
統計学的検定の中で、一番有名といっても過言ではないT検定。
今回の記事では、T検定をSPSSで実施する方法を解説するとともに、結果の見方もわかりやすく解説します。
医薬研究でよく用いられる統計ソフトであるSPSSの使い方を、ぜひ学んでみてください。

SPSSでT検定を実施するために必要となるデータ

T検定とは、2群の母平均を比較する検定方法でしたね。
ということは、T検定をするためのデータは以下の2つを満たす必要があります。
- 母平均を検定する方法であるため、目的変数(アウトカム)には連続量のデータが必要。
- 2群の群間で母平均を比較するので、説明変数には、2つ以上のカテゴリを持つカテゴリカルデータが必要。
ということで、今回の記事で使うデータです。
今回のデータは、EZRでT検定を実施した時と同じデータを用います。
A群、B群の2つの群で、LDHの平均値を比較する、ということですね。
(データは架空のデータです。)
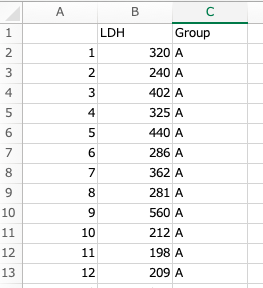
「LDH」の列が連続データで、「Group」の列が群を示した変数です。
A群13例、B群11で、計24症例分のデータがあります。
SPSSにT検定を実施する基となるデータを読み込む
ではここから、SPSSにデータを取り込みます。
まずは、サンプルデータを適切な場所に保存しておきましょう。
SPSSを開き「ファイル」→「データのインポート」→「CSVデータ」を選択します。
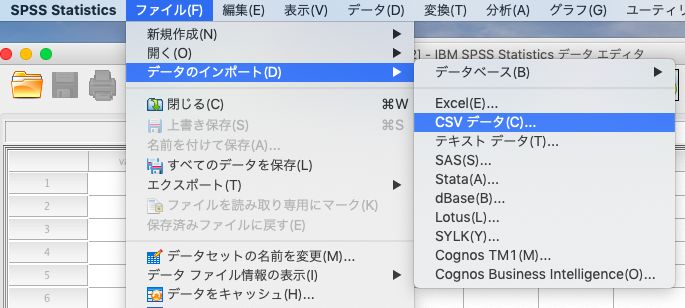
そうすると、以下のような画面になりますので、特にいじらずにOKで大丈夫です。
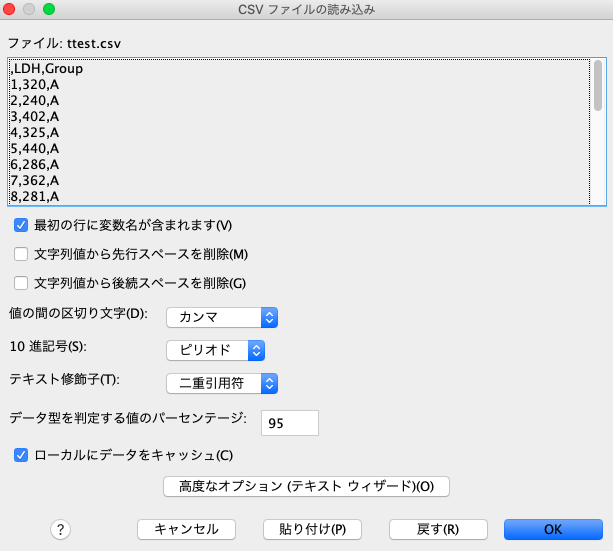
そうすると、以下のようにちゃんとインポートされました。
データの見た目は、エクセルと同じ感じですね。
連続量のデータであれば右揃えでデータが表示され、カテゴリカルデータであれば左揃えでデータが表示されます。

