
生存時間解析結果を可視化する方法が、カプランマイヤー曲線ですね。
そして、生存時間解析での検定手法の一つが、ログランク検定です。
この記事では、生存時間解析で絶対に不可欠なログランク検定のEZRでの実施方法とカプランマイヤー曲線をEZRで作成する方法について。
EZRにインポートするデータの構造に関しても詳しく解説します。

EZRでカプランマイヤー曲線(生存曲線)を作成するために必要となるデータ
EZRでカプランマイヤー曲線を描くためには、最低でも3種類のデータが必要です。
具体的には、下記の3種類。
- 生存時間のデータ
- イベントか打ち切りかのデータ
- 群のデータ
今回の記事では、自治医科大学さんが提供してくださっているサンプルデータの中から「Survival.csv」を使用して解説いたします。
EZRでカプランマイヤー曲線作成に必要なデータその1:生存時間のデータ
生存時間解析なので、当然、生存時間のデータが必要です。
今回使用するデータでいうと、DaysToOS列です。
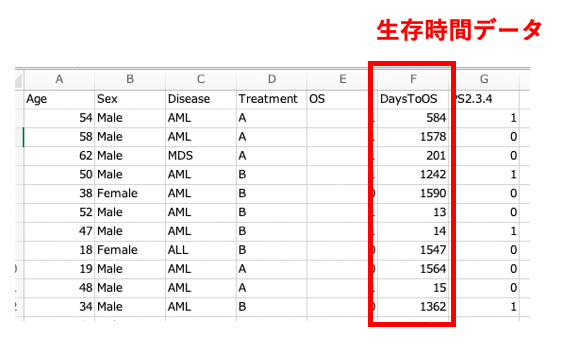
今回の例では、Day(日)のデータですが、これがMonth(月)でもYear(年)でも大丈夫です。
しかし一つ注意したいのが、取れるならできる限り細かいデータを取っておくといい、ということ。
年のデータよりも、月ごとのデータ。
月のデータよりも、日ごとのデータ。
というのも、例えば生存時間のデータが年単位でしか取得していない場合。
2019年1月1日に起きたイベントも、2019年12月31日に起きたイベントも、同じ「2019年」というデータになります。
しかし日単位で取得していれば、1月1日と12月31日の違いも考慮できますので、より正確な解析結果を得ることができます。
EZRでカプランマイヤー曲線作成に必要なデータその2:イベントか打ち切りかのデータ
生存時間解析とは、「打ち切りを考慮しながらイベントまでの時間を解析できる方法」でした。
そのため、「打ち切り」なのか「イベント」なのかの違いをちゃんとデータとして持っておく必要があります。
「イベント」とは、「追跡期間中に1度だけ起こる目的となる事象」です。
「打ち切り」は、「イベントが起こっていないこと」です。
詳しくは、生存時間解析の基礎の解説を参照くださいね。
下記のデータであれば、「OS」列がイベントか打ち切りかを区別するデータです。
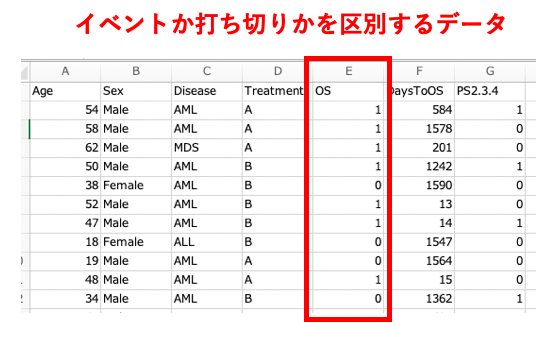
EZRに取り込むデータとしては、イベントと打ち切りのデータ形式が決まっています。
- イベントは数字の1であらわす
- 打ち切りは数字の0であらわす
これは、EZRで解析するなら絶対に守らなければならないものです。
“1”か“0”のデータ以外のデータを用意したとしても、EZRではイベントか打ち切りかを区別するデータとして使うことができませんのでご注意くださいね。
(JMPで生存時間解析を実施する場合だと1と0以外でも認識してくれますので、統計解析ソフトによってデータの作り方の正解は変わります。)
EZRでカプランマイヤー曲線作成に必要なデータその3:群のデータ
生存時間解析をする、ということは、「生存時間を比較する」ということですよね。
ということは、群のデータが必要になります。
下記のデータでは、Treatment列が群のデータになります。
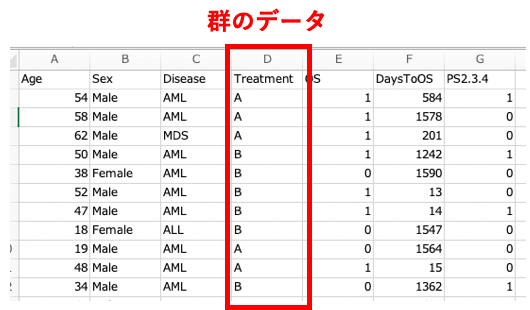
EZRに取り込む群のデータは、特に形式はありません。
上記の例では“A”か”B”かのデータ形式になっています。
例えばこれが“X”か”Y”であってもOKですし、“Treatment 1”か”Treatment 2”であってもOKです。
カプランマイヤー曲線作成でEZRに取り込むデータに関する注意点
その他、EZRに取り込むデータに関する注意点です。
- 一番上の行は列名として認識されますので、列名を記載しておきましょう。
- 列名は、アルファベットを使いましょう。(日本語だとたまにエラーになります)
- データ形式は、CSVにしておきましょう。
これさえできていれば、エラーもなくデータを取り込むことができます。
CSVにする理由は、この記事と同じように操作できるからです!笑
もしデータの取り込みを自分でちゃんとできるよ、という方はExcel形式でもOKです。
EZRでカプランマイヤー曲線(生存曲線)を作成する!

