
生存時間解析で出てくる代表的な2種類のノンパラメトリック検定が、ログランク検定(Log-rank test)と一般化ウィルコクソン検定(Generalized Wilcoxon test)です。
この記事では、その2つの検定について解説します。
この記事を読めば、以下のことがわかるように!
- ログランク検定の帰無仮説・対立仮説
- ログランク検定でやっていることの概要
- 一般化ウィルコクソン検定の概要
- ログランク検定と一般化ウィルコクソン検定との違い
- ログランク検定と一般化ウィルコクソン検定の、それぞれ得意とする場面
それではいってみましょう!

ログランク検定はどんなデータを対象とした検定か?カプランマイヤーとセットで解析する

まずは、ログランク検定が対象とするデータです。
T検定は連続量を対象とした検定でしたよね。
では、ログランク検定はどうでしょうか?
結論から言うと、ログランク検定は生存時間を対象とした検定です。
| T検定 | カイ二乗検定 | ログランク検定 | |
| 対象データ | 連続量 | カテゴリカルデータ | 生存時間 |
ログランク検定は生存時間解析で用いる検定手法です。
生存時間解析で可視化する方法は、カプランマイヤー曲線でしたね。
カプランマイヤー曲線のP値はログランク検定のP値であることがほとんど
ログランク検定は、カプランマイヤー曲線とセットで出てくることが多いです。
カプランマイヤー曲線にp値が記載されていたら、それはほぼログランク検定のp値であると認識しておいてよいでしょう。
例えば、下記の論文ではMethodに「Kaplan-Meier curves were calculated for time-to-event end points, with differences between arms tested at the overall 5% significance level by log-rank test.」とあり、ログランク検定のp値が記載されていることがわかります。
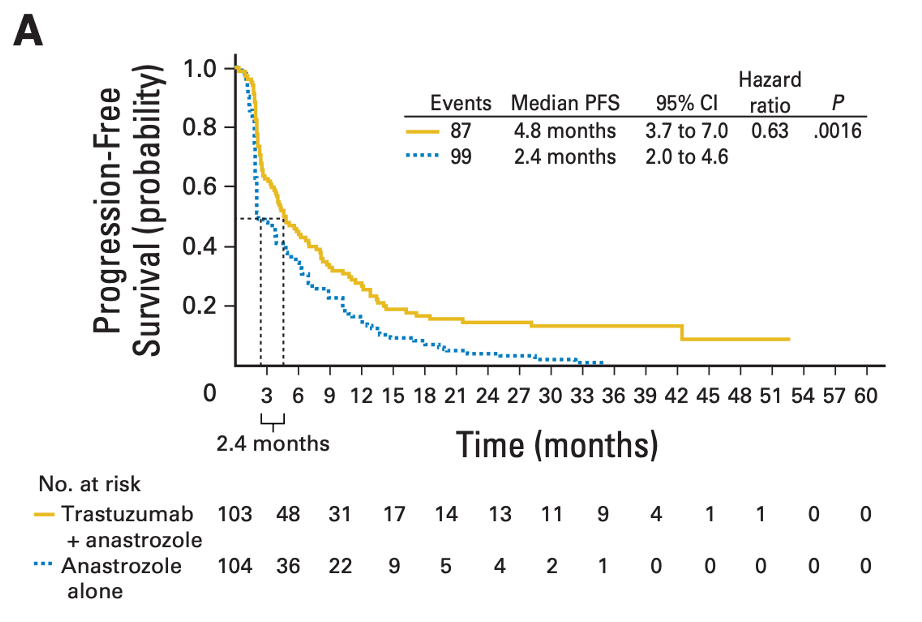
引用:Trastuzumab Plus Anastrozole Versus Anastrozole Alone for the Treatment of Postmenopausal Women With Human Epidermal Growth Factor Receptor 2–Positive, Hormone Receptor–Positive Metastatic Breast Cancer: Results From the Randomized Phase III TAnDEM Study
ログランク検定の帰無仮説と対立仮説は?

