
ある現象が生じる確率をモデル化する方法として、ロジスティック回帰分析があります。
ロジスティック回帰は、応答変数(目的変数)が二値のカテゴリカルデータの場合に有効な解析ですよね。
この記事では統計解析ソフトJMPを使ったロジスティク回帰分析の実施法について解説していきます。
JMPを使えば、ロジスティック回帰分析は簡単に実施できますよ!

JMPで多変量解析の一つであるロジスティク回帰分析!

ロジスティック回帰分析は様々な要因から、ある現象の発生確率を予測する多変量解析の手法の一つです。
ロジスティック回帰分析は、予測したい値、つまり応答変数(目的変数)がカテゴリカルデータ(質的データ)であるときに用います。
カテゴリカルデータというのは、例えば、”勝敗”や”生死”といった、数値ではないデータです。
また、身長や体重といった連続的なデータでも上位、中位、下位といったようにグループ分けすることで、カテゴリカルデータにすることができます。
多変量解析の手法の一つである重回帰分析では、予測結果は0~1範囲を超えることがあります。
一方で、ロジスティック回帰分析では、予測した確率が、0~1の範囲に収まります。
そのため、病気の発症確率や、生存確率などの解析に用いられます。
発生確率120%や-10%はあり得ませんよね。
それではJMPでロジスティック回帰分析を行っていきます。
JMP でロジスティック回帰解析
統計解析ソフトJMPには二種類のロジスティック回帰分析が実装されてています。
- 名義ロジスティック回帰(二項ロジスティック回帰、多項ロジスティック回帰)
- 順序ロジスティク回帰
この二つは、応答変数(予測したいデータ)の種類によって異なります。
応答変数が例えば、「成功と失敗」や「生と死」といった2値のカテゴリカルデータ(名義尺度)であれば名義ロジスティック回帰を使います。
リッカート尺度の5件法などで取られたデータを順序カテゴリカルデータのまま扱いたい場合であれば、順序ロジスティク回帰を用います。
JMPで名義ロジスティック回帰のやり方:オッズ比の出力方法と結果の見方まで

まずは、JMPで名義ロジスティック回帰分析をする方法をお伝えします。
JMPにデータの読み込み
自分たちのデータを解析する場合は、[ファイル] > [開く]から解析したデータを開いてください。
JMPではExcelやCSV形式のデータを開くことができます。
この記事では、JMPにすでに用意されているサンプルデータ「Endometrial Cancer」を使ってロジスティック回帰分析を実施していきます。
Endometrial Cancerは「医学研究」の中にあります。

まずは、0と1の連続尺度で入力されているサンプルデータ に対して、名義尺度に変更していきます。
0と1で入力されているので連続尺度となっていますが、「Yes/No」と入力しても良いようなデータのため、本質的には名義尺度で扱った方が良さそうだからです。
JMPで連続尺度を名義尺度にするには、データの左側にある「列」パネルで操作します。
「アウトカム」の左側にある青い三角形を押すと、現在のデータが連続尺度であることがわかります。
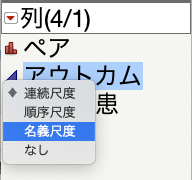
これを名義尺度に変更します。すると、「アウトカム」の左側が赤い棒グラフのようなマークに変わったことがわかります。

「胆嚢疾患」も「高血圧」も同様に、名義尺度に変更しておきます。
下記の図のように、全ての変数が名義尺度になれば完了です。

データの準備が完了したため、ここからロジスティック回帰分析を実施していきます。
JMPで名義ロジスティック回帰解析の実行:オッズ比の出力まで
対象となるデータ(今回はEndometrial Cancer)を開いた状態で[分析] > [モデルのあてはめ]を選択します。
すると、モデルを指定するボックスが出てくるため、「Y」にアウトカムを入れ、「モデル効果の構成」に胆嚢疾患と高血圧の2つを追加します。
「アウトカム」は2値のカテゴリカルデータ(名義尺度)であるため、右上に自動で”名義ロジスティック”となることがわかります。
また、イベントを示す水準も自動的に指定されます。
この時、イベントを示す水準が意図通りになっていることを確認してください。
今回はアウトカム=1が子宮内膜がんの発症を示すので、「イベントを示す水準」は1とするのが適当です。