ではここから、EZRの操作方法を解説します。
まずは、データを取り込むところから。
まずは、サンプルデータを適切な場所に保存しておきましょう。
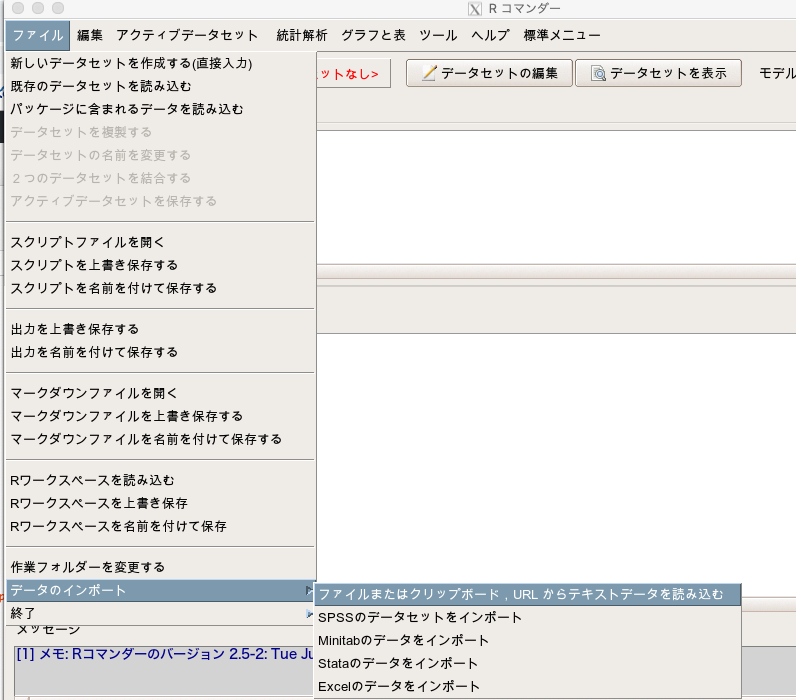
保存したあとにEZRを開き、「ファイル」→「データのインポート」→「ファイルまたはクリップボード, URLからテキストデータを読み込む」を選択します。
データセット名は「Survival」にしましょう(実際はなんでもよい)。
そして「ローカルファイルシステム」と「カンマ」にチェックを入れてOKを押します。
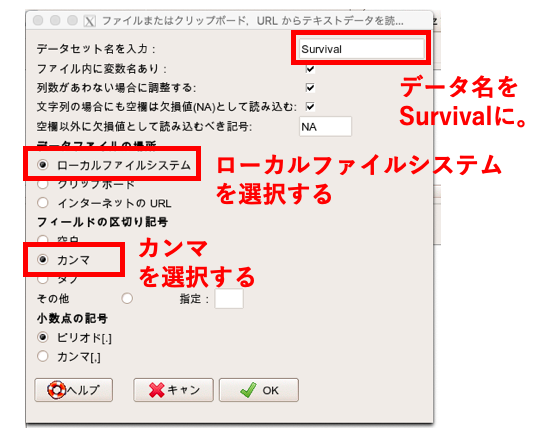
データセットが「Survival」になっていることを確認し、「表示」を押してデータが正しく表示されれば取り込み完了です。
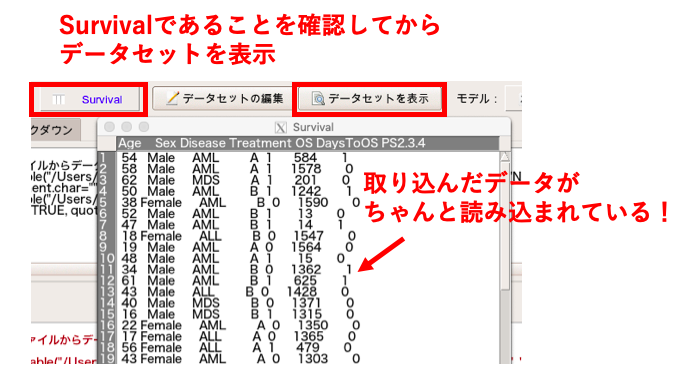
EZRで実際にカプランマイヤー曲線を描く!
データが無事に取り込まれ、解析するための準備が整いましたので、早速カプランマイヤー曲線を描いてみましょう。