ログランク検定は統計的検定の1つであるため、当然ながら帰無仮説と対立仮説があります。
まずはそれを理解しておきましょう。
ログランク検定の帰無仮説と対立仮説はこちらです。(2群の場合)
- 帰無仮説:全ての時点で、2群の生存率は同じ
- 対立仮説:ある任意の時点で、2群の生存率は異なる
つまり、2群の生存率が同じかどうかを検定しているということ。
ログランク検定のP値が、事前に決めておいた有意水準よりも小さければ、生存率が2群で異なるという結論を導くことができます。
この解釈の仕方は、他の検定でも同じですね。

ログランク検定はノンパラメトリック検定

ログランク検定は、ノンパラメトリック検定の1つです。
ということは、検定をする際にデータの分布を仮定しない検定だということですね。
一方、生存時間解析で良く出てくるCox比例ハザードモデルは、セミパラメトリックな方法です。
その名の通り、各時点のハザード比が一定であることを仮定しているためです。
ログランク検定でやっていること
では、実際にログランク検定でやっていることは何だろう?と思いませんか。
それを解説していきます。
ログランク検定でやっていることを一言で表すと、これです。
・・・これだけじゃわからないですよね。
なので、実際に例を見ていきましょう。
例を見ながらログランク検定の概要を知る
例えば、以下のようなデータがあったとします。
今回の例では、死亡がイベントです。
| 群 | 生存または打ち切りの時間(ヶ月) | 死亡(1)なのか打ち切り(0)なのかの違い |
| 実薬群 | 5 | 0 |
| 実薬群 | 7 | 0 |
| 実薬群 | 8 | 1 |
| 実薬群 | 12 | 0 |
| プラセボ群 | 2 | 0 |
| プラセボ群 | 3 | 1 |
| プラセボ群 | 4 | 1 |
| プラセボ群 | 10 | 0 |
このデータで、イベント(死亡)は3回起こっていますよね。
- 実薬群の8ヶ月目
- プラセボ群の3ヶ月目
- プラセボ群の4ヶ月目
この3つです。
この3つの時点で2×2分割表を作成します。
つまり、以下のような分割表が作成できます。
3ヶ月時点の分割表
| 3ヶ月目 | 死亡数 | 生存数 | 合計 |
| 実薬群 | 0 | 4 | 4 |
| プラセボ群 | 1 | 2 | 3 |
| 合計 | 1 | 6 | 7 |
4ヶ月時点の分割表
| 4ヶ月目 | 死亡数 | 生存数 | 合計 |
| 実薬群 | 0 | 4 | 4 |
| プラセボ群 | 1 | 1 | 2 |
| 合計 | 1 | 5 | 6 |
8ヶ月時点の分割表
| 8ヶ月目 | 死亡数 | 生存数 | 合計 |
| 実薬群 | 1 | 1 | 2 |
| プラセボ群 | 0 | 1 | 1 |
| 合計 | 1 | 2 | 3 |
ここで注意していただきたいのが、分割表にある合計の数値は「その時点で追跡できている数」になるということ。
データでは実薬群が4例、プラセボ群も4例の計8例です。
ですが、表中の3ヶ月時点でのデータを見れば分かる通り、プラセボ群の合計が3例で、トータルの例数は7例です。
「あれ?プラセボ群は4例でトータル8例じゃなかった?」
と思いますよね。
なぜプラセボ群の1例がいなくなったかというと、2ヶ月時点で打ち切り症例が1例いるから。
初めてイベントが起こる3ヶ月時点より早い時点(2ヶ月目)で、プラセボ群の1例は追跡不能になったため、イベント発生時の分割表からは除かれているんです。
以上が、ログランク検定でやっていることの概要です。
ログランク検定の検定統計量はカイ二乗統計量の発展
ログランク検定でやっていることは、イベントが発生した時点で2×2分割表を作成することだと理解しました。
であれば、検定統計量はどうなるでしょうか?
分割表を作成すると、算出できる統計量がありますよね。
そう、カイ二乗統計量です。
そのため、ログランク検定でやっていることをまとめると以下の通りになります。

