
群間比較の効果を調べる際に、交絡因子による結果へのバイアスが生じないようにすることはとても重要です。
バイアスを生じないようにするため、計画段階で実施できることがランダム化によるランダム化(無作為化)比較試験ですよね。
しかし観察実験では、ランダム化ができない場合があります。
ランダム化ができない場合に共変量のバイアスを小さくする方法として、傾向スコアマッチング法(プロペンシティスコアマッチング法)が考案されています。
この記事では、実際にEZRで傾向スコアマッチングを実施する方法をお伝えしていきますね。
論文でも使われることが多くなった傾向スコアマッチングを自分でできるようになると、確実に武器になりますので、ぜひ実践できるようにしていきましょう!

傾向スコアマッチング(プロペンシティスコアマッチング)とは?
そもそも傾向スコアマッチングとは共変量によるバイアスを小さくするために用いられる手法です。
観察研究で多く用いられている印象ですね。
というのも、臨床試験などの介入研究では、ランダム化(無作為化)比較試験によって共変量によるバイアスを小さくすることができます。
しかし観察研究では、無作為化比較試験のような操作を行うことはできません。
例えば、新しい抗がん剤が既存の薬剤に比べて効果があるかどうかを知りたい時、2群間で病気の重症度が異なっていたらどうでしょうか?
新しい抗がん剤治療を選択する人は重症度が高い患者さんが多く、既存の薬剤を選択する人は軽症な場合が多い時には、どれだけ新しい抗がん剤が優れていたとしても、効果がないという結果が出る可能性があります。
それを防ぐ方法として、傾向スコアマッチング法を使って、あたかも2群間で同じような集団を作り上げることができるのです。
結構、便利な方法ですよね。
EZRで実際に傾向スコアマッチングを実施!データや目的はどうなっている?

では実際にEZRで傾向スコアマッチングをやっていきましょう!
EZR作成者である神田先生の書籍「EZRでやさしく学ぶ医療統計学」についてくるサンプルデータを使います。

サンプルデータの「CaseControl」というデータを使います。
群の情報が「group」という名前の変数として格納されており、実際のデータは0と1が入っています。
このデータに対して、群間で性別と年齢がどれだけ違うのか、要約統計量を確認してみましょう。

群ごとの例数は、group=0が600名であり、group=1が30名であるので、かなり例数が違いますね。
そして、性別も年齢も群間で違いがありそうです。
(性別のP値は0.05より大きいですが、P値は例数によって容易に変動するので、参考までにみることでOKです。)
なので、性別と年齢がアウトカムに影響を与える共変量だと仮定し、傾向スコアマッチングを使って群間この2つの因子を揃えたいと考えます。

