
論文を読んでいると「層別解析」とか「サブグループ解析」の結果をよく見るのではないかと思います。
でも「層別解析」と「サブグループ解析」の違いや、その目的に関してちゃんと把握しているでしょうか?
この記事では「層別解析」と「サブグループ解析」に関して以下のことがわかるようになります。
- 層別解析とサブグループ解析の違いは?
- 層別解析とサブグループ解析はどんな目的で実施されるの?
- サブグループ解析のグラフ化であるフォレストプロットの見方は?

層別解析とサブグループ解析とはどんな違いがあるの?

まずは層別解析とサブグループ解析の違いについて解説します。
層別解析とサブグループ解析の用語に関しては同じ意味として使っている方も多いですが、実はちょっとだけ違うんです。
層別解析を理解するのに必要な「層別因子」とは?
層別解析を理解するには、「層別因子」という用語を知っておく必要があります。
層別因子はICH E9に定義が書いてあって、以下がその定義です。
つまりここから分かるのが
- 層別因子は割付(ランダム化)の際に考慮すべき因子のこと
- 層別因子は疾患の予後に影響があると考えられる因子のこと
ということですね。
層別因子を考慮したランダム化である「層別ランダム化」というのがあります。
層別ランダム化とは、例えば、性別(男性と女性)が疾患の予後に影響がありそうなので層別因子として考えたい、とします。
この時に、被験者が男性か女性かに応じて、男性ごとにランダム化・女性ごとにランダム化、という作業をするのです。

層別因子のカテゴリごとにランダム化することによって、プラセボ群で実薬群で、男性と女性のバランスが取れることが期待できるのです。
層別因子は解析にも考慮しなければならない!その一つが「層別解析」である
そして、層別因子としてランダム化の際に考慮したら、解析段階でもその層別因子を考慮することが推奨されているのです。
そのため、層別因子を考慮した解析手法の一つが「層別解析」ということ。
層別解析をする目的は「交絡バイアス」を防ぐため。
層別解析の一つの例としては、「層別ログランク検定」というのがあります。
ログランク検定といえば、生存時間解析において最もメジャーな解析手法の一つ。
そのログランク検定を層別に考慮して解析しましょう、というのが層別ログランク検定。
サブグループ解析とは?
ではサブグループ解析はどんなものでしょうか。
サブグループ解析とは「ある因子(変数)のグループごと(カテゴリごと)に治療効果を推定すること」といえます。
例えば、性別という因子でサブグループ解析をしたい場合には、男性というグループ・女性というグループごとにそれぞれ治療効果を推定する、ということをします。
層別解析との決定的な違いは、層別解析では最終的に統合した一つの結果を示すのに対して、サブグループ解析ではグループごとの結果を示す、ということ。
性別という因子で層別解析すると、結果としては一つの結果が出力されますが、性別でのサブグループ解析では男性の結果と女性の結果、という2つの結果が出力されることになります。
層別解析の具体的な方法とは?結果を統合するってどういうこと?

層別解析とサブグループ解析の違いがわかったところで、層別解析の具体的な方法について理解していきましょう!
層別解析はまず、層別因子のカテゴリごとに解析をします。
例えば、男性・女性ごとに解析をする、ということです。
そうすると、男性の解析結果・女性の解析結果の2つの結果が出てくることになります。
サブグループ解析だったらここで終了なのですが、層別解析ではもうひと手間「2つの結果の統合」ということが必要です。
例えば、重み付き平均などを使うことで、2つの結果を統合します。
層別解析をすると複数の解析結果が出ると思われている方も多いのですが、最終的には結果を統合して1つの解析結果を示すことになる点に注意が必要です。

サブグループ解析は交互作用を検討する目的で実施する!

層別解析が「交絡バイアス」を防ぐ目的で実施されるのに対して、サブグループ解析は交互作用の有無があるかどうかを目的として実施されます。
交互作用がある場合、「その因子のカテゴリごとに治療効果が異なる」ということになります。
例えば、性別のサブグループ解析を実施した結果として、男性だとプラセボ群と実薬群に効果の差はなさそうなんだけど、女性だと差がある、といった時に、「性別と群の間には交互作用がある」関係ということ。
サブグループ解析の結果の横に交互作用のP値(P for Interaction)が付いていることが多いのは、上記のような理由があるからです。
研究結果として治療効果がサブグループによって異なること、特に異なるサブグループの間で効果が逆転する(例えば、男性では治療Aのほうが優れているが、女性では治療Bのほうが優れているような場合)ということも十分ありうるため、集団全体の効果を評価しつつ、さらに交互作用が疑われる要因についてサブグループ解析を行うのは重要です。
しかし、交互作用に関するP値(P for Interaction)を多用することは多重性の問題の観点からもNGですし、NEJMではP for Interactionを極力使わないようにガイドラインで定めています。
交互作用があるかどうかは数値だけでなく、臨床的な意味をちゃんと考察した上で論述することが重要です。
サブグループ解析のグラフ化の1つであるフォレストプロットの見方