実際にはカプランマイヤー曲線を描くだけではなく、カプランマイヤー曲線を含めたログランク検定などの生存時間解析全体を実施します。
今回は、Teatment AとTreatment Bの間でOSに差があるかどうか、を検討します。
操作手順は、「統計解析」→「生存期間の解析」→「生存曲線の記述と群間の比較(Logrank検定)」です。
そして、解析に必要な変数を選択していきます。
- 観察期間の変数は「DaysToOS」を選択。
- イベント、打ち切りの変数は「OS」を選択。
- 群別する変数は「Treatment」を選択します。
- 層別化変数は何も選択しなくてOKです。
そのほかの設定はデフォルト通りでOKですが、念の為下記の画像を確認してください。
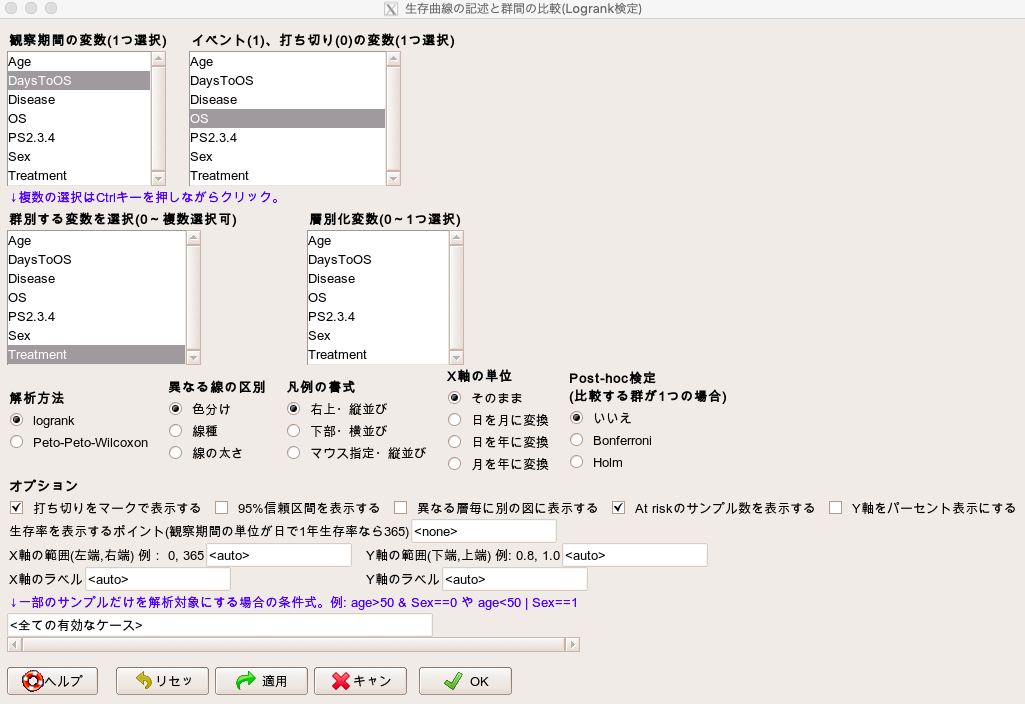
これで解析を実行すると、Logrank検定の結果とカプランマイヤー曲線を出力してくれます。
下記のカプランマイヤー曲線が出力されていれば、成功です!


