
この記事では、EZRで多重比較検定を実施する方法をお伝えします。
実際の操作方法に加え、結果の解釈などもお伝えしていきますね。
具体的には、最も有名と思われる4つを紹介します。

多重比較検定とは?

そもそも、多重比較検定とはどういった場合の検定なのでしょうか?
いろんな状況はありますが、主には、群が3つ以上ある場合に2群比較を何度も実施する検定、のことを指しています。
群が3群以上ある場合の検定で有名なものってすぐ出てきますか??
そうですね、分散分析(ANOVA)です。
アウトカムが連続量(量的データ)の場合、群が3群以上であれば分散分析をしよう、とイメージする方も多いのかなと。
しかし分散分析には一つ、使いにくい点があります。
それは、分散分析で有意になったとしても「どこかの群に差がある」としか言えない、ということ。
特定のどの群間に差があるかは分散分析で分からないのです。
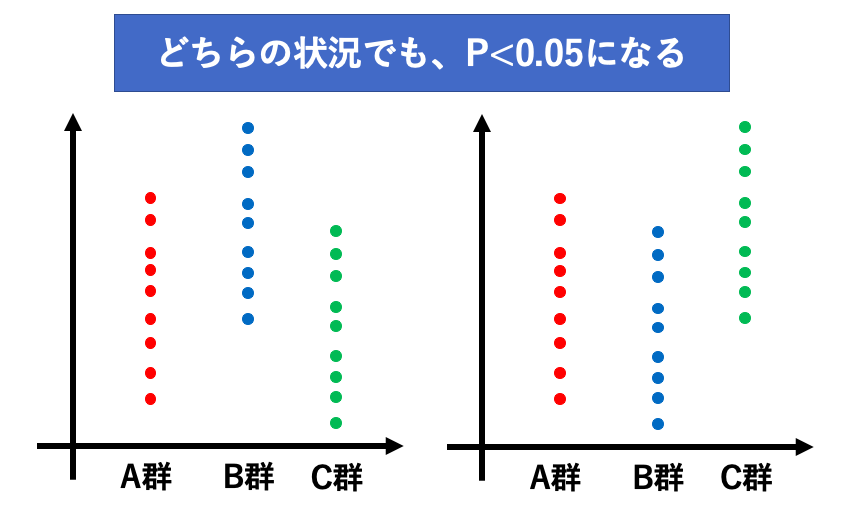
例えば以下の図で、どちらの状況もP<0.05であるとします。
同じ「P<0.05」だったとしても、左の図のようにA群とB群で差があるのかもしれないし、右の図のようにA群とC群で差があるのかもしれない。
分散分析のP値をみても、どの群間で差があるのかが分からないのです。
じゃあ、「どこの群間で差があるの?」に対して答えを出すにはどうすればいいでしょうか?
それは、2群間の比較を何度も実施するしかない、ということになるのです。
どれぐらいの回数を比較すればいいのかというと、3群の場合に2群間の比較の組み合わせは3C2=3通りあるため、最大で3つの検定を実施する必要がある。
4群なら4C2=6通りあるため、最大で6つの検定を実施する必要がある。
このように、2群間の比較(検定)を何度も実施する、ということから、「多重比較検定」と呼ばれています。
また、分散分析の後に実施する検定という印象も多いことから、「事後検定」とも呼ばれています。
多重比較検定を実施することで何が問題になるのか?
では、多重比較検定を実施することで何が問題になるのでしょうか?
それは、多重性の問題が生じる、ということ。
多重性の問題とは、検定を複数(2回以上)実施することで生じる問題です。
多重比較検定も検定を複数(2回以上)実施することになるため、多重性の問題が生じますよね。
でも多重比較検定では、その多重性の問題をすでに考慮した上で検定をしてくれるという優れもの。
多重性を考慮した多重比較検定をすれば、多重性の問題も調整されることになるのです。
多重比較検定って具体的にはどんなのがある?
多重比較検定は具体的にどんなものがあるのでしょうか?
ここでは、最も有名と思われる4つを紹介します。
これら4つの違いは、以下の通り。
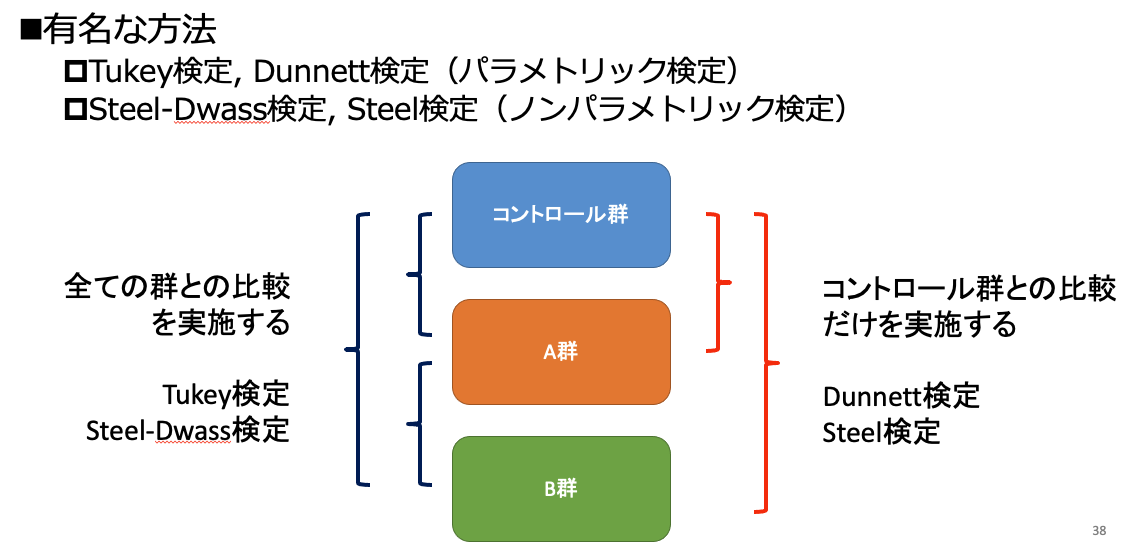
パラメトリックな方法なのが、Tukey検定とDunnett検定。
ノンパラメトリックな方法なのが、Steel-Dwass検定とSteel検定です。
そして、全ての組み合わせの2群比較をするのか、それともコントロール群との比較だけをするのか、という違いがあります。
医薬研究では、特定のコントロール群との比較だけを目的とすることも多いので、上記のような違いが生まれています。
EZRで多重比較検定を実施しよう!