サブグループ解析の結果の表示方法といえば、フォレストプロットが一般的です。
フォレストプロットとは、例えば下記のようなグラフのこと。
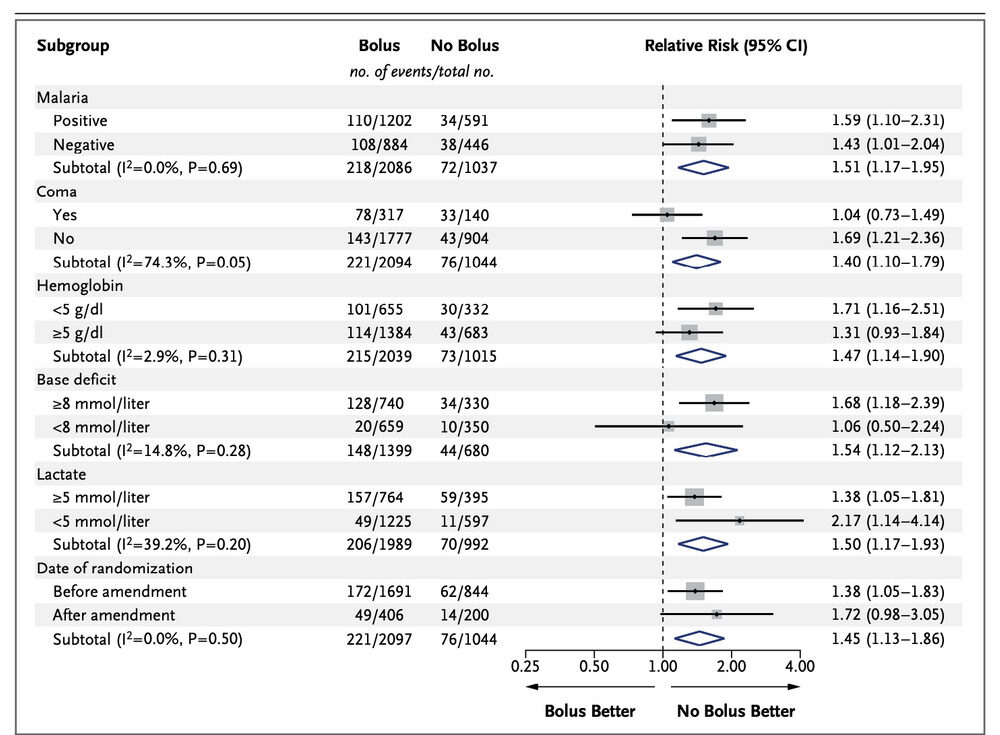
(https://www.nejm.org/doi/full/10.1056/NEJMoa2035389 のFig3を引用)
各カテゴリごとに点推定値とその95%信頼区間が表示されています。
フォレストプロットはサブグループ解析をグラフ化したものですので、見方としては「交互作用があるかどうか」という視点が重要です。
例えば上記のフォレストプロットだと、「Malaria」ではどちらのグループでも右側にあることがわかりますが、「Coma」ではYesのグループの結果は左側にありNoのグループの結果は右側にあることがわかります。
じゃあComaでは交互作用があるか、というと、そこは注意が必要。
というのも、サブグループ解析はグループごとに症例数(データ数)が少ない場合もあり、今回の結果はたまたまかもしれない可能性が否定できないためです。
そのため、数値だけで判断するのではなく、臨床的な意味合いも含めて全体的に考察する必要があるのです。

まとめ
いかがでしたか?
「層別解析」と「サブグループ解析」に関して以下のことが理解できたのなら幸いです!
- 層別解析とサブグループ解析の違いは?
- 層別解析とサブグループ解析はどんな目的で実施されるの?
- サブグループ解析のグラフ化であるフォレストプロットの見方は?
こちらの内容は動画でも解説しておりますので、併せてご確認ください!










コメント
コメント一覧 (1件)
[…] また、層別解析も交絡バイアスを排除するための解析手法です。 […]