一般化ウィルコクソンについて。ログランク検定との違いは?
一般化ウィルコクソン検定は、ログランク検定と同じ、生存時間を扱う解析手法です。
では、ログランク検定と一般化ウィルコクソン検定では何が違うのでしょうか。
実は、ほとんど違いがありません。
帰無仮説と対立仮説は、ログランク検定と同じで以下の通りです。(2群の場合)
- 帰無仮説:全ての時点で、2群の生存率は同じ
- 対立仮説:ある任意の時点で、2群の生存率は異なる
また、一般化ウィルコクソン検定もログランク検定も同様にノンパラメトリック検定です。
さらに、一般化ウィルコクソン検定でやっていることも「イベントが起こるごとに2×2分割表を作成し、カイ二乗統計量を算出してP値を出力している」ということなので、ログランク検定と同じですね。
唯一の違いがこれです。
一般化ウィルコクソン検定の考え方
一般化ウィルコクソン検定で重要となるたった1つの考え方があります。
それがこちら。
例えば、100例生存していた中から20例死亡すると、「だいたい2割」と自信を持って言えそうですよね。
しかし、5例中1例死亡しても「だいたい2割」と本当に言えるのか?ということが疑問になります。
そのため例数の多く残っている、前の方の時点のデータを重要視するのです。
一方のログランク検定は、どの時点のデータでも平等に扱っています。
よって、ログランク検定と一般化ウィルコクソン検定の違いをまとめると以下の通りです。
ログランク検定と一般化ウィルコクソン検定の使い分け
では次に知りたいことは、そのログランク検定と一般化ウィルコクソン検定の違いによって、どのような使い分けになるのか?ということです。
結論は以下の通り。
- 「時間がたてばたつほど、群間差が開いてくる」タイプのデータに対しては、一般化ウィルコクソン検定よりもログランク検定の方が、有意差がつきやすくなる。
- 一方、「結局ほぼ全員が死亡するのだけど、生存時間が延びる」タイプのデータでは、一般化ウィルコクソン検定の方が、差がつきやすくなる。
イメージとしては、以下の通りです。
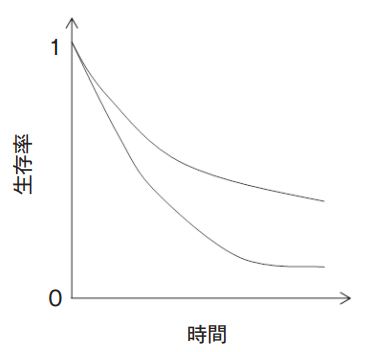
上記のグラフのように、時間がたつほど曲線に差が出るのであれば、ログランク検定で有意差がつきやすいです。
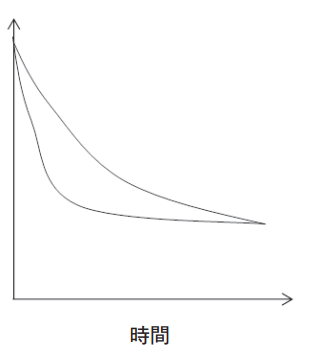
上記のグラフのように、最初は差がつくけど最終的には同じになる場合、一般化ウィルコクソン検定で有意差がつきやすいです。
ただ、多くの論文を見ていると、一般化ウィルコクソン検定を実施している論文はほぼ皆無です。
そのため、ログランク検定を用いていれば問題ありません。
ログランク検定をEZRで実践する
ログランク検定をEZRで実践する方法を、別記事で解説しています。
EZRとは無料の統計ソフトであるRを、SPSSやJMPなどのようにマウス操作だけで解析を行うことができるソフトです。
EZRもRと同様に完全に無料であるため、統計解析を実施する誰もが実践できるソフトになっています。
2019年5月の時点で英文論文での引用回数が2400回を超えているとのことで、論文投稿するための解析ソフトとしても申し分ありません。
これを機に、EZRで統計解析を実施してみてはいかがでしょうか?
ログランク検定に関するまとめ
- ログランク検定とは、生存時間を対象としたノンパラメトリック検定である。
- ログランク検定でやっていることは、イベントが起こるごとに2×2分割表を作成し、カイ二乗統計量を算出してP値を出力する、ということ。
- 一般化ウィルコクソン検定は、ログランク検定と同様に生存時間を解析する手法
- ログランク検定では、どの時点のデータも平等に扱う。一方で一般化ウィルコクソン検定では、例数の多く残っている前の方の時点のデータを重要視して扱う
- ログランク検定は時間がたてばたつほど、群間差が開いてくる」タイプのデータに対して有意差がつきやすくなり、一般化ウィルコクソン検定は「結局ほぼ全員が死亡するのだけど、生存時間が延びる」タイプのデータで有意差がつきやすくなる。









コメント