では実際にEZRで多重比較検定を実施していきましょう!
上記で紹介した4つの検定ですね。
これらをやっていきます!
EZRでTukey検定とDunnett検定を実施する方法
ではまず、Tukey検定とDunnett検定を実施していきましょう。
データとしては、自治医科大学さんが提供してくださっているサンプルデータの「LDH.rda」を使っていきます。
ではここから、EZRにデータを取り込みます。
まずは、サンプルデータを適切な場所に保存しておきましょう。
EZRを開き、「ファイル」→「既存のデータセットを読み込む」を選択します。
そしてLDH.rdaをダウンロードしたフォルダに移動し、データを開きます。
データセットが「LDH」になっていることを確認し、「表示」を押してデータが正しく表示されれば取り込み完了です。
解析するための準備が整いましたので、早速Tukey検定とDunnett検定を実施していきましょう。
Tukey検定とDunnett検定を実施するには、以下の手順で行います。
「統計解析」→「連続変数の解析」→「3群以上の平均値の比較(一元配置分散分析one-way ANOVA)」
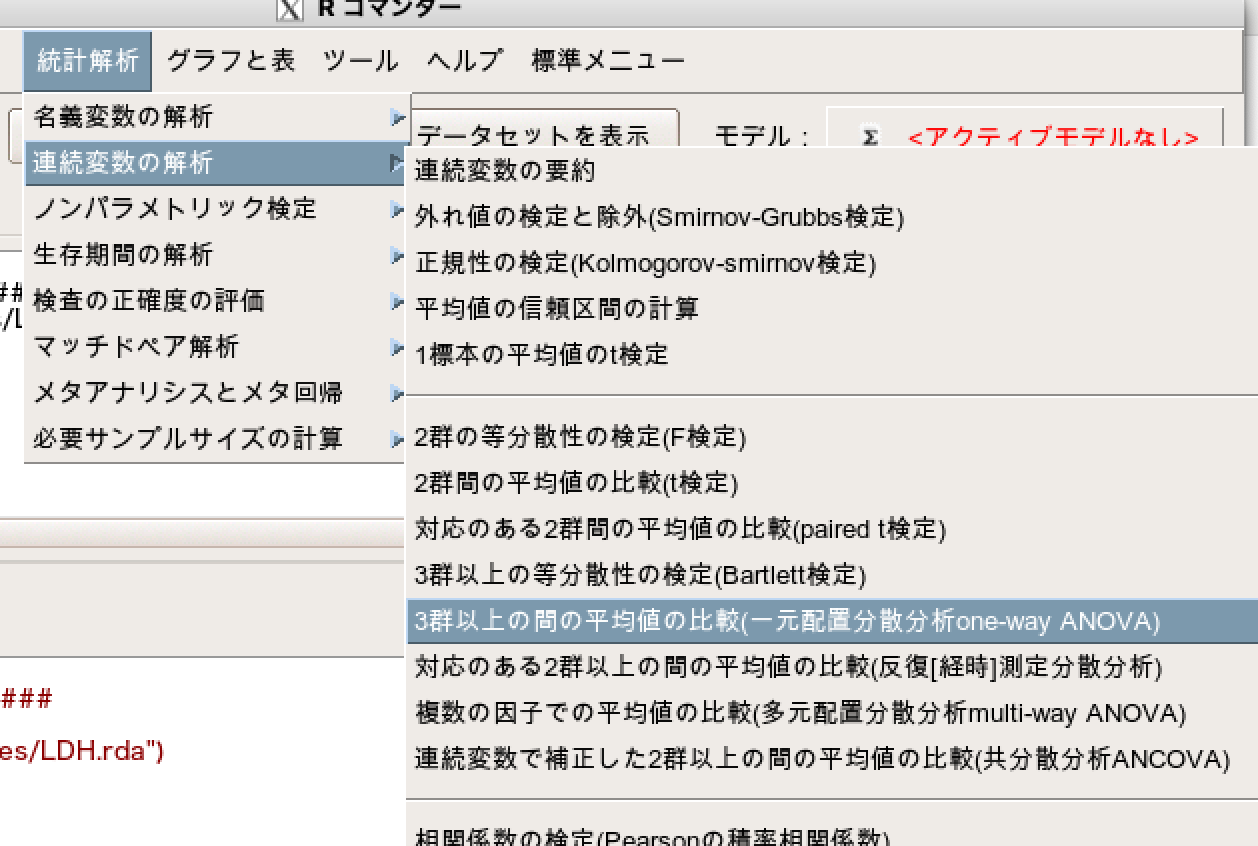
- 目的変数(1つ選択)で「LDH」を選択します。
- 比較する群(1つ以上選択)で「Group」を選択します。
- 等分散と考えますか?については「はい(一元配置分散分析)」を選択します。
- 2群ずつの比較(Tukeyの多重比較)にチェックをする。
- 2群ずつの比較(Dunnettの多重比較)にチェックをする。
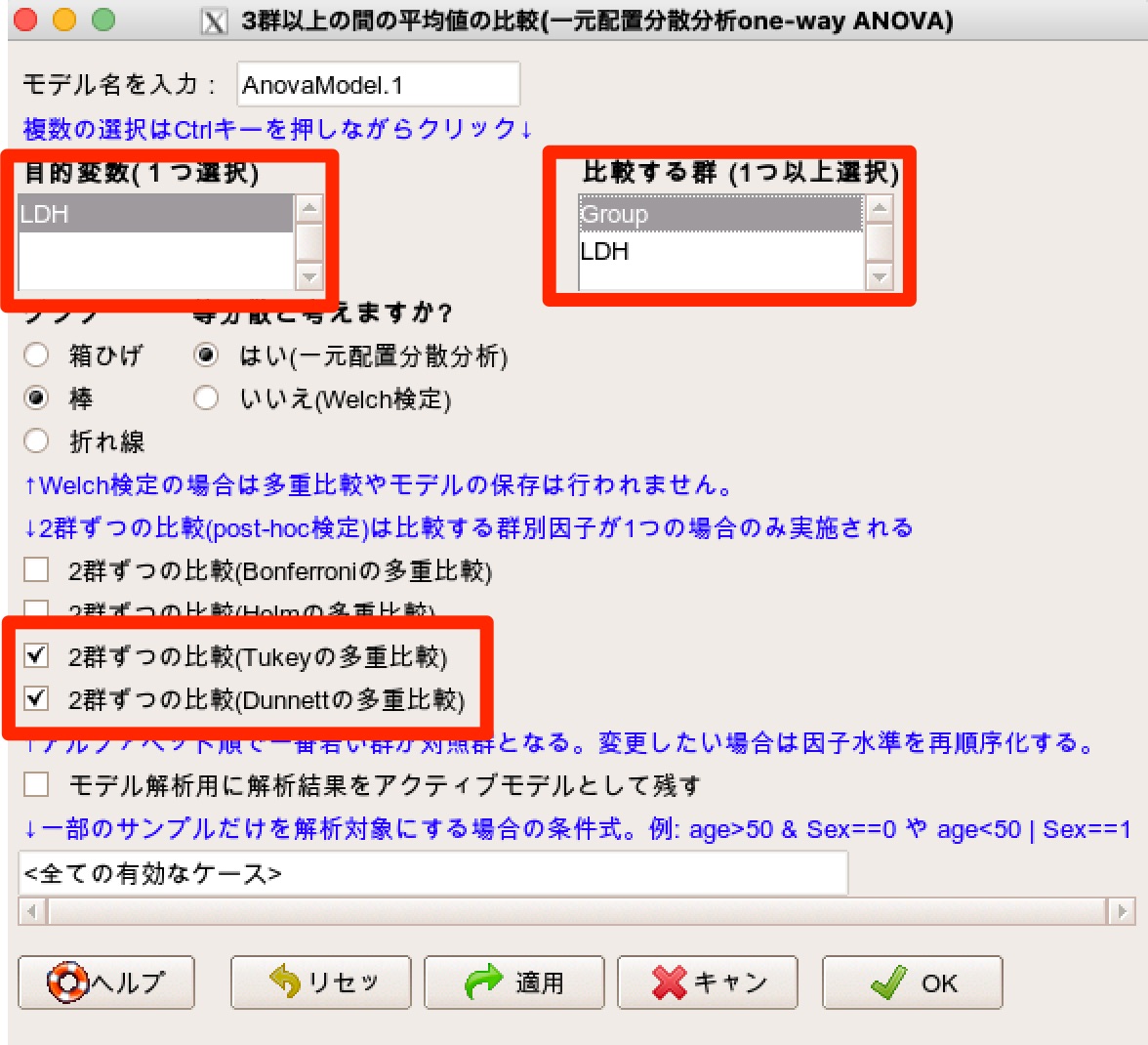
これでOKです。
すると、Tukey検定とDunnett検定の結果が出てきます。
以下がTukey検定の結果。

