
この記事では「Clopper-Pearsonの信頼区間とは?Rでの計算方法も!」としてお届けします。
- Clopper-Pearsonの信頼区間とは?
- Clopper-Pearsonの信頼区間を使った論文例
- Clopper-Pearsonの信頼区間のRでの計算方法
といった内容を理解できるようになっていますので、ぜひ最後までご覧くださいませ!

Clopper-Pearsonの信頼区間とは?

Clopper-Pearsonの信頼区間は、2値のカテゴリカルデータの割合に関して95%信頼区間を算出したい、というときに選択肢として入ってくる信頼区間です。
通常この場合には、Waldの信頼区間が統計ソフトでもデフォルトであることが多い。
ですが、Waldの信頼区間は正規分布に近似した手法であるため、サンプルサイズが大きい場合に有用な信頼区間の算出方法です。
一方で、少数の標本の場合には正規近似の精度が落ちてしまうので、Waldの信頼区間では適切ではないことも。
その時に出てくるのがClopper-Pearsonの信頼区間なんです。
Clopper-Pearsonの信頼区間は正規近似を必要としない信頼区間
Clopper-Pearsonの信頼区間は、正規近似を必要とせず、二項分布とF分布の関係性を使った方法です。(詳しい数式はスキップします)
正規近似よりも正確な信頼区間となることが特徴であり、小標本(サンプルサイズが小さい状況)でも使える信頼区間なんです。
そのため、Waldの信頼区間の弱点を見事に補完している信頼区間とも言えますね。
Clopper-Pearsonの信頼区間を使った論文例
もしかしたら、Clopper-Pearsonの信頼区間というものを初めて目にした方もいるんじゃないかと思います。
そのため、「本当に論文とかで使われてるの…?」と疑問に思うはず。
実は、ちゃんと論文でも使われている信頼区間なのです。
例えば、こちらの論文。(https://www.nejm.org/doi/full/10.1056/NEJMoa2103695)
Methodではこのように記載されています。

(引用:Sotorasib for Lung Cancers with KRAS p.G12C Mutation N Engl J Med 2021;384:2371-81. DOI: 10.1056/NEJMoa2103695)
Responseに対するパーセント(まさに2値のカテゴリカルデータの割合)に対する95%信頼区間にClopper-Pearsonの信頼区間を使った、と書かれてあります。
Clopper-Pearsonの信頼区間は、小標本(サンプルサイズが小さい状況)でも使える信頼区間とのことですが、この論文ではサンプルサイズがどれぐらいだったのか気になりますよね。
研究全体での症例数は126例ですが、バイオマーカーごとのサブグループ解析をすると、9例〜86例のサブグループになるような解析を実施しています。
9例のサブグループに対してClopper-Pearsonの95%信頼区間を算出するため、まさに小標本に対する95%信頼区間ですね。

Clopper-Pearsonの信頼区間のRでの計算方法
最後に、RでClopper-Pearsonの信頼区間を計算する方法をお伝えします。
RでClopper-Pearsonの信頼区間を計算するためには、PropCIsというパッケージををインストールする必要があります。
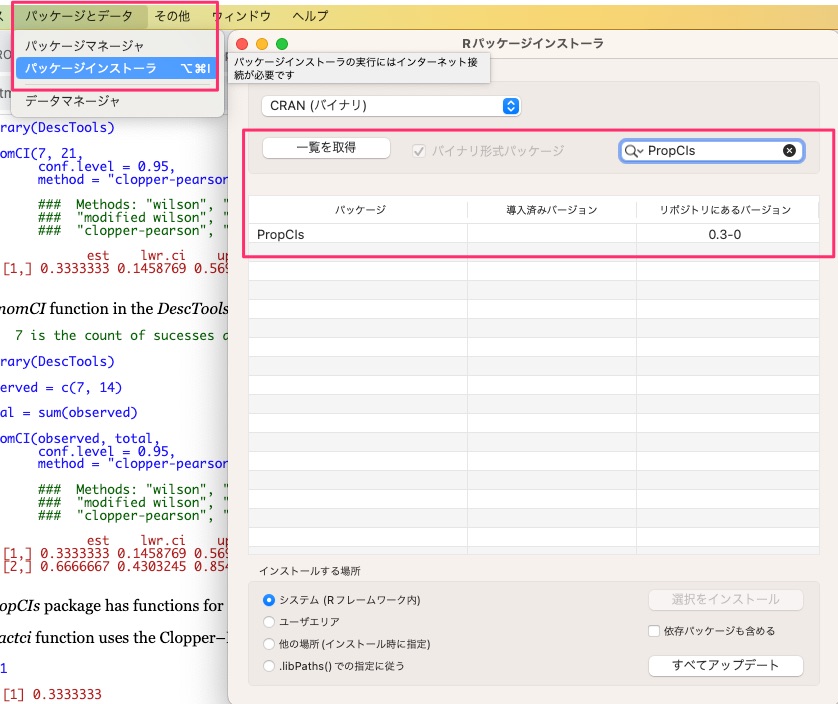
そのため、PropCIsを先にインストールしておいてください。
実は、このPropCIsをインストールしておけば、プログラム自体は簡単なんです。
例として、21例中、7例にレスポンスがあった場合のClopper-Pearsonの信頼区間を算出してみます。
この場合、下記の2行のプログラムを実施することでClopper-Pearsonの信頼区間を計算することが可能です。
library(PropCIs)
exactci(7, 21, conf.level=0.95)
そうすると、下記の結果が算出されます。
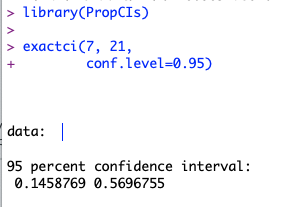
つまり、95%信頼区間は0.1458769〜0.5696755という計算結果になりました。
まとめ
いかがでしたか?
この記事では「Clopper Pearsonの信頼区間とは?Rでの計算方法も!」としてお届けしました。
- Clopper-Pearsonの信頼区間とは?
- Clopper-Pearsonの信頼区間を使った論文例
- Clopper-Pearsonの信頼区間のRでの計算方法
といった内容を理解していただけたのなら幸いです!
こちらの内容は、動画でもお伝えしておりますので、ぜひ併せてご覧くださいませ。








コメント