SPSSで2群比較のT検定を実践する!
解析するための準備が整いましたので、早速T検定を実施してみましょう。
T検定を実施するには、以下の手順で行います。
「分析」→「平均の比較」→「独立したサンプルのt検定」です。
今回のデータは特に対応のないデータですので、独立したサンプルのt検定を選びます。
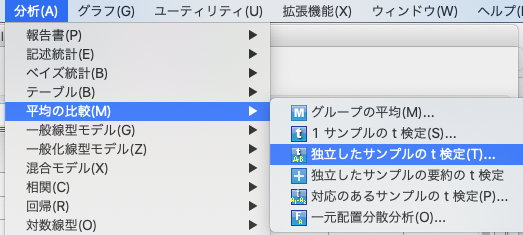
- 検定変数に「LDH」を選びます。
- グループ化変数に「Group」を選びます。
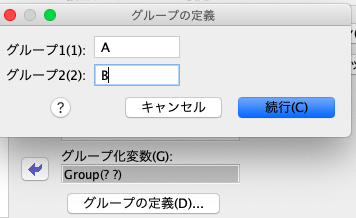
まだこれだけでは不十分で、「グループの定義」を押します。
すると、2群はどれにするのかを指定することができます。
今回はAとBで比較をするため、グループ1(1)にAを入力、グループ2(2)にBを入力します。
すると、以下のように結果が出力されました。
これでT検定の実施が完了です。
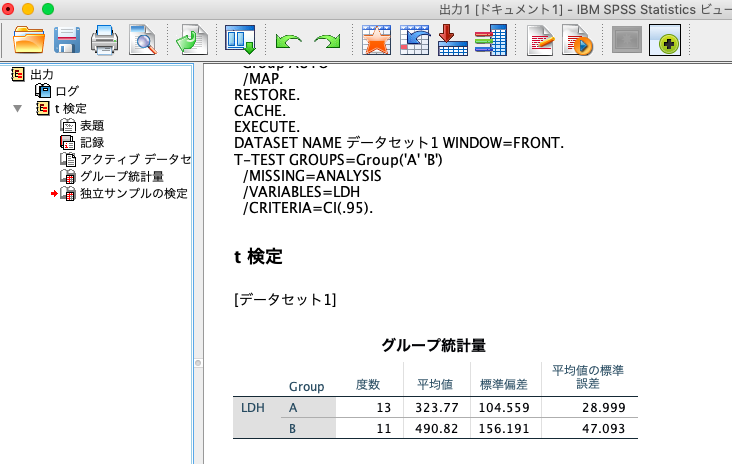
実際の出力では、以下の3種類が出力されます。
- T検定実施の際のログ
- 各群の要約統計量
- T検定結果
SPSSで実施したT検定結果の見方や書き方を解説
実際にT検定が実施できました。
では、結果の解釈をしていきましょう。
SPSSで実施したT検定のログを確認する
まずは、T検定のログを確認します。
ログ自体は確認しなくても良いことが多いですが、例えば論文を出したいために、ちゃんとQCをしたい場合などは確認する必要がありますね。
独立した二人で同じデータで解析を実施し、ログがちゃんと同じになるかどうかを確認することが大事だったりします。
解析結果が合わない時も、ログを確認することで、どこが違っているかを確認することができます。
そのため、解析結果のログを確認する習慣をつけましょう。