以下がDunnett検定の結果です。
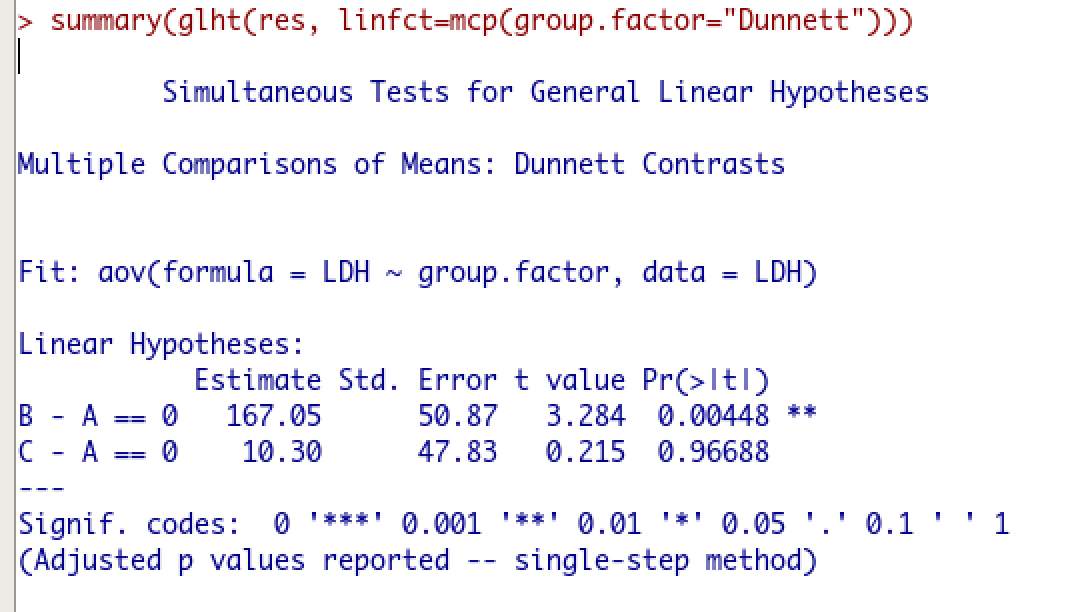
Tukey検定はパラメトリックな全ペアでの比較でしたので、検定結果が3つ出力されていますね。
そしてDunnett検定はパラメトリックなコントロール群との比較でしたので、検定結果が2つ出力されています。
コントロール群は群情報のローマ字が一番早いものがコントロール群として自動的に認識されますので、今回の場合はA群がコントロール群になります。
EZRでSteel-Dwass検定とSteel検定を実施する方法
では次に、Steel-Dwass検定とSteel検定を実施していきましょう。
データは先ほどと同じく、LDH.rdaを使っていきます。
Steel-Dwass検定とSteel検定を実施するには、以下の手順で行います。
「統計解析」→「ノンパラメトリック検定」→「3群以上の間の比較(Kruskal-Wallis検定)」
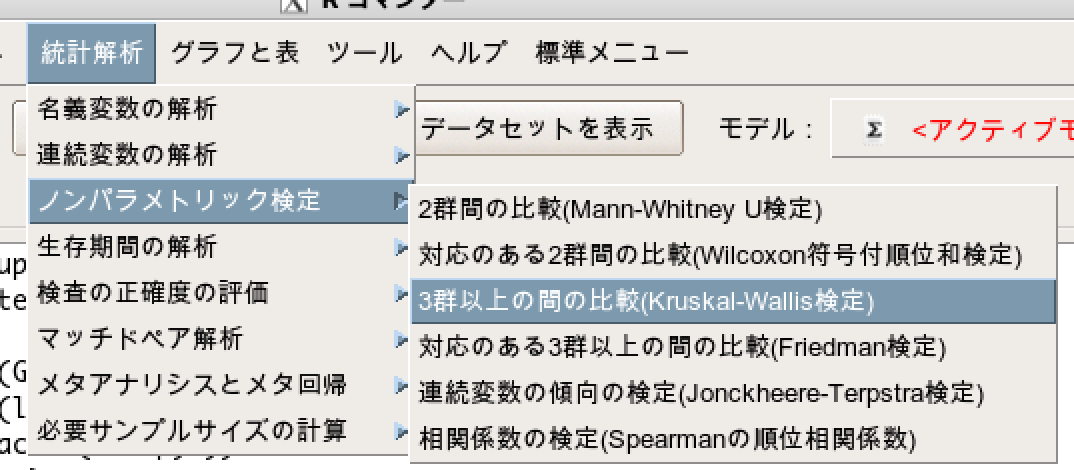
- 目的変数(1つ選択)で「LDH」を選択します。
- グループ(1つ選択)で「Group」を選択します。
- 2群ずつの比較(Steel-Dwassの多重比較)にチェックをする。
- 2群ずつの比較(Steelの多重比較)にチェックをする。

