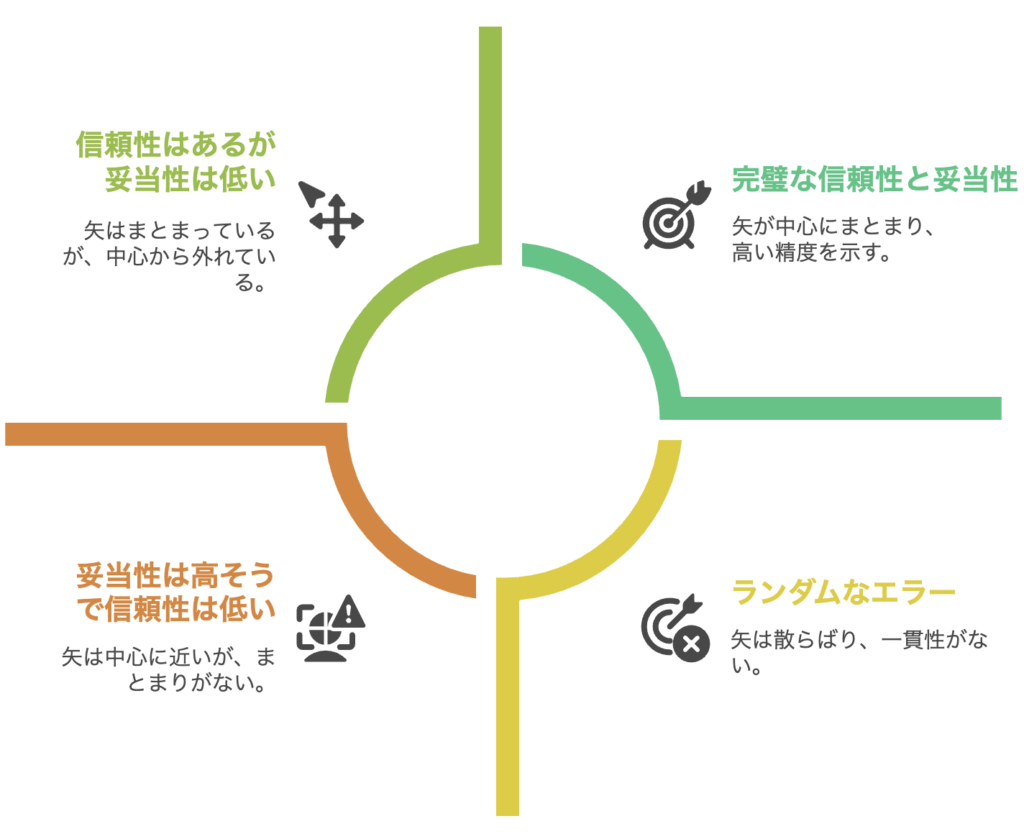
よく使われる比喩に「的当て」のイメージがあります。
- 的の中心を「真の値」とすると、妥当性は矢が中心に近いかどうか(正確さ)
- 信頼性は矢が同じ場所にまとまって刺さっているかどうか(一貫性)
つまり、矢がすべて中心から外れた同じ位置に集まっている場合は「信頼性は高いが妥当性が低い」。
逆に、矢が中心の周囲にまばらに散らばっている場合は「妥当性はまずまずだが信頼性が低い」ということになります。
予測研究における妥当性と信頼性
予測研究では、妥当性と信頼性の両立が求められます。例えばロジスティック回帰で構築した予測モデルが、同じ患者集団で繰り返し使っても似た結果を返すのであれば「信頼性が高い」と言えます。
しかし、それが本当に疾患リスクを正しく反映しているか(妥当性)は別問題です。
特に予測モデルの一般化可能性を議論する際には、外的妥当性の観点が欠かせません。
開発集団における信頼性や内的妥当性だけを確認しても、それが異なる患者群で通用するとは限らないからです。
外的妥当性とオーバーフィッティングの関係
ここで重要なのが、外的妥当性の評価はオーバーフィッティングを見抜く役割も果たすという点です。
予測モデルは、開発データに適合させすぎると一見高い精度を示しますが、未知のデータでは急激に性能が低下します。
これは「内的妥当性は高く見えるが外的妥当性が低い」典型的なケースであり、まさにオーバーフィッティングの問題です。
外的妥当性の検証を行うことで、開発時には見えなかった過剰適合が明らかになり、モデルの改良や変数選択の見直しを促すことができます。
したがって外的妥当性の検証は「一般化可能性の確認」という本来の目的に加え、「過剰適合を検出・改善するプロセス」としても重要なのです。
研究の一般化可能性とは
予測研究において重要な問いのひとつは、「このモデルは他の集団や環境でも使えるのか?」という点です。
この問いに答える概念が研究の一般化可能性(generalizability)です。
一般化可能性は、しばしば外的妥当性とほぼ同義で使われることもありますが、厳密には「研究結果や予測モデルを、開発に使われなかった別の対象に適用できる程度」を指します。
一般化可能性の基本的な考え方
研究の一般化可能性とは、「研究で得られた知見やモデルが、研究集団を越えて別の対象集団にも通用するか」という問いへの答えです。
臨床研究では「この治療効果は他の病院や他の患者にも当てはまるのか?」、予測研究では「このモデルは異なる患者群でも精度を保てるのか?」というかたちで議論されます。
たとえば、ある病院で構築された心血管リスク予測モデルがあるとします。開発対象は50〜60歳の男性患者でした。
このモデルが70代女性の患者や、別の地域の医療機関の患者にも適用可能かどうかが「一般化可能性」です。
もしその集団で予測能が著しく低下するなら、そのモデルの一般化可能性は乏しいことになります。
一般化可能性と外的妥当性
一般化可能性は外的妥当性と深く関わっています。外的妥当性が高ければ、そのモデルは多様な集団で安定した予測性能を発揮できるため、一般化可能性が高いといえます。
