臨床研究や疫学調査において、最も困難かつ重要な課題は「因果関係の証明」です。
「薬Aを投与した群の方が生存率が高かった」というデータがあったとしても、それが本当に薬の効果なのか、あるいは対象患者の年齢や重症度が異なっていただけなのか(交絡)を見極める必要があります。
従来、こうした背景因子の調整には、「測定した変数をすべて多変量解析モデル(ロジスティック回帰やCox比例ハザードモデルなど)に投入する」というアプローチが取られがちでした。しかし、近年の因果推論の枠組みにおいて、この方法は偏り(バイアス)を生む危険性が指摘されています。
そこで不可欠となるツールが、DAG(Directed Acyclic Graph:有向非巡回グラフ)です。
この記事では、医療統計におけるDAGの理論的背景から、交絡因子・中間因子・合流点の見分け方、そして具体的な共変量の調整手順までを、徹底解説します。

医療統計におけるDAGの役割とは?
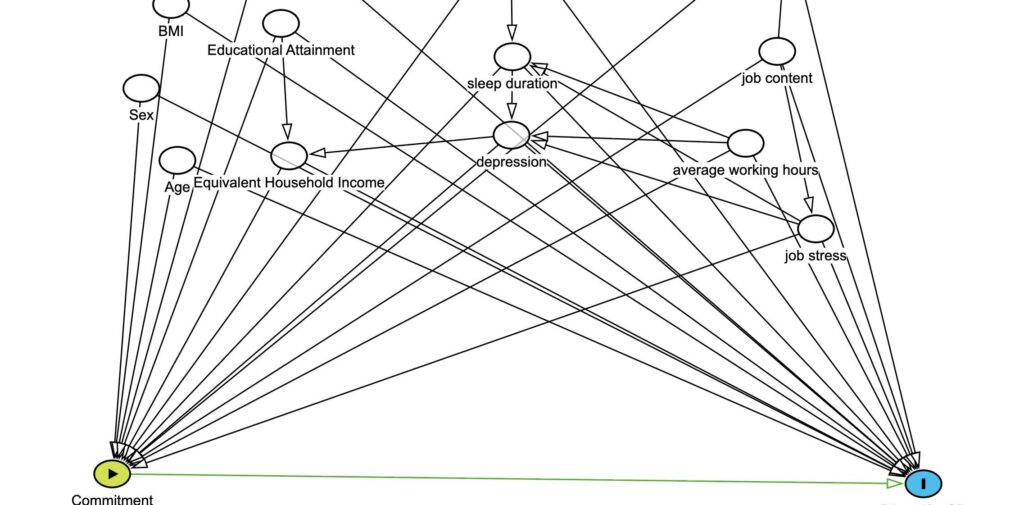
DAGは、単なる「変数間の関係図」ではありません。
それは、研究者が持っている「因果関係に関する仮説(ドメイン知識)」を数学的に記述する言語であり、解析モデルを設計するための設計図です。
観察研究における「因果の壁」
ランダム化比較試験(RCT)であれば、対象者の背景因子はランダムに割り付けられるため、交絡因子の影響を最小限に抑えることができます。しかし、倫理的・費用的な制約からRCTが実施できないケースは多く、観察研究(コホート研究や症例対照研究)に頼らざるを得ない場面が多々あります。
観察研究で因果効果を推定するためには、「比較可能性(Exchangeability)」を担保するために適切な統計学的調整が必要です。ここで、「何を調整すべきか」を誤ると、真実とは逆の結果が導き出されてしまうことさえあります。
DAGは、この「調整の選択」を論理的に行うための羅針盤となります。
DAGを構成する基本要素
DAGは、以下の要素で構成されます。
- ノード(Nodes/Vertices): 変数。曝露(X)、アウトカム(Y)、その他の共変量(Z, C, Mなど)。
- エッジ(Edges): 変数を結ぶ矢印。X → Yは、「Xが変化すれば Yも変化する可能性がある」という因果の流れを示します。
- パス(Path): 変数をつなぐ経路。矢印の向きに関わらず、隣り合う変数を辿るルートのことです。
「非巡回(Acyclic)」という名前の通り、矢印を辿って元の場所に戻るループ構造は許されません。これは「原因は結果よりも時間的に先行する」という因果の原則に基づいています。
3つの基本構造:交絡・媒介・合流点
DAGを理解する上で最も重要なのは、3つの変数が織りなす「3つの基本パターン」を識別することです。これらを区別せずに解析モデルに投入することは、重大なバイアスにつながります。
交絡因子(Confounder):共通の原因
最も一般的で、調整が必要なパターンです。
変数 Zが、曝露 Xとアウトカム Yの両方の原因になっている状態を指します。これを「フォーク(分岐)構造」とも呼びます。
- 構造: X ← Z → Y
- 例:
- X:運動習慣
- Y:心筋梗塞のリスク
- Z:年齢(高齢だと運動しにくく、かつ心筋梗塞リスクも高い)
この場合、Xと Yの間には因果関係がなくても、Zを通じて相関関係が生じます(見かけ上の関連)。
【対応】:Zを調整する必要があります。調整することでX ← Z → Yというバックドア(裏口)パスが遮断され、純粋な X → Yの効果を推定できます。
中間因子(Mediator):因果の通り道