これでOKです。
すると、Steel-Dwass検定とSteel検定の結果が出てきます。
以下がSteel-Dwass検定の結果。
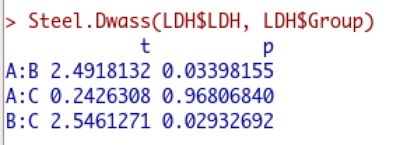
以下がSteel検定の結果。

Steel-Dwass検定はノンパラメトリックな全ペアでの比較でしたので、検定結果が3つ出力されていますね。
そしてSteel検定はノンパラメトリックなコントロール群との比較でしたので、検定結果が2つ出力されています。
コントロール群は群情報のローマ字が一番早いものがコントロール群として自動的に認識されますので、今回の場合はA群がコントロール群になります。

EZRで多重比較を実践した結果を考察する

EZRで多重比較検定を実施できました。
各検定の結果の違いを考えてみましょう。
例えば、Steel-Dwass検定とSteel検定の違いに着目してみます。
以下がSteel-Dwass検定の結果。
以下がSteel検定の結果。
同じA vs Bでも、P値が異なることがわかりますか?
Steel-Dwass検定だと0.0339ですが、Steel検定だと0.0241です。
これは「検定の数」が関わっています。
多重性を考慮した検定の場合、検定の数がP値に影響を及ぼします。
全てのペアの多重比較はP値が大きくなる傾向。(有意になりにくい)
一方で、コントロールとの比較だと検定の数が少ないのでP値が小さくなるんです。
これはTukey検定とDunnett検定との違いも同じ。
そのため、研究目的を考えながら、どの検定を使うのかを判断することが重要になります。
コントロール群との比較だけでいいのにTukey検定やSteel-Dwass検定を実施してしまうと、P値が大きくなる方向になるため、有意になりにくいです。
まとめ

いかがでしたか?
この記事では、EZRで多重比較検定を実施する方法をお伝えしました。
を状況に応じて使い分けられるようになれば幸いです!
こちらの内容は動画でもお伝えしておりますので、併せてご確認くださいませ。










コメント