[実行]をクリックします。
すると「名義ロジスティックの当てはめ アウトカム」という結果レポートが出力されます。

ロジスティック回帰分析では「オッズ比」を確認することが重要なため、オッズ比を出力します。
「名義ロジスティックの当てはめ アウトカム」の横にある赤い三角形を押し、「オッズ比」を選択します。
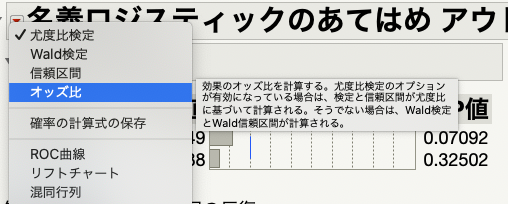
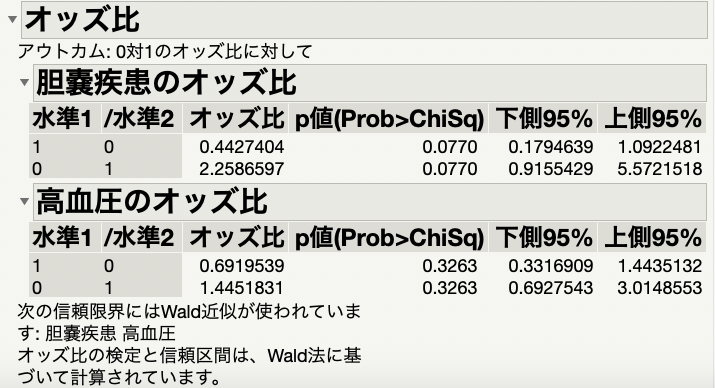
すると、結果のレポートの1番下にオッズ比が出力されました。
以上で、JMPでロジスティック回帰分析を実施できました。
JMPで名義ロジスティック回帰分析をした結果の見方:オッズ比の値にも注目する
JMPでロジスティック回帰分析を実施すること自体は全く難しくありませんでした。
アウトカムを名義尺度にしておけば、共分散分析と同じ手順で実施可能。
解析の実施自体は簡単ですが、重要なのは結果の解釈です。
特に注意してみたいのが「パラメータ推定値」と「オッズ比」の2つ。
まずは、「パラメータ推定値」で得られている値を確認しましょう。
今回、説明変数に胆嚢疾患の有無と高血圧の有無を指定し、応答変数に子宮内膜がんの有無を指定しました。
その際に考えている数式は以下の通りということです。

応答変数にあるLogitというのが、いわゆる“ロジット変換”と呼ばれている変換式です。
詳細は他の書籍やWebサイトを参照していただければと思いますが、ロジット変換した変数をアウトカムにするため、ロジスティック回帰分析と呼ばれています。
今回の結果をみると、β=-0.29(少数以下3位を四捨五入)であり、α1=0.41、α2=0.18、であるため、得られたモデル式は下記のように書き換えることができます。

カテゴリカルデータが説明変数にあるため、推定値の解釈に注意が必要です。
カテゴリカルデータの場合、「全体の平均値と各カテゴリの差」ということが示されています。
さらには今回、2つのカテゴリカルデータがあるため、それぞれの組み合わせで4通り考えられることになります。
P値をみると、胆嚢疾患の有無のP値は0.077であり、高血圧の有無は0.326でした。有意水準0.05を基準にすればどちらも有意差はありません。
しかし、オッズ比をみてみると、胆嚢疾患の有無は2.26と高いオッズ比を示しているため、p値が十分に小さくなかったのはサンプルサイズが不十分だった可能性があります。
このように、統計学的に差が出なかったとしても、その差は臨床上インパクトがあるのかどうかの考察は必ず必要になります。

JMPで順序ロジスティック回帰のやり方:結果の見方まで

では次に、JMPで順序ロジスティック回帰分析をする方法をお伝えします。
JMPへデータの読み込み
順序ロジスティック回帰解析でも、JMPにすでに用意されているサンプルデータを使います。
[ヘルプ] > [サンプルライブラリー]をクリックします。
すると、次のサンプルデータのディレクトリのウィンドウが出てきます。
今回はこの中の”Cheese.jmp”を使います。
このデータは”チーズの添加物とその味”を調べています。
「チーズ」の項目は、A〜Dまでの加えた添加物を表しています。
「評価」は試食した人が1(非常にまずい)-9(とても美味しい)の9段階評価で味を評価したものです。
順序ロジスティック回帰を実施する前に、まずは分割表でデータを確認してみます。
「分析」>「二変量の関係」から、Yに評価を、Xにチーズを、度数に度数を選択します。
すると下記のような結果になり、なんとなくDの群ではとても美味しいと答える人が多く、反対にBの群では非常にまずいと答える人が多そうだ、ということがわかります。