変数 Mが、Xから Yへの因果の連鎖の途中にある状態です。これを「チェーン(連鎖)構造」と呼びます。
- 構造: X → M → Y
- 例:
- X:減塩指導
- M:血圧の低下
- Y:脳卒中の発症の有無
研究の目的が「減塩指導(X)そのものの総合的な効果」を知ることである場合、Mを調整してはいけません。なぜなら、Mを一定に固定(調整)してしまうと、血圧低下による脳卒中予防効果という「治療のメインルート」を遮断してしまうからです。
【対応】:トータルな効果を見たい場合、調整してはいけません。
合流点(Collider):共通の結果
最も直感に反し、かつ誤りやすいパターンです。
変数 Cが、Xと Yの両方から影響を受けている(結果である)状態です。
- 構造: X → C ← Y
- 例:
- X:インフルエンザ感染
- Y:骨折
- C:入院(インフルエンザでも入院するし、骨折でも入院する)
通常、インフルエンザと骨折には因果関係はありません。しかし、ここで「入院患者(C)」だけにデータを限定して解析(層別化・調整)するとどうなるでしょうか?
「入院しているが、インフルエンザではない」患者は、高い確率で「骨折している」ことになります。つまり、本来無関係なはずの Xと Yの間に、人工的な負の相関が生まれてしまうのです。
【対応】:合流点は絶対に調整してはいけません。これを調整することで生じる歪みを「合流点バイアス(Collider bias)」あるいは「選択バイアス」と呼びます。

「バックドア基準」による共変量の選択手順
では、実際の複雑なDAGにおいて、どの変数を調整すべきかをどう判断すればよいのでしょうか。そのための明確なルールが、Pearlらが提唱した「バックドア基準(Back-door Criterion)」です。
3-1. バックドア・パスとは
Xから Yへの因果効果を推定したいとき、Xから出ていく矢印(X → ・・・ → Y)は「因果パス」であり、これは知りたい効果そのものです。
一方、Xに入ってくる矢印から始まるパス(X ← ・・・ → Y)は、因果関係ではない相関を生み出す邪魔な経路です。これを「バックドア・パス」と呼びます。
3-2. 共変量選択のアルゴリズム
正しい因果効果を得るためには、以下の条件を満たす共変量のセット Zを見つけ出し、調整する必要があります。
- 因果の道を邪魔しない:Zの中に、Xから Yへの因果パス上にある変数(中間因子)が含まれていてはならない。
- 裏口を塞ぐ:Zで調整することで、XとYを結ぶすべてのバックドア・パスが「ブロック(遮断)」されること。
【パスがブロックされる条件】
あるパスは、以下のいずれかの場合に「ブロック」されているとみなされます。
- パス上の「交絡因子(A ← Z → B)」または「中間因子(A → M → B)」が調整されている場合。
- パス上の「合流点(A → C ← B)」が調整されていない場合。(※合流点は、何もしなければ最初から道を塞いでいますが、調整すると道が開通してしまう性質があります)
ケーススタディ:実際の臨床研究シナリオ
具体的なシナリオを用いて、DAGを使った変数選択のプロセスをシミュレーションしてみましょう。
【研究テーマ】
新規糖尿病薬(X)の使用が、腎機能障害の進行(Y)を抑制するかどうかを、電子カルテデータを用いて検証したい。
【検討すべき変数】
- 年齢(Age): 高齢者は糖尿病薬が処方されやすく(適応による)、かつ腎機能も低下しやすい。
- 構造:X ← Age → Y
- 判定:交絡因子。バックドアを開いているため、調整が必要。
- HbA1c値(血糖コントロール): 薬(X)によってHbA1cが改善し、その結果として腎機能(Y)が守られる。