EZRで実施した生存時間解析結果の解釈をしよう!Number at riskとは?

無事に生存時間解析の結果が出力されましたので、結果の解釈をしましょう。
下のグラフがカプランマイヤー曲線です。(先ほどのグラフを再掲します)
下にいくほどイベントの発生が多い(今回の場合、死亡が多い)ことを表します。
黒い線が「Treatment Aの集団」、赤い線が「Treatment Bの集団」ですので、今回のデータではTreatment Aの方が、死亡する人が多くなっているのが分かります。
ちなみに、カプランマイヤー曲線に時々縦線が入っているのは、「ヒゲ」と呼んでいて、打ち切りを表しています。
そして、下にある「Number at risk」はイベントの発生や打ち切りによって脱落した人を差し引いたサンプル数が示してあります。
要約統計量の解釈:生存期間の中央値と95%信頼区間
そして、基本的な解析結果は、Rコマンダー内の以下の部分を見ます。

要約統計量としては、生存期間の中央値とその95%信頼区間です。
生存時間解析の95%信頼区間の出し方はかなり独特なので説明は割愛しますが、解釈のイメージは、通常の95%信頼区間と同じです。
Treatment Bの上側95%信頼区間がNAとなっていますね。
これはよくあることで、信頼区間を計算するほどイベントが起こっていないためです。
また、P値は0.092ですので、もし0.05が有意水準であれば、有意差はなし、となります。
カプランマイヤー曲線からは、中央値とX年生存率が読み取れるはずです。
今回のカプランマイヤー曲線ではX年生存率が出力されていませんが、EZRで出力できるの?と疑問になりますよね。
出力できます。
EZRのカプランマイヤー曲線でX年生存率を表示する方法
先ほどと同じように、「統計解析」→「生存期間の解析」→「生存曲線の記述と群間の比較(Logrank検定)」を選択します。
そして、選択する変数も先ほどと一緒にします。
「生存率を表示するポイント」というのがあるのですが、ここを今回は1000としましょう。
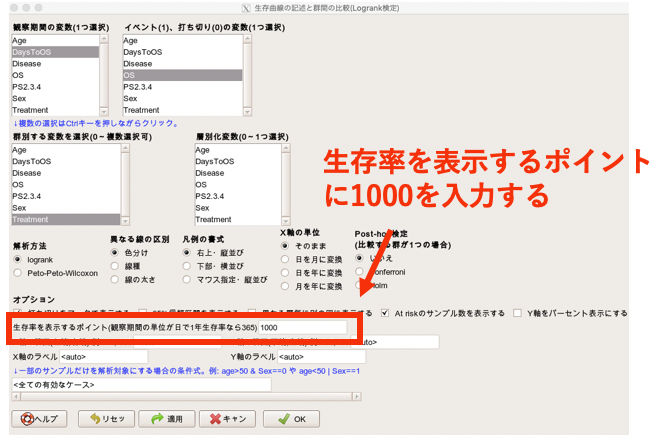
ということで、1000日生存率を確認してみます。
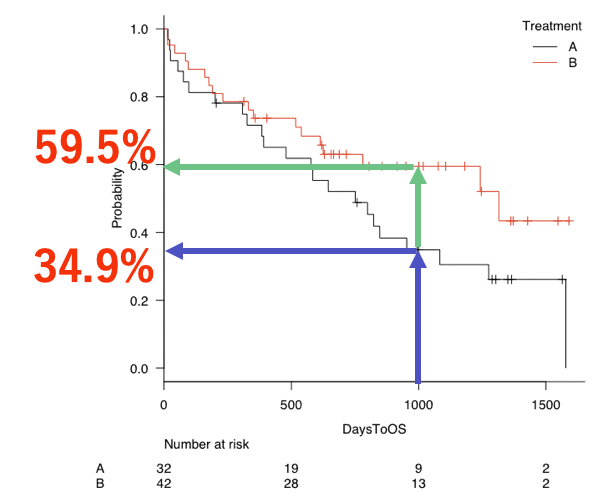
すると、「指定時点の生存率」が出力されています。

1000日時点でのTreatment Aの生存率は34.9%であり、Treatment Bは59.5%ということです。
図式化すると、下記の点が34.9%と59.5%ということですね。

EZRでカプランマイヤー曲線を作成する方法まとめ

今回は、EZRでカプランマイヤー曲線を描きました。
データさえちゃんと用意されていれば、特に難しいことはありませんでしたね。
カプランマイヤー曲線から読み取ることができる、中央値とX年生存率に関しても、ちゃんと出力されました。
こちらの内容は動画でもお伝えしておりますので、併せてご確認くださいませ。










コメント
コメント一覧 (2件)
[…] いぜん、EZRでカプランマイヤー曲線を作成した時のデータと同じです。 […]
[…] >>>EZRでカプランマイヤー曲線!ログランク検定や生存時間解析を実施 […]