今回の解説では、詳細にはスキップします。
SPSSでT検定した結果の解釈:要約統計量が出力される
まずは要約統計量が出力されています。
A群とB群の各群の例数(度数)・平均値・標準偏差・標準誤差の4つが出力されていますね。
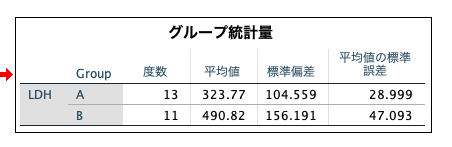
この結果だけでも、かなりの情報量があります。
平均値の差は結構あるな、とか。
平均値の標準誤差は結構違うな、とか。
ここの結果から、各群の正規分布の形までイメージできるといいです。
念の為、各群のヒストグラムと正規分布を確認してみましょう。
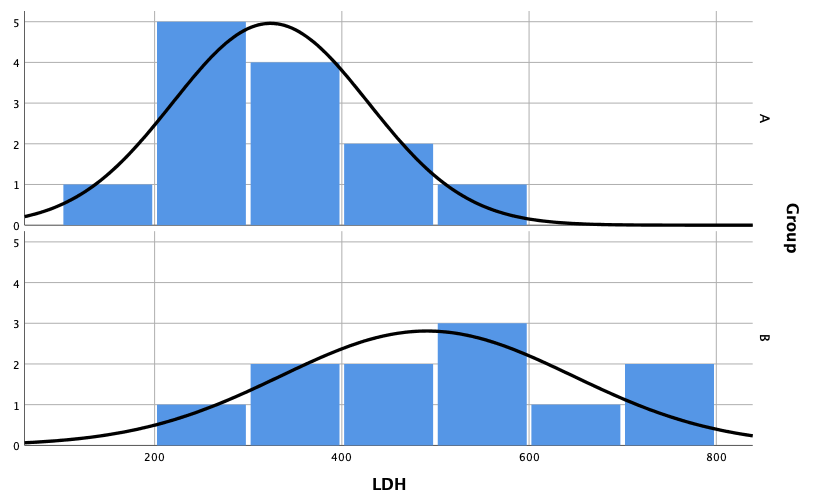
A群とB群で、平均値の位置(正規分布の山の頂点)と標準偏差(山のなだらかさ)が異なる気がしますね。
このように可視化することも大事です。
SPSSでのT検定の結果解釈
それでは、SPSSでのT検定の結果の見方を解説します。
SPSSでT検定を実施するとデフォルトで、「等分散を仮定した場合」と「等分散を仮定しない場合」の2種類のT検定を実施してくれます。
どちらの結果を信じればいいのか?と思うでしょうが、一律「等分散を仮定しない場合(下に出力されている結果)」で問題ないです。
というのも、等分散のための検定を確認することで多重性の問題が発生しますし、そもそもデータが多くなれば等分散のための検定結果も有意になりやすい(等分散ではないという結果)が出やすくなるため、等分散かどうかを検定に委ねるべきではないためです。

そして、T検定の結果として以下の情報が含まれています。
- T値
- 自由度
- P値(両側の有意確率)
- 平均値の差
- 差の標準誤差
- 95%信頼区間
自由度がなぜ22になるのかは理解できますか?
T検定の自由度は「データの数-群の数」だからですよね。
わからなければ、復習しましょう!
>>T検定での自由度がなぜ「データの数-群の数」になるのか!?
P値が0.05より小さい(.008とは、0.008の意味です)ため、有意水準を0.05に設定していた場合には、有意差ありという結論になります。
95%信頼下限も上限もどちらもマイナスの値です。
つまり、0を含んでいないということ。
95%信頼区間が0を含んでいないことは、有意水準5%の検定結果が有意になることと同じ解釈ですので、ここからも有意差ありと分かります。
T検定を実施した後の結果の書き方
実際にt検定を実施した後、学会発表資料や論文なんかに結果を記載する必要があります。
その際には、「平均」「SD」「p値」の3点セットを記載しましょう。
一番やってはいけないのはp値だけを記載して、p<0.05かどうかだけを判定する、ということです。
「平均」「SD」という要約統計量も立派な解析結果ですので、必ず記載するようにしましょう。

SPSSではF検定を実施できない!
先ほどは一律「等分散を仮定しない場合(下に出力されている結果)」で問題ないと申し上げましたが、そうは言ってもまだまだ等分散性の確認を検定で実施している例は多いです。
等分散性の検定といえば、有名なのがF検定ですよね。
なので、SPSSでもF検定の方法を知りたい!と思っているかもしれません。
しかし結論から申し上げると、SPSSではF検定を実施できません!
その代わりに、T検定を実施する方法と同じように出力すると「等分散性のためのLeveneの検定」結果がデフォルトで出てきます。
どうしても等分散性の検定を実施したい場合には、SPSSではF検定ではなくLeveneの検定結果を確認しましょう。
まとめ
今回は、SPSSでT検定を実施しました。
T検定は基本中の基本なので、やり方や結果の解釈を確実にできるようになりましょう。








コメント
コメント一覧 (3件)
[…] […]
[…] >>SPSSでT検定を実施する方法 […]
[…] >>SPSSでT検定を実施する方法 […]