外的妥当性の検証にはいくつかの方法があります。
- 地理的外的妥当性:別の施設や地域のデータで検証する
- 時間的外的妥当性:異なる時期に収集したデータで検証する
- 集団外的妥当性:異なる背景(年齢層、性別、疾患背景)を持つ集団で検証する
これらの検証を通じて、研究の一般化可能性を評価することができます。
一般化可能性を損なう要因
予測研究における一般化可能性を低下させる主な要因は以下の通りです。
- 対象集団の限定性
研究対象が特定の年齢層・性別・疾患群に偏っている場合、他の集団では当てはまらない可能性が高い。 - 研究環境の特殊性
特定の医療機関の診療体制や検査方法が前提となっていると、別の環境では結果が再現できない。 - 過剰適合(オーバーフィッティング)
開発データに過度に適合したモデルは、未知のデータでは性能を維持できず、一般化可能性を著しく損なう。
このうち過剰適合は、予測研究における最も典型的な問題といえます。
一般化可能性とオーバーフィッティング
過剰適合は「開発データにおいては高精度を示すが、新しいデータでは精度が低下する」現象です。これはまさに「一般化できない」状態です。
予測モデル研究における外的妥当性の検証は、過剰適合を見抜くうえで不可欠です。
もし独立した検証データで性能が著しく落ちるなら、そのモデルは一般化可能性を持たないと判断できます。
逆に、外部データでも安定した予測性能を維持できるなら、そのモデルは高い一般化可能性を有することになります。
したがって、一般化可能性の議論は単なる理論的な話ではなく、オーバーフィッティングの問題と実務的に直結しています。
一般化可能性を高める工夫
研究の設計段階から一般化可能性を意識することが重要です。具体的な工夫としては、
- 多施設共同研究でモデルを開発する(特定施設のバイアスを避ける)
- 対象者の選定を広くする(年齢層や背景を限定しすぎない)
- 外部検証を前提とした研究計画を立てる
- シンプルなモデルを選択する(複雑すぎるモデルは過剰適合しやすい)
これらの取り組みによって、研究結果の一般化可能性を高めることができます。

まとめ
予測研究においては、単に多変量解析でモデルを構築するだけでは十分ではありません。
そのモデルが「正しく作られているか」「新しい集団でも使えるか」を検証することが不可欠です。
そのために重要なのが、内的妥当性と外的妥当性という二つの視点です。
- 内的妥当性:開発集団で正しく機能しているか
- 外的妥当性:別集団や環境でも使えるか
- 信頼性:繰り返し評価しても結果が安定しているか
- 一般化可能性:研究成果が現実の臨床や他の場面でも再現できるか
- 過剰適合:これらを損なう最大のリスク要因
これらの視点をバランスよく取り入れることが、予測研究の成功を左右します。
臨床や実務で「本当に役立つモデル」を作るためには、内的妥当性と外的妥当性を両輪として検証し、過剰適合を避けつつ一般化可能性を高めていきましょう。
こちらの内容はYoutubeでも解説しております。
よろしければこちらの動画をご覧くださいませ。








コメント