EZRで実際に傾向スコアマッチングを実施!ステップバイステップでわかりやすく解説!
データと傾向スコアマッチングを実施する目的が整理できたので、実際にEZRで傾向スコアマッチングを実施していきましょう。
実際にはこの3つの手順で実施していきます。
- ロジスティック回帰分析を用いて傾向スコアの推定
- 傾向スコアを利用してマッチング
- マッチング後のデータに関してバランスの評価
では、それぞれ詳しく解説していきますね。
EZRで傾向スコアマッチング1:ロジスティック回帰分析を用いて傾向スコアの推定
「傾向スコアマッチング」は「傾向スコア」を用いて「マッチングする」という意味です。
そのため、まずは「傾向スコア(プロペンシティスコア)」を推定していきます。
では何で傾向スコアを推定するかというと、ロジスティック回帰分析です。
EZRでも簡単にロジスティック回帰分析できますし、傾向スコアマッチングを見据えたオプションもEZRには搭載されています。
じゃあどんなモデル式で傾向スコアを推定するかというと、性別と年齢がアウトカムに影響を与える共変量だと仮定しているので、下記のモデル式でロジスティック回帰分析をしていきます。
(係数などは全て省略)
群=性別+年齢
目的変数に「群」の変数を指定するのが重要ですね。
じゃあ早速やっていきましょう!
「統計解析」→「名義変数の解析」→「二値変数に対する多変量解析(ロジスティック回帰)」を選択します。
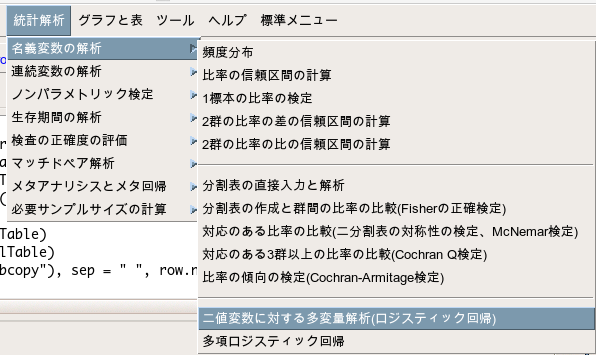
そして、目的変数に「group」を選択し、説明変数に「age」と「sex」を選択します。
ここで、「傾向スコア変数を自動作成する」にチェックを入れてください。
そうすることで傾向スコアが自動的に推定されます。
で、「OK」を押すとロジスティック回帰分析をやってくれますね。
ageとsexのオッズ比なども出てきていますが、今回の傾向スコアマッチングでは特に気にしなくてOK。
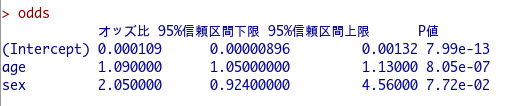
重要なのはむしろデータセットです。
先ほどロジスティック回帰分析をしたデータ(CaseControl)をみると、PropensityScore.GLM.1という名前で自動的に傾向スコアが格納されていることがわかります。
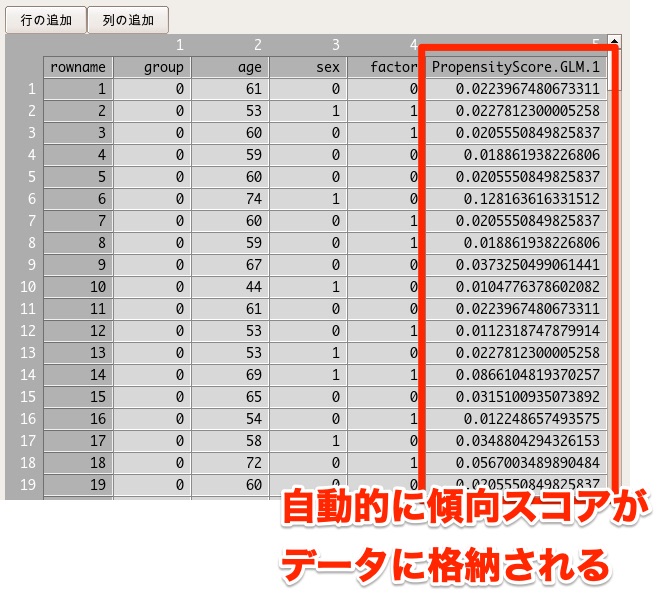
これをチェックボックス一つで自動的にやってくれるのがすごいですよね。。
以上で、傾向スコアの推定が終わりました。
EZRで傾向スコアマッチング2:傾向スコアを用いてマッチング(マッチドペア解析)
「傾向スコアマッチング」は「傾向スコア」を用いて「マッチングする」という意味でしたね。
手順1で傾向スコアを推定することができたので、今度は「マッチング」をしていきます。
EZRでどうやってマッチングさせるかというと、「統計解析」→「マッチドペア解析」→「マッチさせたコントロールの抽出」から実施します。
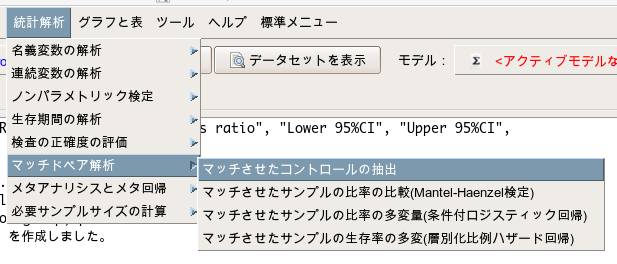
比較する群の変数では「group」を選択し、マッチさせる変数は手順1で推定した傾向スコア「PropensityScore.GLM.1」を選択します。
そして、1つのケースに対応するコントロールの数は、目的に応じて設定してください。
今回はデフォルトの1を入れておきます。
1を入力していると、コントロール:ケース=1:1でマッチングします。
もし仮に3を入力すると、コントロール:ケース=3:1でマッチングします。
今回のデータはマッチング前の例数がコントロール:ケース=600例:30例なので、3:1とか5:1でもいい気もしますが、とりあえずデフォルトの1でやります。
そして、キャリパー幅も入力できますが、デフォルトの0.2を入れておけば文句は言われないでしょう。
キャリパーに関してはまた別の記事で詳しく解説しますね。
これでOKを押すと、自動的にマッチングをしてくれます。
そして問題なくマッチングされたので、メッセージ欄に「メモ: データセット CaseControl_MP には 56 行、6 列あります.」と表示されました。
EZRではマッチングすると、「元のデータセット名_MP」という名前で自動的にマッチング後のデータを作ってくれます。
MPはおそらくマッチドペアの略ですね。
EZRで傾向スコアマッチング3:マッチング後のデータセットに関してバランス評価
手順の1と2で傾向スコアマッチングは完了できました。
なので最後に、マッチング後のデータセットが本当にバランスの取れたデータになっているのか確認してみます。
マッチング後のデータセットである、データセット CaseControl_MPに対して、群別に要約統計量を確認しましょう。

1つのケースに対応するコントロールの数を1に設定したので、1:1(28例:28例)のマッチングになりました。
そして、性別も年齢も群間でバランスが取れたデータになりましたね。
上記では群間の違いに関して、p値を参考までに見ていますが、標準化差(Standardized Difference)を見る方が良いと思います。
以上で、EZRを使って傾向スコアマッチングができました。
これ以降は、マッチング後のデータを使って共分散分析やCox比例ハザードモデルなどの多変量解析を実施することが多いかな、という印象です。
まとめ
この記事ではEZRを使って実際に傾向スコアマッチングをする方法について解説しました。
手順をおさらいすると、以下の3つでしたね。
- ロジスティック回帰分析を用いて傾向スコアの推定
- 傾向スコアを利用してマッチング
- マッチング後のデータに関してバランスの評価
ぜひあなた自身でもできるようになりましょう!!










コメント