
本記事は「教師あり学習と教師なし学習の違いは?具体例で解析の目的を整理する」ということでお伝えします。
教師なし学習・教師なし学習は、医療統計学というよりも、機械学習の分野に括られるかとは思いますが、その根底には統計学が用いられます。
この記事では
- 教師なし学習と教師なし学習の違いは?
- 教師あり学習の具体例
- 教師なし学習の具体例
ということでお伝えしますね!

教師あり学習と教師なし学習の違いは?

教師あり学習と教師なし学習の違いについて結論から述べると、「正解」を人間側が与えてコンピュータに何かしらの判断をしてもらうかどうかの違いです。
「正解」とは例えば何かといえば、
- このメールはスパムであり、このメールはスパムではないというラベル
- この人はがんに罹患していて、この人はがんに罹患していないというラベル
などです。
上記のような正解を与えてプログラムする=教師あり学習と呼び、正解がない中でプログラムする=教師なし学習、と呼んでいます。
教師あり学習とは?
教師あり学習とは上記の通り、人間側が正解を付与し、その正解に対するルール作りをプログラムに任せることです。
この時、ルールを作るデータのことを学習データ、と呼びます。
教師あり学習の場合、ルールを作るデータとは別のデータ(テストデータ)を確保して、作ったルールでテストデータがちゃんと分類できるかどうかが重要な問題になります。
つまり、正解・不正解が明確な問題の解決に利用できる学習手法ともいえますね。
結果として「正解率がXX%だった」「XX%の確率でがんに罹患する可能性がある」というような数値化が可能なのも教師あり学習の特徴です。
教師なし学習とは?
教師なし学習とは、正解のないデータに対して、分類をプログラムに任せることでした。
例えば、データの構造やパターンなどを抽出することが目的になるため、正解・不正解を問題にしていない点が特徴的です。
そして、分類した結果が合っているかどうかは確かめようがなく、結果を人間側が解釈して考察することが重要なんです。
教師あり学習の具体例

教師あり学習と教師なし学習の違いがわかったところで、教師あり学習の具体例を見ていきましょう。
教師あり学習の具体例1:受信した電子メールがスパム(迷惑メール)かどうかを自動判定する
例としては、受信した電子メールがスパム(迷惑メール)かどうかを自動判定する、ということにも教師あり学習が有効です。
実際には、以下の3つの手順で教師なし学習を実施します。
- 過去に受信したメールにたいして、人間側が「通常のメール」と「スパムメール」の正解を付与した学習データを読み込ませます。
- そして学習データでコンピュータがルールを作ります。
- そのルールに従って「通常のメール」と「スパムメール」の正解を付与したテストデータをちゃんと分けることができればOK。
学習データでルール作りをした後に、「このルールは使えるのか?」という検証をテストデータで実施することが重要ですね。
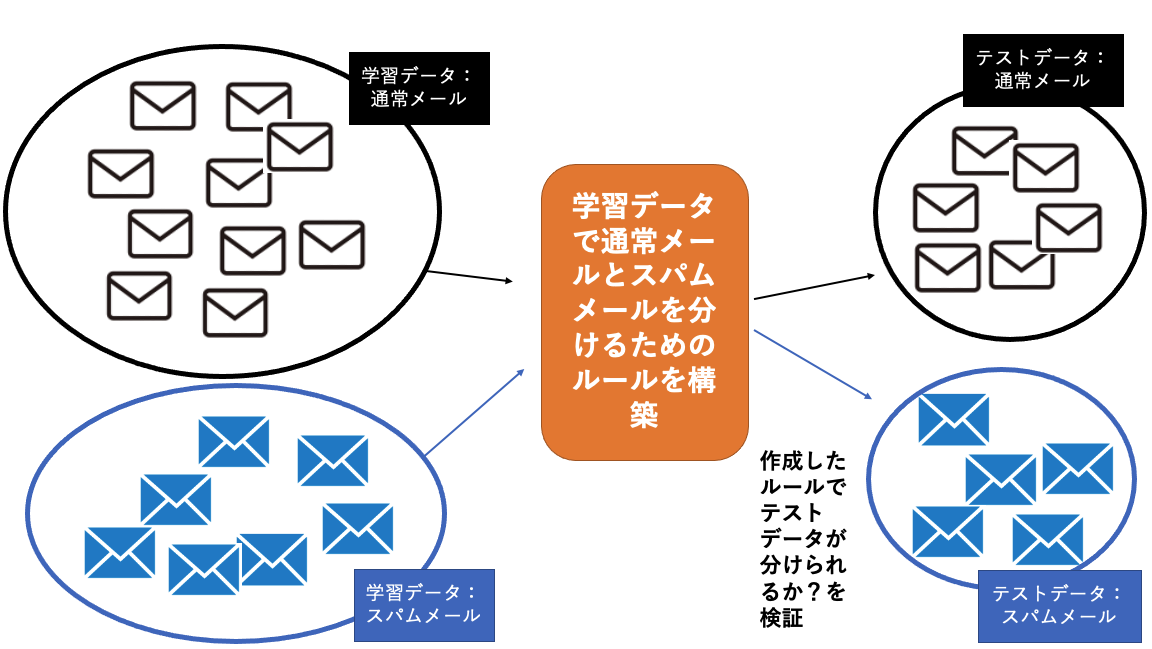
そして、このメールはスパム、このメールは通常メール、という正解を付与しているため、作成したルールが問題ないかどうかは正解率という数字で数値化が可能です。
教師あり学習の具体例2:新築の住宅販売価格を、過去の実績に基づいて予測する
新築の住宅販売価格を、過去の実績に基づいて予測する際にも、教師なし学習が適用できます。
- 過去の住宅販売価格の実績の70%を学習データとして読み込ませる
- そして学習データでコンピュータがルールを作ります
- 過去の住宅販売価格の実績の残り30%をテストデータとして読み込ませてどのぐらいの価格の差異があるかを評価する
手順としてはスパムメールの例と同じですね。
ただし今回の場合、住宅販売価格という連続量(量的データ)を扱っているため、数値化にはテストデータに対する「実績と予測値との差異」が数字として必要になります。
教師あり学習で重要なこと
すでにお伝えしていますが、教師あり学習で重要なことは「学習データ」と「テストデータ」の2種類を用意しておくことです。
なぜなら、学習データ全てを用いてモデルの構築行うと、そのデータには適合することができても、その後入ってくる未知のデータには全く合わないモデルが形成されてしまうことがあるからです。
このような問題を過学習(オーバーフィッティング)といいます。
この過学習を防ぐために、手元にあるデータを教師データとテストデータに分割してモデルの構築と予測を行う必要があるんです。
いわゆる、内的妥当性や外的妥当性を担保すること、という意味になります。
教師あり学習の具体的なアルゴリズムは?
教師あり学習がどんなものなのかがわかったところで、具体的なアルゴリズムをいくつか紹介します。
ここに挙げたものが全てではないですが、多くの場合にはこれらの中のどれかで実施していることが多いかなと思います。(ディープラーニングは除く)
- 線形回帰:特にロジスティック回帰は医療統計で多用されます
- サポートベクターマシーン(SVM)
- ランダムフォレスト
- 決定木
- k近傍法(kNN)
それぞれの具体的な手法は別記事でお伝えしますね。