このように、順序ロジスティック回帰をする前に、どんな傾向がありそうかを分割表で確認しておくことは重要です。
JMPで順序ロジスティック回帰解析の実行
順序ロジスティック回帰を実施するには、アウトカムが順序尺度となっている必要があります。
今回「評価」は順序尺度になっていることがわかります。

今回は”チーズの添加物とその味の評価”のデータを用いて、添加物が味の評価に与える影響を予測するモデルを作っていきます。
[分析] > [モデルのあてはめ]を選択します。
すると、次のウィンドウが出現しますので、[Y]に「評価」を選択します。
1~9の9段階評価は順序尺度のため、右上のところが、自動で”順序ロジスティック”となります。

[モデル効果の構成]には「チーズ」を選択します。
[度数]には「度数」を選びましょう。
選択ができたら[実行]をクリックします。
JMPで順序ロジスティック回帰分析をした結果の見方
計算が終われば、次の結果が出力されます。
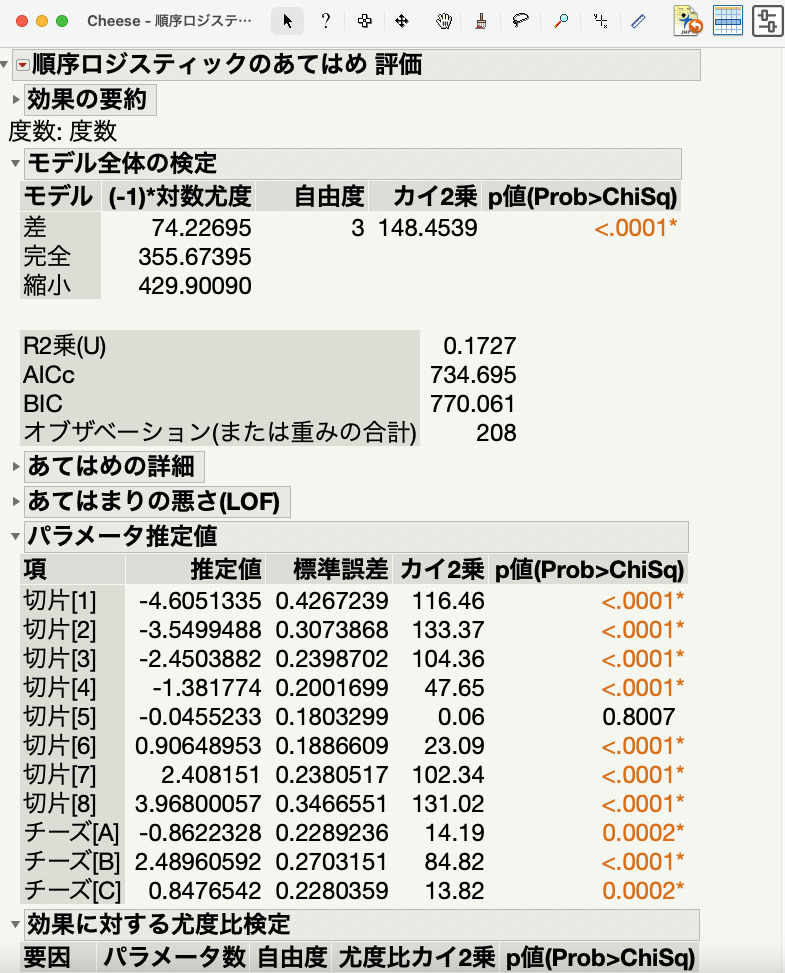
各添加物が「評価」に寄与しているかどうかは、パラメータ推定値を見ればわかります。
ここで、推定値が最小のものが、もっとも評価の高いチーズを意味します。
チーズDはここには出ていませんが、Dのパラメータ推定値は、他のパラメータ推定値の合計を-1倍した値です。
そのため、
(チーズ[A]+チーズ[B]+チーズ[C]) x (-1)= -2.4750
になります。
結果からは、Dの添加物がもっとも人気で、Bの添加物がもっと不人気ということになります。
これは、最初に分割表で確認した結果と同じような解釈ができますね。
JMPでロジスティック回帰分析をする方法まとめ

- 統計解析ソフトJMPには二種類のロジスティック回帰分析が実装されいる。
- 応答変数が名義なのは名義ロジスティック回帰
- 応答変数が順序なのは順序ロジスティク回帰
- [分析] > [モデルのあてはめ]から行う








コメント
コメント一覧 (2件)
[…] >>JMPで多変量解析のロジスティック回帰分析! […]
[…] JMPでロジスティック回帰分析を実施すると「モデル全体の検定」という名前で出力されます。 […]