
この記事では「データクリーニングの目的とやり方は?エクセルでもできる、これだけはやるべき7つのこと」ということでお伝えします。
データクリーニングは解析をする上で必要不可欠なプロセス。
データを解析できる状態にしておかないと、せっかく苦労して取得したデータも水の泡ですから。
この記事ではデータクリーニングの具体的なやり方として7つ紹介しますので、ぜひ意識してみましょう!

データクリーニングとは?どんな目的で実施するの?

データクリーニングはなぜ実施するのでしょうか?
その答えは一つだけで「データを解析できる状態にする」ということ。
せっかく苦労してデータを取得しても解析できなければ意味がないですよね。
取得したデータを何も考えずにエクセルに貼り付けただけでは、統計解析できない場合も多い。
なぜなら、統計解析ソフトで解析するためにはデータの型(フォーマット)があるから。
そのため、取得したデータを統計解析ソフトで解析できるようにするために必要なのがデータクリーニングです。
データクリーニングは自分で解析を実施する時以外にも、解析を外注する場合にも必要。
なぜなら、このデータクリーニングは研究者自身しかできない部分も多いからです。
そのため、解析できる状態のデータじゃなければ受けてもらえないことも多いですし、受けてもらえたとしても、データクリーニングの費用が別途かかってしまって多額の解析費用になってしまうこともあります。
データクリーニングとデータクレンジングの違いは?
研究のジャンルによっては、「データクリーニング」ではなく「データクレンジング」という言葉を用いられていることもあります。
私のイメージとしては、データクレンジングはIT系のデータ解析で使われているイメージ。
しかし使われている用語が異なるだけで、「データを解析できる状態にする」という本質には違いはないです。
データクリーニングのやり方:エクセルでもできる、これだけはやるべき7つのこと

データクリーニングの目的がわかったところで、実際にデータクリーニングとして何をやれば良いのか?を整理していきましょう!
ここで紹介するデータクリーニングは
- エクセルでデータを管理していることを想定
- 統計解析ソフトはEZR、JMP、SPSSなど、クリックで解析するようなソフトを想定
上記の2つを想定しています。
データクリーニングのやり方1:2バイト文字(日本語)は使わない
プログラミングは基本的には英語(ローマ字)の環境で作られているため、日本語は特殊な文字に該当します。
多くの統計解析ソフトも、見た目は日本語で書かれていることも多いですが、実際には英語環境で動いていることも多いですね。
そのため、できるだけ日本語は使わないようにしましょう。
ファイル名、列名なども全てローマ字表記にすることはもちろんのこと、データを格納しているフォルダ名も日本語だとエラーになる場合があります。
解析環境は常に英語にしておきましょう。
データクリーニングのやり方2:1症例1行のデータにする
クリックして解析するような統計ソフトでは、1症例1行のデータにすることが基本です。
具体的には、1行目は変数の名前で、2行目からデータにすること。(以下のような感じです)

新規にデータを取得した場合でも、どんどん横に追加していきます。
データを取得する種類によっては、500列もあるようなデータになってしまったりしますが、それでOKです。
ただし、クリックで解析するのではなく、SASやRなどのプログラミング言語を使う場合はまた別の作り方が必要になりますのでご注意ください。
データクリーニングのやり方3:外れ値(医学的にとりえない値)がないかを確認する
データクリーニング段階で、外れ値(医学的にとりえない値)がないかを確認しましょう。
外れ値に対する統計学的な検定手法もありますが、医療統計に限っていえば、統計検定で外れ値を判定することはしなくていいです。
あくまで医学的にとりえない値がないか、そして信頼性に乏しいデータがないか(溶血など)、という視点での外れ値です。
>>外れ値とは何か?
データクリーニングのやり方4:エクセルのシートを複数にしない(1つのシートにする)
エクセルでデータを管理すると、整理のためにシートを複数に分けてデータを管理している状況があるかもしれません。
例えば、群ごとにシートを分ける、血液検査の種類ごとにシートを分けるなど。
確かに見やすいかもしれないですが、解析する上ではデメリットに。
基本的には全て1つのシートにする必要があります。
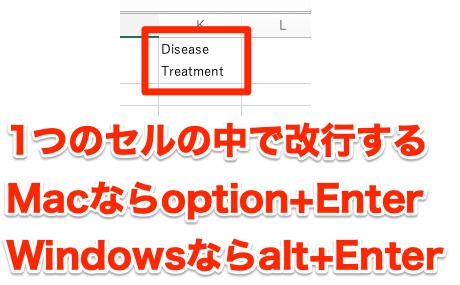
データクリーニングのやり方5:セル内改行しない
エクセルではセル内改行できることはすごく便利な時があります。
ですが、解析するデータに対してセル内改行してはいけないです。
セル内改行とは、一つのセルの中で改行すること。
下記のようなデータだと、エラーを起こすか、上の「Disease」だけが認識されて取り込まれたりします。
データクリーニングのやり方6:連続量の中に文字を入れない
連続量(量的データ)として扱いたい変数があったとして、その変数の中に文字を入れることがないようにしましょう。
例えば、以下のように、18歳未満を「<18」として入力する例が考えられます。
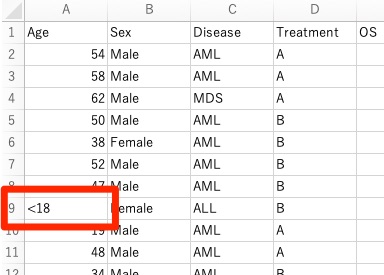
こういったデータがあることで困ることは、連続変数の中に一つでも文字が入っていると、統計解析ソフトでは全てを文字として扱ってしまう点。
つまり、54という数字ではなく、「54」という文字で認識する、ということに。
それでは実施したい解析ができません。
この場合、18歳未満のデータを事前にどう扱うのかを決めておく必要があります。
どういった扱いが正解であり、不正解であるか、というのは研究目的によって異なりますので、個々の研究で決めていきましょう。
データクリーニングのやり方7:同じことを意味するなら大文字小文字も全て同じにする
そしてカテゴリカル変数(質的データ)に対しても、注意点があります。
それは「同じことを意味するなら大文字小文字も全て同じにする」ということ。
例えば以下のように、男性を示す値が「Male」と「male」という頭文字が大文字か小文字化で異なる値だと認識されます。
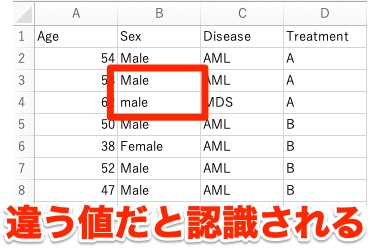
そのため、同じことを意味するなら大文字小文字も全て同じにする、というルールは徹底していきましょう。

まとめ

いかがでしたか?
データクリーニングのやり方を具体的に7つ紹介しました。
- 2バイト文字(日本語)は使わない
- 1症例1行のデータにする
- 外れ値(医学的にとりえない値)がないかを確認する
- エクセルのシートを複数にしない(1つのシートにする)
- セル内改行しない
- 連続量の中に文字を入れない
- 同じことを意味するなら大文字小文字も全て同じにする
ぜひどの研究でも意識しましょう!
こちらの記事の内容は動画でもお伝えしていますので、併せてご確認くださいませ。








コメント