教師なし学習の具体例

では次に、教師なし学習の具体例を見ていきましょう。
教師なし学習の例:受信した電子メールのうち、文章の特徴が似ているか否かを導きグループ分けする
教師あり学習の場合、受信したメールを「スパム」「通常」と正解は人間側が付与していました。
しかし「どれがスパムか通常か分からない状況で、とにかくメールの特徴からグループ分けしたい」という場合には、教師なし学習を実施します。
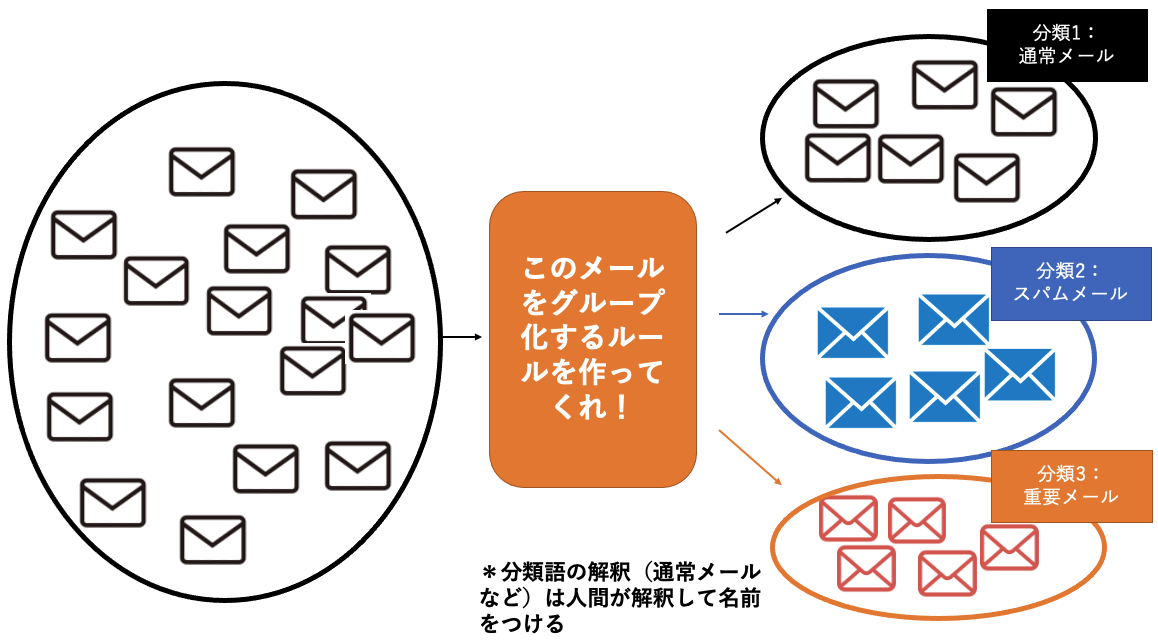
特徴的なのは、グループ分けした結果に対して正解・不正解はなく、どのグループが何を示すのかは人間側が解釈することです。
主成分分析で算出された主成分が、どのような意味を持つのかは研究者側が解釈するのと同じですね。
教師なし学習の具体的なアルゴリズムは?
教師なし学習がどんなものなのかがわかったところで、具体的なアルゴリズムをいくつか紹介します。
ここに挙げたものが全てではないですが、多くの場合にはこれらの中のどれかで実施していることが多いかなと思います。
- クラスタリング
- 主成分分析
- k平均法(k-means)
まとめ

いかがでしたか?
本記事は「教師あり学習と教師なし学習の違いは?具体例で解析の目的を整理する」ということでお伝えしました。
- 教師なし学習と教師なし学習の違いは?
- 教師あり学習の具体例
- 教師なし学習の具体例
ということが理解できたのなら幸いです!







コメント