- 構造:X → HbA1c → Y
- 判定:中間因子。これを調整すると薬の効果が見えなくなるため、調整してはいけません。
- 社会経済的地位(SES): 裕福な人は新薬(X)にアクセスしやすく、かつ栄養状態が良いため腎機能(Y)も保たれやすい。
- 構造:X ← SES → Y
- 判定:交絡因子。調整が必要。
- 過去の腎機能値(Baseline Kidney Function): 過去に腎機能が悪いと、腎保護作用のある新薬(X)が処方されやすく、当然現在の腎機能(Y)にも影響する。
- 構造:X ← Baseline → Y
- 判定:交絡因子。調整が必要。
- 調査期間中の入院(Hospitalization): 薬の副作用で入院することもあり(X → H)、腎機能悪化でも入院する(Y → H)。入院患者だけのデータセットで解析しようとしている。
- 構造:X → Hospitalization ← Y
- 判定:合流点。入院患者に限定(調整)するとバイアスが生じるため、可能な限り調整・限定すべきではない(あるいは解析時に感度分析が必要)。
【結論:モデルに投入すべき変数】
年齢、SES、過去の腎機能値。
(HbA1cと入院の有無はモデルから除外する)
このように、DAGを描くことで「HbA1cは重要だから入れておこう」という安易な判断が、実は過剰調整であったことに気づくことができます。

5. DAG作成の注意点と限界
DAGは強力なツールですが、魔法の杖ではありません。運用上の注意点も理解しておく必要があります。
5-1. ドメイン知識への依存
DAGはデータから自動的に生成されるものではありません(因果探索という分野もありますが、基本的には人間が描くものです)。
つまり、「矢印をどう引くか」は、研究者の医学的・生物学的な知識に完全に依存します。未知の交絡因子を見落としていたり、矢印の向きが逆だったりすれば、DAGに基づいた調整も誤ったものになります。
そのため、DAGの作成は統計家だけでなく、臨床医や基礎研究者を含めたチームでのディスカッションが不可欠です。
5-2. 未測定交絡因子の存在
DAGを描いた結果、「この Uという変数を調整しなければならない」と分かったとします。しかし、そのデータがカルテに残っていなければ、統計的な調整は不可能です。
DAGは「調整できないバイアスが残っていること」を自覚させてくれるツールでもあります。この場合、論文のLimitation(限界)セクションに「未測定の交絡因子Uの影響により、結果が過大評価されている可能性がある」と正直に記述することが誠実な態度です。
6. まとめ:統計モデルの前に、まずDAGを描こう
医療統計におけるDAG(有向非巡回グラフ)の活用について解説しました。
- 因果の地図: DAGは、変数間の因果関係を可視化し、バイアスの構造を明らかにするための設計図である。
- 3つの基本形:
- 交絡因子(フォーク): 共通の原因。調整する。
- 中間因子(チェーン): 因果の経路。調整しない(トータル効果を見たい場合)。
- 合流点(コライダー): 共通の結果。調整しない(バイアスを生むため)。
- バックドア基準: どの変数を調整すべきかを論理的に決定するルール。
「多変量解析を行えば、すべての背景因子が調整される」という考えは、現代の因果推論においては過去のものとなりつつあります。
p値を計算するプログラムを回す前に、まずは紙とペン、あるいは「DAGitty」のようなツールを使ってDAGを描いてみてください。そうすることで、あなたの研究結果はより堅牢で、科学的に信頼性の高いものになるはずです。









コメント